17 Text analysis
With the exception of labels used to represent categorical data, we have focused on numerical data. But in many applications, data starts as text. Well-known examples are spam filtering, cyber-crime prevention, counter-terrorism and sentiment analysis. In all these cases, the raw data is composed of free form text. Our task is to extract insights from these data. In this section, we learn how to generate useful numerical summaries from text data to which we can apply some of the powerful data visualization and analysis techniques we have learned.
17.1 Case study: Trump tweets
During the 2016 US presidential election, then candidate Donald J. Trump used his twitter account as a way to communicate with potential voters. On August 6, 2016, Todd Vaziri tweeted1 about Trump that “Every non-hyperbolic tweet is from iPhone (his staff). Every hyperbolic tweet is from Android (from him).” David Robinson conducted an analysis2 to determine if data supported this assertion. Here, we go through David’s analysis to learn some of the basics of text analysis. To learn more about text analysis in R, we recommend the Text Mining with R book3 by Julia Silge and David Robinson.
We will use the following libraries:
X, formerly known as twitter, provides an API that permits downloading tweets. Brendan Brown runs the trump archive4, which compiles tweet data from Trump’s account. The dslabs package includes tweets from the following range:
range(trump_tweets$created_at)
#> [1] "2009-05-04 13:54:25 EST" "2018-01-01 08:37:52 EST"The data frame includes the the following variables:
names(trump_tweets)
#> [1] "source" "id_str"
#> [3] "text" "created_at"
#> [5] "retweet_count" "in_reply_to_user_id_str"
#> [7] "favorite_count" "is_retweet"The help file ?trump_tweets provides details on what each variable represents. The actual tweets are in the text variable:
and the source variable tells us which device was used to compose and upload each tweet:
We are interested in what happened during the 2016 campaign, so for this analysis we will focus on what was tweeted between the day Trump announced his campaign and election day. We define the following table containing just the tweets from that time period. We remove the Twitter for part of the source, only keep tweets from Android or iPhone, and filter out retweets.
We can now use data visualization to explore the possibility that two different groups were tweeting from these devices. For each tweet, we will extract the hour, Eastern Standard Time (EST), it was tweeted and then compute the proportion of tweets tweeted at each hour for each device:
campaign_tweets |>
mutate(hour = hour(with_tz(created_at, "EST"))) |>
count(source, hour) |>
group_by(source) |>
mutate(percent = n / sum(n)) |>
ungroup() |>
ggplot(aes(hour, percent, color = source)) +
geom_line() +
geom_point() +
scale_y_continuous(labels = percent_format()) +
labs(x = "Hour of day (EST)", y = "% of tweets", color = "")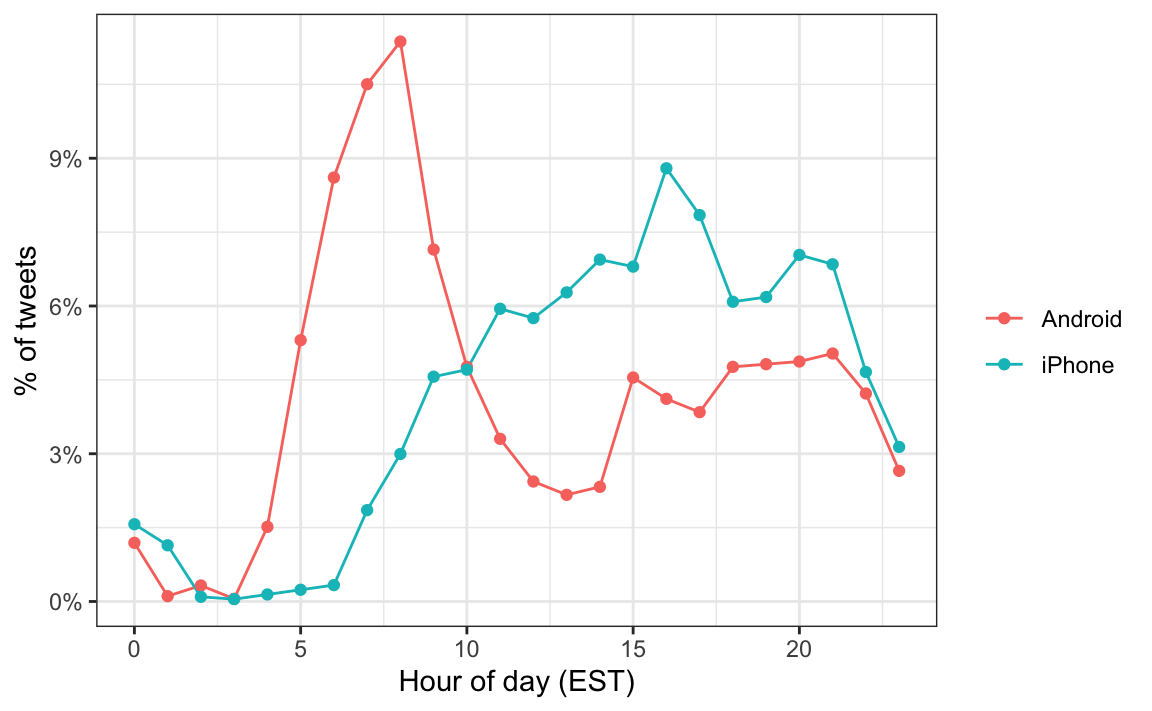
We notice a big peak for the Android in the early hours of the morning, between 6 and 8 AM. There seems to be a clear difference in these patterns. We will therefore assume that two different entities are using these two devices.
We will now study how the text of the tweets differ when we compare Android to iPhone. To do this, we introduce the tidytext package.
17.2 Text as data
The tidytext package helps us convert free form text into a tidy table. Having the data in this format greatly facilitates data visualization and the use of statistical techniques.
The main function needed to achieve this is unnest_tokens. A token refers to a unit that we are considering to be a data point. The most common token will be words, but they can also be single characters, n-grams, sentences, lines, or a pattern defined by a regex. The function will take a vector of strings and extract the tokens so that each one gets a row in the new table. Here is a simple example:
poem <- c("Roses are red,", "Violets are blue,",
"Sugar is sweet,", "And so are you.")
example <- tibble(line = c(1, 2, 3, 4),
text = poem)
example
#> # A tibble: 4 × 2
#> line text
#> <dbl> <chr>
#> 1 1 Roses are red,
#> 2 2 Violets are blue,
#> 3 3 Sugar is sweet,
#> 4 4 And so are you.
example |> unnest_tokens(word, text)
#> # A tibble: 13 × 2
#> line word
#> <dbl> <chr>
#> 1 1 roses
#> 2 1 are
#> 3 1 red
#> 4 2 violets
#> 5 2 are
#> # ℹ 8 more rowsNow let’s look at Trump’s tweets. We will look at tweet number 3008 because it will later permit us to illustrate a couple of points:
i <- 3008
campaign_tweets$text[i] |> str_wrap(width = 65) |> cat()
#> Great to be back in Iowa! #TBT with @JerryJrFalwell joining me in
#> Davenport- this past winter. #MAGA https://t.co/A5IF0QHnic
campaign_tweets[i,] |>
unnest_tokens(word, text) |>
pull(word)
#> [1] "great" "to" "be" "back"
#> [5] "in" "iowa" "tbt" "with"
#> [9] "jerryjrfalwell" "joining" "me" "in"
#> [13] "davenport" "this" "past" "winter"
#> [17] "maga" "https" "t.co" "a5if0qhnic"Note that the function tries to convert tokens into words. A minor adjustment is to remove the links to pictures:
links_to_pics <- "https://t.co/[A-Za-z\\d]+|&"
campaign_tweets[i,] |>
mutate(text = str_remove_all(text, links_to_pics)) |>
unnest_tokens(word, text) |>
pull(word)
#> [1] "great" "to" "be" "back"
#> [5] "in" "iowa" "tbt" "with"
#> [9] "jerryjrfalwell" "joining" "me" "in"
#> [13] "davenport" "this" "past" "winter"
#> [17] "maga"Now we are now ready to extract the words from all our tweets.
tweet_words <- campaign_tweets |>
mutate(text = str_remove_all(text, links_to_pics)) |>
unnest_tokens(word, text)And we can now answer questions such as “what are the most commonly used words?”:
It is not surprising that these are the top words, which are not informative. The tidytext package has a database of these commonly used words, referred to as stop words, in text analysis:
head(stop_words)
#> # A tibble: 6 × 2
#> word lexicon
#> <chr> <chr>
#> 1 a SMART
#> 2 a's SMART
#> 3 able SMART
#> 4 about SMART
#> 5 above SMART
#> # ℹ 1 more rowIf we filter out rows representing stop words with filter(!word %in% stop_words$word):
tweet_words <- campaign_tweets |>
mutate(text = str_remove_all(text, links_to_pics)) |>
unnest_tokens(word, text) |>
filter(!word %in% stop_words$word ) we end up with a much more informative set of top 10 tweeted words:
Some exploration of the resulting words (not shown here) reveals a couple of unwanted characteristics in our tokens. First, some of our tokens are just numbers (years, for example). We want to remove these and we can find them using the regex ^\d+$. Second, some of our tokens come from a quote and they start with '. We want to remove the ' when it is at the start of a word so we will just str_replace. We add these two lines to the code above to generate our final table:
tweet_words <- campaign_tweets |>
mutate(text = str_remove_all(text, links_to_pics)) |>
unnest_tokens(word, text) |>
filter(!word %in% stop_words$word &
!str_detect(word, "^\\d+$")) |>
mutate(word = str_replace(word, "^'", ""))Now that we have all our words in a table, along with information about what device was used to compose the tweet they came from, we can start exploring which words are more common when comparing Android to iPhone.
For each word, we want to know if it is more likely to come from an Android tweet or an iPhone tweet. We therefore compute, for each word, its frequency among words tweeted from Android and iPhone, respectively and then derive the ratio of these proportions (Android proportion divided by iPhone proportion). Because some words are infrequent, we apply the continuity correction described in Section 9.7:
android_vs_iphone <- tweet_words |>
count(word, source) |>
pivot_wider(names_from = "source", values_from = "n", values_fill = 0) |>
mutate(p_a = (Android + 0.5)/(sum(Android) + 0.5),
p_i = (iPhone + 0.5)/(sum(iPhone) + 0.5),
ratio = p_a / p_i)For words appearing at least 100 times in total, here are the highest percent differences for Android
android_vs_iphone |> filter(Android + iPhone >= 100) |> arrange(desc(ratio))
#> # A tibble: 30 × 6
#> word Android iPhone p_a p_i ratio
#> <chr> <int> <int> <dbl> <dbl> <dbl>
#> 1 bad 104 26 0.00648 0.00191 3.39
#> 2 crooked 156 49 0.00971 0.00357 2.72
#> 3 cnn 116 37 0.00723 0.00271 2.67
#> 4 ted 86 28 0.00537 0.00206 2.61
#> 5 interviewed 76 25 0.00475 0.00184 2.58
#> # ℹ 25 more rowsand the top for iPhone:
android_vs_iphone |> filter(Android + iPhone >= 100) |> arrange(ratio)
#> # A tibble: 30 × 6
#> word Android iPhone p_a p_i ratio
#> <chr> <int> <int> <dbl> <dbl> <dbl>
#> 1 makeamericagreatagain 0 298 0.0000310 0.0216 0.00144
#> 2 trump2016 3 412 0.000217 0.0298 0.00729
#> 3 join 1 157 0.0000930 0.0114 0.00818
#> 4 tomorrow 24 101 0.00152 0.00733 0.207
#> 5 vote 46 67 0.00288 0.00487 0.592
#> # ℹ 25 more rowsWe already see somewhat of a pattern in the types of words that are being tweeted more from one device versus the other. However, we are not interested in specific words but rather in the tone. Vaziri’s assertion is that the Android tweets are more hyperbolic. So how can we check this with data? Hyperbolic is a hard sentiment to extract from words as it relies on interpreting phrases. However, words can be associated to more basic sentiment such as anger, fear, joy, and surprise. In the next section, we demonstrate basic sentiment analysis.
17.3 Sentiment analysis
In sentiment analysis, we assign a word to one or more “sentiments”. Although this approach will miss context-dependent sentiments, such as sarcasm, when performed on large numbers of words, summaries can provide insights.
The first step in sentiment analysis is to assign a sentiment to each word. As we demonstrate, the tidytext package includes several maps or lexicons. The textdata package includes several of these lexicons.
The bing lexicon divides words into positive and negative sentiments. We can see this using the tidytext function get_sentiments:
get_sentiments("bing")The AFINN lexicon assigns a score between -5 and 5, with -5 the most negative and 5 the most positive. Note that this lexicon needs to be downloaded the first time you call the function get_sentiment:
get_sentiments("afinn")The nrc lexicon provide several different sentiments. Note that this also has to be downloaded the first time you use it.
get_sentiments("nrc") |> count(sentiment)
#> # A tibble: 10 × 2
#> sentiment n
#> <chr> <int>
#> 1 anger 1245
#> 2 anticipation 837
#> 3 disgust 1056
#> 4 fear 1474
#> 5 joy 687
#> # ℹ 5 more rowsFor our analysis, we are interested in exploring the different sentiments of each tweet so we will use the nrc lexicon:
nrc <- get_sentiments("nrc") |> select(word, sentiment)We can combine the words and sentiments using inner_join, which will only keep words associated with a sentiment. Here are 5 random words extracted from the tweets:
tweet_words |> inner_join(nrc, by = "word", relationship = "many-to-many") |>
select(source, word, sentiment) |>
sample_n(5)
#> # A tibble: 5 × 3
#> source word sentiment
#> <chr> <chr> <chr>
#> 1 Android enjoy joy
#> 2 iPhone terrific sadness
#> 3 iPhone tactics trust
#> 4 Android clue anticipation
#> 5 iPhone change fearrelationship = "many-to-many" is added to address a warning that arises from left_join detecting an “unexpected many-to-many relationship”. However, this behavior is actually expected in this context because many words have multiple sentiments associated with them.
Now we are ready to perform a quantitative analysis comparing Android and iPhone by comparing the sentiments of the tweets posted from each device. Here we could perform a tweet-by-tweet analysis, assigning a sentiment to each tweet. However, this will be challenging since each tweet will have several sentiments attached to it, one for each word appearing in the lexicon. For illustrative purposes, we will perform a much simpler analysis: we will count and compare the frequencies of each sentiment appearing in each device.
sentiment_counts <- tweet_words |>
left_join(nrc, by = "word", relationship = "many-to-many") |>
count(source, sentiment) |>
pivot_wider(names_from = "source", values_from = "n") |>
mutate(sentiment = replace_na(sentiment, replace = "none"))For each sentiment, we calculate its proportion relative to the total responses for Android and iPhone, respectively, and derive the ratio of these proportions (Android proportion divided by iPhone proportion).
sentiment_counts <- sentiment_counts |>
mutate(p_a = Android/sum(Android), p_i = iPhone/sum(iPhone), ratio = p_a/p_i) |>
arrange(desc(ratio))
sentiment_counts
#> # A tibble: 11 × 6
#> sentiment Android iPhone p_a p_i ratio
#> <chr> <int> <int> <dbl> <dbl> <dbl>
#> 1 disgust 639 314 0.0290 0.0178 1.63
#> 2 anger 962 527 0.0437 0.0298 1.47
#> 3 negative 1657 931 0.0753 0.0527 1.43
#> 4 sadness 901 514 0.0409 0.0291 1.41
#> 5 fear 799 486 0.0363 0.0275 1.32
#> # ℹ 6 more rowsSo we do see some differences and the order is interesting: the largest three sentiments are disgust, anger, and negative!
If we are interested in exploring which specific words are driving these differences, we can refer back to our android_vs_iphone object. For each sentiment we show the 10 largest ratios, in either direction. We exclude words appearing less than 10 times total.

This is just a simple example of the many analyses one can perform with tidytext. To learn more, we again recommend the Tidy Text Mining book5.
17.4 Exercises
Project Gutenberg is a digital archive of public domain books. The R package gutenbergr facilitates the importation of these texts into R.
You can install and load by typing:
install.packages("gutenbergr")
library(gutenbergr)You can see the books that are available like this:
gutenberg_metadata1. Use str_detect to find the ID of the novel Pride and Prejudice.
2. We notice that there are several versions. The gutenberg_works() function filters this table to remove replicates and include only English language works. Read the help file and use this function to find the ID for Pride and Prejudice.
3. Use the gutenberg_download function to download the text for Pride and Prejudice. Save it to an object called book.
4. Use the tidytext package to create a tidy table with all the words in the text. Save the table in an object called words
5. We will later make a plot of sentiment versus location in the book. For this, it will be useful to add a column with the word number to the table.
6. Remove the stop words and numbers from the words object. Hint: use the anti_join.
7. Now use the AFINN lexicon to assign a sentiment value to each word.
8. Make a plot of sentiment score versus location in the book and add a smoother.
9. Assume there are 300 words per page. Convert the locations to pages and then compute the average sentiment in each page. Plot that average score by page. Add a smoother that appears to go through data.