Capítulo 3 Conceitos básicos de programação
Ensinamos R pelo fato de ele facilitar significativamente a análise de dados, o tema principal deste livro. Ao programar em R, podemos executar eficientemente a análise exploratória de dados, criar fluxos de análise de dados e preparar a visualização de dados para comunicar resultados. No entanto, R não é apenas um ambiente de análise de dados, mas uma linguagem de programação. Programadores avançados de R podem desenvolver pacotes complexos e até melhorar o R, embora não abordemos estes tópicos neste livro. No entanto, nesta seção, apresentamos três conceitos-chave de programação: expressões condicionais, execução em laço do tipo for e funções. Estes não são apenas os principais componentes da programação avançada, mas, às vezes, são úteis durante a análise de dados. Também observamos que existem várias funções amplamente usadas para programação em R, mas que não discutiremos neste livro. Elas incluem split, cut, do.call e Reduce, bem como o pacote data.table. Vale a pena aprender como usá-las, se você quiser se tornar um programador especialista em R.
3.1 Expressões condicionais
Expressões condicionais são uma das características básicas da programação. Elas são usados para o que é chamado de controle de fluxo. A expressão condicional mais comum é a instrução if-else. Em R, podemos fazer muitas análises de dados sem expressões condicionais. No entanto, eles aparecem ocasionalmente e você precisará delas assim que começar a escrever suas próprias funções e pacotes.
Aqui está um exemplo muito simples que mostra a estrutura geral de uma instrução if-else. A idéia básica é retornar o inverso de a, a menos que a seja 0:
a <- 0
if(a!=0){
print(1/a)
} else{
print("Não há inverso de 0.")
}
#> [1] "Não há inverso de 0."Vejamos outro exemplo usando o conjunto de dados de assassinatos nos EUA:
library(dslabs)
data(murders)
murder_rate <- murders$total/ murders$population*100000Aqui está um exemplo muito simples que nos diz quais estados, se houver, têm uma taxa de homicídios inferior a 0,5 por 100.000 habitantes. As declarações if protegem-nos de situações em que nenhum estado satisfaz a condição.
ind <- which.min(murder_rate)
if(murder_rate[ind] < 0.5){
print(murders$state[ind])
} else{
print("Nenhum estado tem taxa de homicídios abaixo deste nível")
}
#> [1] "Vermont"Se tentarmos novamente com uma taxa de 0,25, obteremos uma resposta diferente:
if(murder_rate[ind] < 0.25){
print(murders$state[ind])
} else{
print("Nenhum estado tem taxa de homicídios abaixo deste nível")
}
#> [1] "Nenhum estado tem taxa de homicídios abaixo deste nível"Uma função relacionada que é muito útil é ifelse. Ela usa três argumentos: um lógico e duas respostas possíveis. Se o lógico for TRUE, retorna o valor no segundo argumento e, se for FALSE, retorna o valor no terceiro argumento. Aqui está um exemplo:
a <- 0
ifelse(a > 0, 1/a, NA)
#> [1] NAEssa função é particularmente útil porque é otimizada para vetores. Ela examina cada entrada do vetor lógico e retorna elementos do vetor fornecido no segundo argumento, se a entrada for TRUE, ou elementos do vetor fornecido no terceiro argumento, se a entrada for FALSE.
a <- c(0, 1, 2, -4, 5)
result <- ifelse(a > 0, 1/a, NA)| a | is_a_positive | answer1 | answer2 | result |
|---|---|---|---|---|
| 0 | FALSE | Inf | NA | NA |
| 1 | TRUE | 1.00 | NA | 1.0 |
| 2 | TRUE | 0.50 | NA | 0.5 |
| -4 | FALSE | -0.25 | NA | NA |
| 5 | TRUE | 0.20 | NA | 0.2 |
Aqui está um exemplo de como essa função pode ser facilmente usada para substituir todos os valores ausentes em um vetor por zeros:
data(na_example)
no_nas <- ifelse(is.na(na_example), 0, na_example)
sum(is.na(no_nas))
#> [1] 0Duas outras funções úteis são any e all. A função any pega um vetor com valores lógicos e retorna TRUE se alguma das entradas for TRUE. A função all pega um vetor de lógicas e retorna TRUE se todas as entradas forem TRUE. Aqui está um exemplo:
z <- c(TRUE, TRUE, FALSE)
any(z)
#> [1] TRUE
all(z)
#> [1] FALSE3.2 Como definir funções
À medida que ganha mais experiência, você observará que realizará as mesmas operações repetidamente. Um exemplo simples é o cálculo de médias. Podemos calcular a média de um vetor x usando funções sum e length: sum(x)/length(x). Como fazemos isso repetidamente, é muito mais eficiente escrever uma função que execute essa operação. Essa operação específica é tão comum que alguém já escreveu a função mean, que está incluída na pacote base do R. No entanto, você encontrará situações em que a função ainda não existe e o R permite que você escreva uma. Uma versão simplificada de uma função que calcula a média pode ser implementada da seguinte maneira:
avg <- function(x){
s <- sum(x)
n <- length(x)
s/n
}Agora avg é uma função que calcula a média:
x <- 1:100
identical(mean(x), avg(x))
#> [1] TRUEObserve que as variáveis definidas em uma função não são gravadas no espaço de trabalho. Então, enquanto usamos s e n quando chamamos (call em inglês) avg, os valores são criados e alterados apenas durante a chamada. Aqui podemos ver um exemplo ilustrativo:
s <- 3
avg(1:10)
#> [1] 5.5
s
#> [1] 3Note como s ainda é 3 depois que executa-se avg.
Em geral, funções são objetos, portanto, atribuímos nomes de variáveis a eles com <-. A função function diz ao R que ele está prestes a definir uma função. A forma geral da definição de uma função é assim:
my_function <- function(VARIABLE_NAME){
perform operations on VARIABLE_NAME and calculate VALUE
VALUE
}As funções que você define podem ter vários argumentos, bem como valores padrão. Por exemplo, podemos definir uma função que calcula a média aritmética ou geométrica, dependendo de uma variável definida pelo usuário como esta:
avg <- function(x, arithmetic = TRUE){
n <- length(x)
ifelse(arithmetic, sum(x)/n, prod(x)^(1/n))
}Aprenderemos mais sobre como criar funções através da experiência, à medida em que avançamos para tarefas mais complexas.
3.3 Namespaces
À medida em que você se torna mais experiente em R, é mais provável que você precise carregar vários pacotes para algumas de suas análises. Quando começar a fazer isso, você observará que é possível que dois pacotes diferentes utilizem o mesmo nome para duas funções distintas. E muitas vezes essas funções fazem coisas completamente diferentes. Na verdade, você já encontrou este problema, visto que ambos os pacotes stats e dplyr definem uma função filter. Existem outros cinco exemplos em dplyr. Sabemos disso porque, quando carregamos dplyr pela primeira vez, vemos a seguinte mensagem:
The following objects are masked from ‘package:stats’:
filter, lag
The following objects are masked from ‘package:base’:
intersect, setdiff, setequal, unionEntão, o que R faz quando digitamos filter? Ele usa a função definida no dplyr ou a do stats? Por nossa experiência anterior, sabemos que ele usa dplyr. Mas e se quisermos usar a do stats?
Essas funções vivem em diferentes namespaces. O R seguirá uma determinada ordem ao procurar uma função nesses namespaces. Você pode ver a ordem digitando:
search()A primeira entrada nesta lista é o ambiente global que inclui todos os objetos que você define.
E se quisermos usar o filter definido no pacote stats ao invés daquela definida no dplyr, mesmo com o dplyr aparecendo primeiro na lista de pesquisa? Você pode forçar o uso de um namespace específico usando dois pontos duplos ( ::), assim:
stats::filterSe quisermos ter certeza absoluta de que utilizaremos o filter do dplyr, podemos usar:
dplyr::filterLembre-se de que, se quisermos usar uma função de um pacote sem carregá-lo inteiramente, também podemos usar dois pontos duplos.
Para obter mais informações sobre esse tópico mais avançado, recomendamos o livro R packages16.
3.4 Laços do tipo for
A fórmula para a soma da série \(1+2+\dots+n\) é \(n(n+1)/2\). E se não tivéssemos certeza de que essa era a função correta? Como poderíamos verificar? Usando o que aprendemos sobre funções, podemos criar uma que calcule \(S_n\):
compute_s_n <- function(n){
x <- 1:n
sum(x)
}Como podemos calcular \(S_n\) para vários valores de \(n\), digamos \(n=1,\dots,25\)? Escrevemos 25 linhas de código executando compute_s_n? Não. É para isso que serve a execução em laço (loop). Nesse caso, a mesma tarefa é realizada repetidamente, e a única coisa muda é o valor de \(n\). Os laços do tipo for permitem-nos definir o intervalo de mudança da nossa variável (no nosso exemplo \(n=1,\dots,10\)), alterar o valor e reavaliar a expressão.
Talvez o exemplo mais simples de um loop for seja esse código inútil:
for(i in 1:5){
print(i)
}
#> [1] 1
#> [1] 2
#> [1] 3
#> [1] 4
#> [1] 5Aqui está o laço do tipo for para o nosso exemplo \(S_n\):
m <- 25
s_n <- vector(length = m) # create an empty vector
for(n in 1:m){
s_n[n] <- compute_s_n(n)
}Em cada iteração \(n=1\), \(n=2\), etc …, calculamos \(S_n\) e mantemos na entrada \(n\) do s_n.
Agora podemos criar um gráfico para procurar um padrão:
n <- 1:m
plot(n, s_n)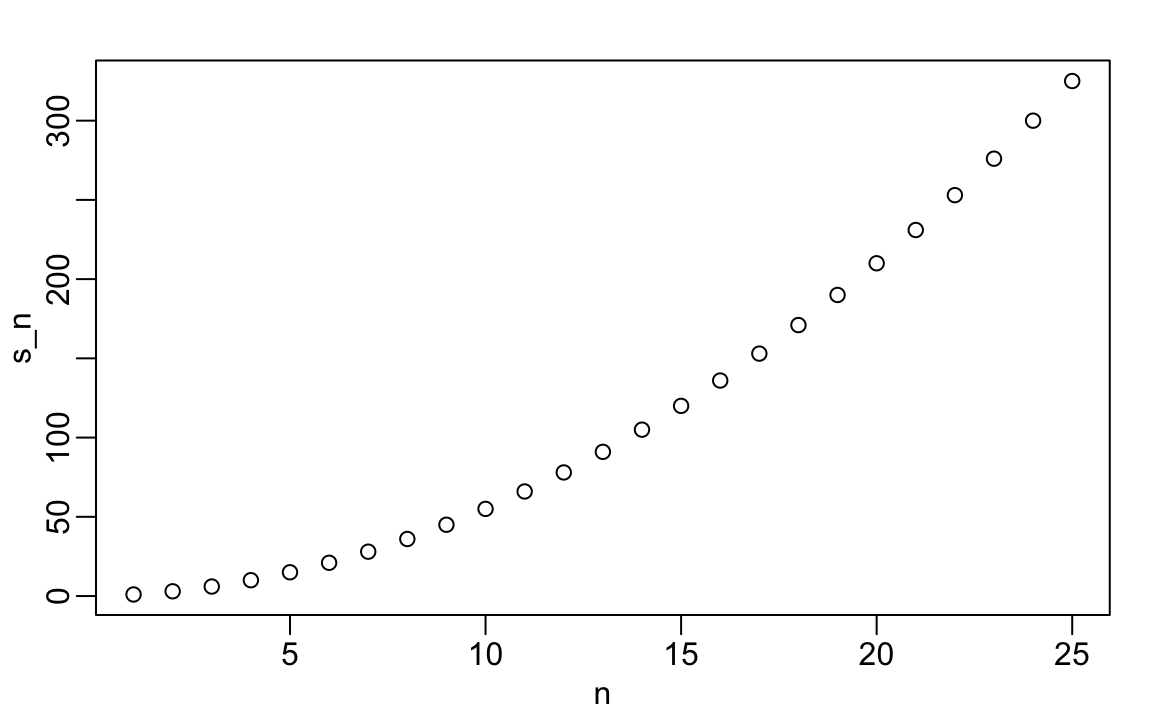
Se você percebeu que parece quadrático, está no caminho certo porque a fórmula é \(n(n+1)/2\).
3.5 Vectorização e funcionais
Embora os laços do tipo for sejam um conceito importante para entender, eles não são muito usados em R. À medida em que você aprende mais R, descobre que vetorização é preferível aos laços/loops, pois resulta em um código mais curto e claro. Já vimos exemplos na seção de aritmética vetorial. Uma função vetorizada é uma função que aplicará a mesma operação a cada um dos seus elementos.
x <- 1:10
sqrt(x)
#> [1] 1.00 1.41 1.73 2.00 2.24 2.45 2.65 2.83 3.00 3.16
y <- 1:10
x*y
#> [1] 1 4 9 16 25 36 49 64 81 100Para fazer esse cálculo, não precisamos de loops de for. No entanto, nem todas as funções funcionam dessa maneira. Por exemplo, a função que acabamos de escrever, compute_s_n, não é vetorizada, pois espera um escalar. Por exemplo, o código abaixo não executa a função para todas as entradas de n:
n <- 1:25
compute_s_n(n)Os funcionais são funções que nos ajudam a aplicar a mesma função a cada entrada em um vetor, matriz, data.frame ou lista. Aqui, abordamos o funcional que opera em vetores numéricos, lógicos e de caracteres: sapply.
A função sapply nos permite executar operações na base de elemento a elemento (element-wise, em inglês) em qualquer função. Aqui podemos ver como funciona:
x <- 1:10
sapply(x, sqrt)
#> [1] 1.00 1.41 1.73 2.00 2.24 2.45 2.65 2.83 3.00 3.16Cada elemento de x é passado para a função sqrt e retorna o resultado. Esses resultados são concatenados. Nesse caso, o resultado é um vetor do mesmo comprimento que o original, x. Isso implica que o loop for acima pode ser escrito da seguinte maneira:
n <- 1:25
s_n <- sapply(n, compute_s_n)Outros funcionais são apply, lapply, tapply, mapply, vapply e replicate. Utilizamos principalmente sapply, apply e replicate neste livro, mas recomendamos os demais sejam estudados, pois podem ser muito úteis.
3.6 Exercícios
1. O que essa expressão condicional retornará?
x <- c(1,2,-3,4)
if(all(x>0)){
print("All Postives")
} else{
print("Not all positives")
}2. Qual das seguintes expressões é sempre FALSE quando pelo menos uma entrada de um vetor lógico x é TRUE?
all(x)any(x)any(!x)all(!x)
3. A função nchar informa quantos caracteres um vetor de caracteres possui. Escreva uma linha de código que atribua o objeto new_names a abreviação de estado quando o nome do estado tiver mais de 8 caracteres.
4. Crie uma função sum_n que, por qualquer valor, digamos \(n\), calcule a soma dos números inteiros de 1 a n (inclusive). Use a função para determinar a soma dos números inteiros de 1 a 5.000.
5. Crie uma função altman_plot que possua dois argumentos, x e y, e faça um gráfico da diferença em relação à soma.
6. Depois de executar o código a seguir, qual é o valor de x?
x <- 3
my_func <- function(y){
x <- 5
y + 5
}7. Escreva uma função compute_s_n que, para qualquer \(n\), calcule a soma \(S_n = 1^2 + 2^2 + 3^2 + \dots n^2\). Qual é o valor da soma quando \(n = 10\)?
8. Definir um vetor numérico vazio, s_n, de tamanho 25, usando s_n <- vector("numeric", 25) e armazene os resultados de \(S_1, S_2, \dots S_{25}\), usando um laço do tipo for.
9. Repita o Exercício 8, mas, desta vez, use sapply.
10. Repita o Exercício 8, mas, desta vez, use map_dbl.
11. Apresente um gráfico de \(S_n\) versus \(n\), para \(n=1,\dots,25\).
12. Confirme que a fórmula para esta soma é \(S_n= n(n+1)(2n+1)/6\).