Capítulo 2 R básico
Neste livro, usaremos o ambiente de software do R para todas as nossas análises. Você aprenderá técnicas de análise de dados e R simultaneamente. Portanto, para continuar, você necessitará de acesso ao R. Também recomendamos o uso de um ambiente de desenvolvimento integrado (no inglês Integrated Development Environment ou, simplesmente, IDE), como o RStudio, para salvar seu trabalho. Observe que é comum que um curso ou workshop ofereça acesso a um ambiente R e um IDE por meio de um navegador da web, como faz o RStudio cloud12. Se você tiver acesso a tal recurso, não será necessário instalar o R ou o RStudio. Entretanto, se você pretende se tornar um analista de dados especializado, recomendamos fortemente que instale essas ferramentas em seu computador13. O R e o RStudio são gratuitos e estão disponíveis online.
2.1 Estudo de caso: assassinatos por armas nos EUA
Imagine que você viva na Europa e receba uma oferta de emprego em uma empresa americana com filiais em vários estados. É um ótimo trabalho, mas manchetes como ** Taxa de homicídio por arma de fogo nos Estados Unidos é mais alta do que em outros países desenvolvidos **14 têm preocupado você. Gráficos como este podem preocupá-lo ainda mais:
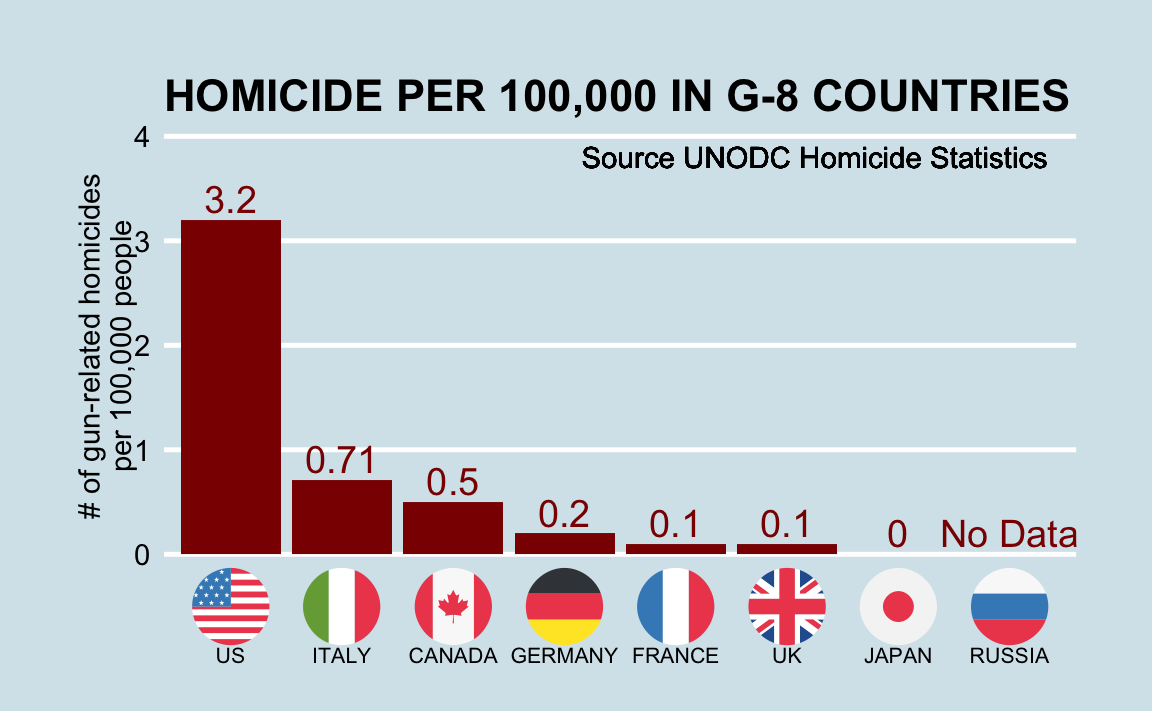
Mas então você se lembra que os Estados Unidos são um país grande e diversificado, com 50 estados muito distintos, além do Distrito de Columbia ou simplesmente DC (equivalente a um distrito federal).
A Califórnia, por exemplo, tem uma população maior que o Canadá. Além disso, 20 estados dos EUA têm populações maiores que a Noruega. Em alguns aspectos, a variabilidade entre os estados dos EUA é semelhante à variabilidade entre países da Europa. Além disso, embora não esteja incluído nas tabelas acima, as taxas de homicídio na Lituânia, Ucrânia e Rússia são superiores a quatro por 100.000. Então, talvez as notícias que o preocupam sejam superficiais demais. Você tem opções de onde pode morar e quer determinar a segurança de cada estado em particular. Podemos ter uma percepão geral ao examinar dados relacionados a homicídios por armas de fogo nos EUA no ano de 2010 usando R.
Antes de começarmos o nosso exemplo, precisamos discutir a logística e alguns dos componentes necessários para obter habilidades mais avançadas de R. Esteja ciente de que a utilidade de alguns desses componentes nem sempre será imediatamente óbvia, entretanto, mais adiante neste livro, você apreciará dominar essas habilidades.
2.2 Os princípios básicos
Antes de começarmos com o conjunto de dados motivadores, precisamos revisar o básico de R.
2.2.1 Objetos
Suponha que alguns alunos do ensino médio nos solicitem ajuda para resolver várias equações quadráticas da forma \(ax^2+bx+c = 0\). A fórmula quadrática nos oferece as soluções:
\[ \frac{-b - \sqrt{b^2 - 4ac}}{2a}\,\, \mbox{ e } \frac{-b + \sqrt{b^2 - 4ac}}{2a} \] que, é claro, mudam dependendo dos valores de \(a\), \(b\) e \(c\). Uma vantagem das linguagens de programação é que podemos definir variáveis e escrever expressões com elas, semelhante à maneira como fazemos isso na matemática, mas obter uma solução numérica. Escreveremos um código geral para a equação quadrática abaixo, mas se formos solicitados a resolver \(x^2 + x -1 = 0\), então definimos:
a <- 1
b <- 1
c <- -1que armazena os valores para uso posterior. Nós usamos <- para atribuir valores a variáveis.
Também podemos atribuir valores usando = ao invés de <-, mas recomendamos não usar = para evitar confusão.
Copie e cole o código acima no seu console para definir as três variáveis. Observe que R não imprime nada quando fazemos essa atribuição. Isso significa que os objetos foram definidos com sucesso. Caso tivesse cometido algum erro, você teria recebido uma mensagem de erro.
Para ver o valor armazenado em uma variável, simplesmente pedimos que R avalie a e isso mostra o valor armazenado:
a
#> [1] 1Uma maneira mais explícita de pedir ao R para mostrar o valor armazenado em a é usar print desta forma:
print(a)
#> [1] 1Usamos o termo object (objeto) para descrever coisas armazenadas em R. Variáveis são exemplos, mas objetos também podem ser entidades mais complicadas, tais como funções, que serão descritas mais adiante.
2.2.2 A área de trabalho (workspace)
Conforme definimos os objetos no console, estamos fazendo alterações na área de trabalho (workspace em inglês ou ainda espaço de trabalho). Você pode ver todas as variáveis salvas no sua área de trabalho digitando:
ls()
#> [1] "a" "b" "c" "dat" "img_path" "murders"No RStudio, a guia Environment mostra os valores:
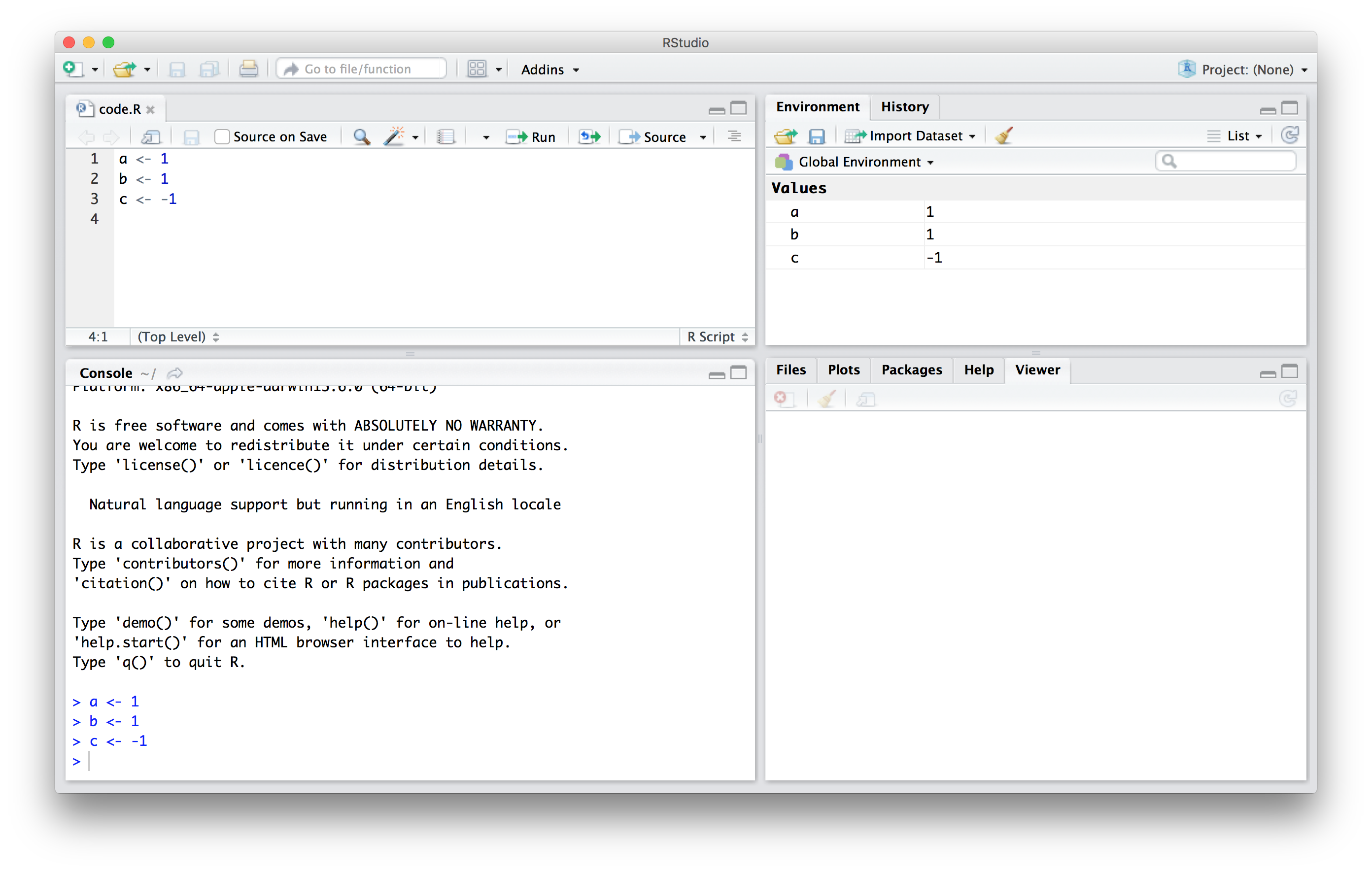
Devemos ver a, b e c. Se tentar recuperar o valor de uma variável que não está em sua área de trabalho, você receberá uma mensagem de erro. Por exemplo, se você escrever x, verá a seguinte mensagem: Error: object 'x' not found (Erro: objeto ‘x’ não encontrado).
Agora, como esses valores são armazenados em variáveis, para resolver nossa equação, usamos a fórmula quadrática:
(-b + sqrt(b^2 - 4*a*c) )/ ( 2*a )
#> [1] 0.618
(-b - sqrt(b^2 - 4*a*c) )/ ( 2*a )
#> [1] -1.622.2.3 Funções
Uma vez definidas as variáveis, o processo de análise de dados geralmente pode ser descrito como uma série de funções aplicadas aos dados. R inclui diversas funções predefinidas e a maioria dos conjuntos de análise que construímos fazem uso extensivo delas.
Nós já usamos as funções install.packages, library e ls. Também usamos a função sqrt para resolver a equação quadrática acima. Existem muitas funções predefinidas e ainda mais podem ser adicionadas através de pacotes. Essas funções não aparecem na área de trabalho porque não foi você quem as definiu, mas elas estão disponíveis para uso imediato.
Em geral, precisamos usar parênteses para chamar uma função. Se você escrever ls, a função não é executada e, em vez disso, R mostra o código que a define. Se você escrever ls(), a função é executada e, como já mostrado, listamos os objetos na área de trabalho.
Diferente de ls, a maioria das funções requer um ou mais argumentos. Abaixo está um exemplo de como atribuímos um objeto como argumento da função log. Lembre-se de que anteriormente definimos a como 1:
log(8)
#> [1] 2.08
log(a)
#> [1] 0Você pode descobrir o que a função espera e o que faz, revendo os muito úteis manuais incluídos no R. Você pode obter ajuda usando a função help assim:
help("log")Para a maioria das funções, também podemos usar esta abreviação:
?logA página de ajuda mostrará quais argumentos a função está esperando. Por exemplo, log precisa de um valor x e uma base para executar. Entretanto, alguns argumentos são obrigatórios e outros são opcionais. Você pode determinar quais argumentos são opcionais observando no documento de ajuda quais padrões são atribuídos com =. Definir tais argumentos é opcional. Por exemplo, a base da função log por padrão é base = exp(1) fazendo log o logaritmo natural padrão.
Para dar uma olhada rápida nos argumentos sem abrir o sistema de ajuda, você pode escrever:
args(log)
#> function (x, base = exp(1))
#> NULLVocê pode alterar os valores padrão simplesmente atribuindo outro objeto:
log(8, base = 2)
#> [1] 3Lembre-se de que não é necessário atribuir o argumento x desta forma:
log(x = 8, base = 2)
#> [1] 3O código acima funciona, mas também podemos economizar um pouco de digitação: se o nome do argumento não for especificado, R assume que você está inserindo argumentos na ordem em que são exibidos na página de ajuda ou nos args. Portanto, ao não usar os nomes, R assume que os argumentos são x seguido pela base:
log(8,2)
#> [1] 3Se os nomes dos argumentos forem usados, então podemos incluí-los em qualquer ordem:
log(base = 2, x = 8)
#> [1] 3Para especificar argumentos, devemos usar = e não <-.
Existem algumas exceções à regra de que funções precisam que parênteses para serem executadas. Entre essas exceções, os mais utilizados são os operadores aritméticos e relacionais. Por exemplo:
2^3
#> [1] 8Você pode ver os operadores aritméticos digitando:
help("+")ou
?"+"e os operadores relacionais ao escrever:
help(">")ou
?">"2.2.4 Outros objetos pré-construídos
Existem diversos conjuntos de dados (datasets) incluídos para os usuários praticarem e testarem funções. Você pode ver todos os datasets disponíveis digitando:
data()Isso mostra o nome do objeto para esses datasets. Esses conjuntos de dados são objetos que podem ser usados simplesmente digitando seu nome. Por exemplo, se você digitar:
co2R mostrará os dados da concentração atmosférica de CO2 de Mauna Loa.
Outros objetos pré-construídos (prebuilt) são as constantes matemáticas, como a constante \(\pi\) e \(\infty\):
pi
#> [1] 3.14
Inf+1
#> [1] Inf2.2.5 Nomes de variáveis
Anteriormente, usamos as letras a, b e c como nomes de variáveis, mas nomes de variáveis podem ser quase qualquer coisa. Algumas regras básicas em R definem apenas que os nomes de variáveis devem começar com uma letra, não podem conter espaços e não devem ser variáveis predefinidas em R. Por exemplo, não nomeie uma de suas variáveis install.packages escrevendo algo como: install.packages <- 2.
Uma boa convenção a seguir é usar palavras significativas que descrevam o que é armazenado, use apenas letras minúsculas e sublinhados como substitutos de espaços. Para equações quadráticas, podemos usar algo como:
solucao_1 <- (-b + sqrt(b^2 - 4*a*c))/ (2*a)
solucao_2 <- (-b - sqrt(b^2 - 4*a*c))/ (2*a)Para obter mais dicas, recomendamos estudar o guia de estilo de Hadley Wickham15.
2.2.6 Como salvar sua área de trabalho
Valores permanecem na área de trabalho até você encerrar a sessão ou excluí-los com a função rm. Mas as áreas de trabalho também podem ser salvas para uso posterior. De fato, ao sair do R, o programa pergunta se você deseja salvar seu workspace. Se você salvá-lo, na próxima vez que iniciar o R, o programa restaurará a área de trabalho.
Não recomendamos salvar a área de trabalho dessa maneira, porque, à medida que você começa a trabalhar em projetos diferentes, se tornará mais difícil acompanhar o que está salvo. Em vez disso, recomendamos que você atribua à área de trabalho um nome específico. Você pode fazer isso usando as funções save ou save.image. Para carregar, use a função load. Ao salvar um workspace, recomendamos os sufixos rda ou RData. No RStudio, você também pode fazer isso navegando até a guia Session e escolhendo a opção Save Workspace as (salvar área de trabalho como). Você pode carregá-los mais tarde usando as opções Load Workspace na mesma guia. Para saber mais, leia as páginas de ajuda de save, save.image e load.
2.2.7 Fundamentando o uso de scripts
Para resolver outra equação como \(3x^2 + 2x -1\), podemos copiar e colar o código acima, redefinir as variáveis e recalcular a solução:
a <- 3
b <- 2
c <- -1
(-b + sqrt(b^2 - 4*a*c))/ (2*a)
(-b - sqrt(b^2 - 4*a*c))/ (2*a)Ao criar e salvar um script com o código acima, não precisaríamos redigitar tudo novamente e, em vez disso, simplesmente alterar os nomes das variáveis. Tente escrever o script acima em um editor e observe como é fácil alterar variáveis e obter uma resposta.
2.2.8 Como comentar seu código
Se uma linha de código R começar com o símbolo #, ela não é executada. Podemos usar isso para escrever lembretes sobre por que escrevemos um código específico. Por exemplo, no script acima, poderíamos adicionar:
## Código para calcular a solução de uma equação quadrática de forma ax^2 + bx + c
## define as variáveis
a <- 3
b <- 2
c <- -1
## agora, calcule a solução
(-b + sqrt(b^2 - 4*a*c))/ (2*a)
(-b - sqrt(b^2 - 4*a*c))/ (2*a)2.3 Exercícios
1. Qual é a soma dos 100 primeiros números inteiros positivos? A fórmula para a soma dos números inteiros de \(1\) a \(n\) é \(n(n+1)/2\). Defina \(n=100\) e então use R para calcular a soma de \(1\) a \(100\) usando a fórmula. Qual é a soma?
2. Agora use a mesma fórmula para calcular a soma dos números inteiros de 1 a 1000.
3. Observe o resultado ao digitar o seguinte código em R:
n <- 1000
x <- seq(1, n)
sum(x)Com base no resultado, o que você acha que as funções fazem seq e sum? Você pode usar a função help.
sumcria uma lista de números eseqos soma.seqcria uma lista de números esumos soma.seqcria uma lista aleatória esumcalcula a soma de 1 a 1000.sumsempre retorna o mesmo número.
4. Em matemática e programação, dizemos que executamos uma função quando substituímos o argumento por um determinado número. Então, se digitarmos sqrt(4), executamos a função sqrt. Em R, você pode executar uma função dentro de outra função. As execuções acontecem de dentro para fora. Escreva uma linha de código para calcular o logaritmo, base 10, da raiz quadrada de 100.
5. Qual das seguintes opções sempre retornará o valor numérico armazenado em x? Você pode testar os exemplos abaixo ou usar o sistema de ajuda, se desejar.
log(10^x)log10(x^10)log(exp(x))exp(log(x, base = 2))
2.4 Tipos de dados
Variáveis em R podem ser de tipos diferentes. Por exemplo, precisamos distinguir números de sequências de caracteres, e tabelas de simples listas de números. A função class nos ajuda a determinar que tipo de objeto temos:
a <- 2
class(a)
#> [1] "numeric"Para trabalhar com eficiência no R, é importante aprender os diferentes tipos de variáveis e o que podemos fazer com elas.
2.4.1 Data frames
Até agora, as variáveis que definimos são apenas numéricas. Isso não é muito útil para armazenar dados. A maneira mais comum de armazenar um conjunto de dados em R é usar um data frame. Conceitualmente, podemos pensar em um data frame como uma tabela com linhas que representam observações e com colunas que representam as diferentes variáveis coletadas para cada observação. Data frames são particularmente úteis para datasets pois permitem combinar diferentes tipos de dados em um único objeto.
Uma grande proporção dos desafios da análise de dados começa com os dados armazenados em um data frame. Por exemplo, armazenamos os dados do nosso exemplo motivador em um data frame. Você pode acessar esse dataset carregando a biblioteca dslabs e, em seguida, usando a função data carregar o dataset murders :
library(dslabs)
data(murders)Para verificar se esse objeto é de fato um data frame, digitamos:
class(murders)
#> [1] "data.frame"2.4.2 Examinando um objeto
A função str é útil para obter mais informações sobre a estrutura de um objeto:
str(murders)
#> 'data.frame': 51 obs. of 5 variables:
#> $ state : chr "Alabama" "Alaska" "Arizona" "Arkansas" ...
#> $ abb : chr "AL" "AK" "AZ" "AR" ...
#> $ region : Factor w/ 4 levels "Northeast","South",..: 2 4 4 2 4 4 1 2 2
#> 2 ...
#> $ population: num 4779736 710231 6392017 2915918 37253956 ...
#> $ total : num 135 19 232 93 1257 ...Isso nos diz muito mais sobre o objeto. Vemos que a tabela possui 51 linhas (50 estados mais DC) e cinco variáveis. Podemos exibir as seis primeiras linhas usando a função head:
head(murders)
#> state abb region population total
#> 1 Alabama AL South 4779736 135
#> 2 Alaska AK West 710231 19
#> 3 Arizona AZ West 6392017 232
#> 4 Arkansas AR South 2915918 93
#> 5 California CA West 37253956 1257
#> 6 Colorado CO West 5029196 65Nesse conjunto de dados, cada estado é considerado uma observação e cinco variáveis são reportadas para cada estado.
Antes de irmos além em responder à nossa pergunta original sobre os diferentes estados, vamos revisar um pouco mais sobre os componentes deste objeto.
2.4.3 O operador de acesso: $
Para nossa análise, precisaremos acessar as diferentes variáveis representadas pelas colunas incluídas neste data frame. Para fazer isso, usamos o operador de acesso $ da seguinte maneira:
murders$population
#> [1] 4779736 710231 6392017 2915918 37253956 5029196 3574097
#> [8] 897934 601723 19687653 9920000 1360301 1567582 12830632
#> [15] 6483802 3046355 2853118 4339367 4533372 1328361 5773552
#> [22] 6547629 9883640 5303925 2967297 5988927 989415 1826341
#> [29] 2700551 1316470 8791894 2059179 19378102 9535483 672591
#> [36] 11536504 3751351 3831074 12702379 1052567 4625364 814180
#> [43] 6346105 25145561 2763885 625741 8001024 6724540 1852994
#> [50] 5686986 563626Mas como sabíamos que havia uma coluna denominada population? Anteriormente, ao aplicar a função str ao objeto murders, descobrimos os nomes de cada uma das cinco variáveis armazenadas nesta tabela. Podemos acessar rapidamente nomes de variáveis usando:
names(murders)
#> [1] "state" "abb" "region" "population" "total"É importante saber que a ordem das entradas em murders$population preserva a ordem das linhas em nossa tabela de dados. Isso nos permitirá manipular uma variável com base nos resultados de outra. Por exemplo, podemos classificar os nomes dos estados de acordo com o número de assassinatos.
Dica: R vem com uma funcionalidade de preenchimento automático muito boa, que evita o trabalho de digitar todos os nomes. Escreva murders$p e pressione a tecla tab no teclado. Essa funcionalidade e muitos outros recursos úteis de preenchimento automático estão disponíveis no RStudio.
2.4.4 Vetores: numéricos, caracteres e lógicos
O objeto murders$population não é um número, mas vários. Chamamos esse tipo de objeto de vectors (vetores). Um número único é tecnicamente um vetor de comprimento 1, mas em geral usamos o termo vetores para se referir a objetos com várias entradas. A função length informa quantas entradas existem no vetor:
pop <- murders$population
length(pop)
#> [1] 51Esse vetor específico é denominado numérico (numeric), pois os tamanhos da população são números:
class(pop)
#> [1] "numeric"Em um vetor numérico, cada entrada deve ser um número.
Para armazenar uma cadeia de caracteres (strings), os vetores também podem ser da classe character. Por exemplo, os nomes dos estados são caracteres:
class(murders$state)
#> [1] "character"Assim como nos vetores numéricos, todas as entradas em um vetor de caracteres devem ter um caractere.
Outro tipo importante de vetores são os vetores lógicos (logical). Estes devem ser TRUE (verdadeiro) ou FALSE (falso).
z <- 3 == 2
z
#> [1] FALSE
class(z)
#> [1] "logical"Aqui o == é um operador relacional que pergunta se 3 é igual a 2. Em R, use apenas um = atribuir uma variável, mas se usar duas == então você estará avaliando se os objetos são iguais.
Você pode ver outros operadores relacionais escrevendo:
?ComparisonNas próximas seções, você verá como os operadores relacionais podem ser úteis.
Discutiremos as características mais importantes dos vetores após os exercícios a seguir.
Avançado: matematicamente, os valores em pop são números inteiros e há uma classe para números inteiros (integer) em R. No entanto, por padrão, os números recebem a classe numérica (numeric) mesmo quando são números inteiros redondos. Por exemplo, class(1) retorna numeric. Você pode convertê-lo para classe integer com a função as.integer() ou adicionando um L assim: 1L. Observe a classe escrevendo: class(1L)
2.4.5 Fatores (factors)
No dataset murders, nós poderíamos esperar que a região também fosse um vetor de caracteres. Entretanto, não é:
class(murders$region)
#> [1] "factor"É um fator. Fatores são úteis para armazenar dados categóricos. Podemos ver que existem apenas quatro regiões ao usar a função levels:
levels(murders$region)
#> [1] "Northeast" "South" "North Central" "West"Em segundo plano, R armazena esses levels (níveis) como números inteiros (integers) e mantém um mapa para acompanhar os rótulos. Isso é mais eficiente quando se considera o uso de memória do que armazenar todos os caracteres.
Observe que os níveis têm uma ordem que é diferente da ordem de aparecimento em um objeto factor. Em R, por padrão, os níveis são organizados em ordem alfabética. No entanto, geralmente queremos que os níveis sigam uma ordem diferente. Você pode especificar a ordem através do argumento levels quando criar o fator com a função factor. Por exemplo, no conjunto de dados de assassinatos, as regiões são ordenadas de leste a oeste. A função reorder permite alterar a ordem dos níveis de uma variável factor baseado em um resumo calculado em um vetor numérico. Agora, demonstraremos isso usando um simples exemplo. Veremos exemplos mais avançados na seção de Visualização de Dados do livro.
Vamos supor que desejemos que os níveis da região sejam ordenados de acordo com o número total de assassinatos, e não por ordem alfabética. Se houver valores associados a cada nível, podemos usar reorder para determinar a ordem. O código a seguir pega a soma do total de assassinatos em cada região e reordena o fator de acordo com essas somas.
region <- murders$region
value <- murders$total
region <- reorder(region, value, FUN = sum)
levels(region)
#> [1] "Northeast" "North Central" "West" "South"A nova ordem é consistente com o fato de que há menos assassinatos no nordeste e mais no sul.
Aviso: os fatores podem causar confusão, pois às vezes eles se comportam como caracteres e às vezes não. Como resultado, esse tipo de dados são uma fonte comum de erros.
2.4.6 Listas
Data frames são um caso especial de listas (do inglês lists). Abordaremos as listas com mais detalhes posteriormente, mas saiba que elas são úteis porque podem armazenar qualquer combinação de diferentes tipos de dados. Abaixo, apresentamos um exemplo de uma lista que criamos para você:
record
#> $name
#> [1] "João das Couves"
#>
#> $student_id
#> [1] 1234
#>
#> $grades
#> [1] 95 82 91 97 93
#>
#> $final_grade
#> [1] "A"
class(record)
#> [1] "list"Assim como em data frames, você pode extrair os componentes de uma lista com o operador de acesso: $. De fato, data frames são um tipo de lista.
record$student_id
#> [1] 1234Também podemos usar colchetes duplos ( [[) assim:
record[["student_id"]]
#> [1] 1234Você deve se acostumar com o fato de que geralmente existem várias maneiras em R de fazer a mesma coisa, como acessar entradas.
Você também pode encontrar listas sem nomes de variáveis:
record2
#> [[1]]
#> [1] "João das Couves"
#>
#> [[2]]
#> [1] 1234Se uma lista não tiver nomes, você não pode extrair os elementos com $, mas você pode ainda usar o método de colchete. Em vez de fornecer o nome da variável, você pode fornecer o índice da lista da seguinte maneira:
record2[[1]]
#> [1] "João das Couves"Não usaremos listas até mais tarde, mas você pode encontrar uma em suas próprias explorações de R. É por isso que mostramos alguns conceitos básicos aqui.
2.4.7 Matrizes
Matrizes são outro tipo comum de objeto em R. Matrizes são semelhantes a data frames, pois são bidimensionais: possuem linhas e colunas. No entanto, como vetores numéricos, caracteres e lógicos, as entradas nas matrizes devem ser do mesmo tipo. Por esse motivo, data frames são muito mais úteis para armazenar dados, pois permitem armazenar caracteres, fatores e números.
Entretanto, as matrizes têm uma grande vantagem sobre os data frames: podemos executar operações de álgebra matricial, uma poderosa técnica matemática. Não descrevemos essas operações neste livro, mas muito do que acontece em segundo plano quando você executa uma análise de dados envolve matrizes. Abordamos matrizes em mais detalhes nos próximos capítulos. Entretanto, as discutiremos brevemente aqui, uma vez que algumas das funções que aprenderemos retornam matrizes.
Podemos definir uma matriz usando a função matrix. Precisamos especificar o número de linhas e colunas:
mat <- matrix(1:12, 4, 3)
mat
#> [,1] [,2] [,3]
#> [1,] 1 5 9
#> [2,] 2 6 10
#> [3,] 3 7 11
#> [4,] 4 8 12Você pode acessar entradas específicas em uma matriz usando colchetes ([). Por exemplo, se você deseja o valor armazenado na segunda linha, terceira coluna, use:
mat[2, 3]
#> [1] 10Se você deseja todos os itens da segunda linha, deixe o valor da coluna vazio:
mat[2, ]
#> [1] 2 6 10Observe que isso retorna um vetor e não uma matriz.
Da mesma forma, se você quiser a terceira coluna inteira, deixe o valor da linha vazio:
mat[, 3]
#> [1] 9 10 11 12Este também é um vetor, não uma matriz.
Você pode acessar mais de uma coluna ou mais de uma linha se desejar. Isso lhe dará uma nova matriz.
mat[, 2:3]
#> [,1] [,2]
#> [1,] 5 9
#> [2,] 6 10
#> [3,] 7 11
#> [4,] 8 12Você pode criar subconjuntos de linhas e colunas:
mat[1:2, 2:3]
#> [,1] [,2]
#> [1,] 5 9
#> [2,] 6 10Podemos converter as matrizes em data frames usando a função as.data.frame:
as.data.frame(mat)
#> V1 V2 V3
#> 1 1 5 9
#> 2 2 6 10
#> 3 3 7 11
#> 4 4 8 12Também podemos usar colchetes individuais ([) para acessar as linhas e colunas de um data frame:
data("murders")
murders[25, 1]
#> [1] "Mississippi"
murders[2:3, ]
#> state abb region population total
#> 2 Alaska AK West 710231 19
#> 3 Arizona AZ West 6392017 2322.5 Exercícios
1. Carregue o conjunto de dados de assassinatos nos EUA.
library(dslabs)
data(murders)Use a função str para examinar a estrutura do objeto murders. Qual das opções a seguir descreve melhor as variáveis representadas nesse data frame?
- Os 51 estados.
- Taxas de assassinato para todos os 50 estados e DC.
- O nome do estado, a abreviação do nome do estado, região e população do estado e o número total de assassinatos em 2010 no estado.
strnão exibe informações relevantes.
2. Quais são os nomes das colunas usadas pelo data frame para essas cinco variáveis?
3. Use o operador de acesso $ para extrair as abreviações dos estados e atribuí-las ao objeto a. Qual é a classe desse objeto?
4. Agora use os colchetes para extrair as abreviações dos estados e atribuí-las ao objeto b. Use a função identical para determinar se a e b são iguais.
5. Vimos que a coluna region armazena um fator. Você pode verificar isso digitando:
class(murders$region)Com uma linha de código, use as funções levels e length para determinar o número de regiões definidas por esse conjunto de dados.
6. A função table pega um vetor e retorna a frequência de cada elemento. Você pode ver rapidamente quantos estados existem em cada região aplicando esta função. Use essa função em uma linha de código para criar uma tabela de estados por região.
2.6 Vetores
Em R, os objetos mais básicos disponíveis para armazenar dados são os vectors (vetores). Como vimos, conjuntos de dados complexos geralmente podem ser divididos em componentes que são vetores. Por exemplo, em um data frame, cada coluna é um vetor. Aqui nós aprendemos mais sobre essa importante classe.
2.6.1 Criando vetores
Podemos criar vetores usando a função c, que significa concatenate (concatenar). Nós usamos c para concatenar entradas da seguinte maneira:
codes <- c(380, 124, 818)
codes
#> [1] 380 124 818Também podemos criar vetores de caracteres. Usamos aspas para indicar que as entradas são caracteres e não nomes de variáveis.
country <- c("italy", "canada", "egypt")Em R, também pode-se usar apóstrofos:
country <- c('italy', 'canada', 'egypt')Mas tome cuidado para não confundir o apóstrofo (single quote) ' com o acento grave (back quote) `.
Até agora você deve saber que se você escrever:
country <- c(italy, canada, egypt)você receberá um erro porque as variáveis italy, canada e egypt não estão definidos. Se não usarmos as aspas, R procurará variáveis com esses nomes e retornará um erro.
2.6.2 Nomes
Às vezes, é útil nomear as entradas de um vetor. Por exemplo, ao definir um vetor de códigos de países, podemos usar os nomes para conectar os dois:
codes <- c(italy = 380, canada = 124, egypt = 818)
codes
#> italy canada egypt
#> 380 124 818O objeto codes continua sendo um vetor numérico:
class(codes)
#> [1] "numeric"mas com nomes:
names(codes)
#> [1] "italy" "canada" "egypt"Se o uso de strings sem aspas parecer confuso, saiba que você também pode usar aspas:
codes <- c("italy" = 380, "canada" = 124, "egypt" = 818)
codes
#> italy canada egypt
#> 380 124 818Não há diferença entre essa chamada de função (function call em inglês) e a anterior. Essa é uma das muitas maneiras pelas quais R é peculiar em comparação com outras linguagens.
Também podemos atribuir nomes usando a função names:
codes <- c(380, 124, 818)
country <- c("italy","canada","egypt")
names(codes) <- country
codes
#> italy canada egypt
#> 380 124 8182.6.3 Sequências
Outra função útil para criar vetores gerando sequências:
seq(1, 10)
#> [1] 1 2 3 4 5 6 7 8 9 10O primeiro argumento define o começo e o segundo define o fim da sequência que será incluída. O padrão é aumentar a sequência por incrementos de 1. Entretanto, um terceiro argumento nos permite determinar quanto incrementar:
seq(1, 10, 2)
#> [1] 1 3 5 7 9Se quisérmos números inteiros consecutivos, podemos usar a seguinte abreviação:
1:10
#> [1] 1 2 3 4 5 6 7 8 9 10Quando usamos essas funções, R produz números do tipo integer, e não do tipo numeric, uma vez que são tipicamente usados para indexar algo:
class(1:10)
#> [1] "integer"No entanto, se criarmos uma sequência que inclua números não-inteiros, a classe mudará:
class(seq(1, 10, 0.5))
#> [1] "numeric"2.6.4 Criando subconjuntos
Usamos colchetes para acessar elementos específicos de um vetor. Para o vetor codes que definimos anteriormente, podemos acessar o segundo elemento usando:
codes[2]
#> canada
#> 124Você pode obter mais de uma entrada usando um vetor de múltiplas entradas como índice:
codes[c(1,3)]
#> italy egypt
#> 380 818As sequências definidas acima são particularmente úteis se precisarmos acessar, digamos, os dois primeiros elementos:
codes[1:2]
#> italy canada
#> 380 124Se os elementos tiverem nomes, também podemos acessar as entradas usando esses nomes. Aqui estão dois exemplos:
codes["canada"]
#> canada
#> 124
codes[c("egypt","italy")]
#> egypt italy
#> 818 3802.7 Conversão forçada
Em geral, uma conversao forçada (também denominada coerção ou no original coercion) é uma tentativa do R de ser flexível com os tipos de dados. Quando uma entrada não corresponde ao esperado, algumas das funções predefinidas do R tentam adivinhar o que se estava tentando fazer antes de retornar uma mensagem de erro. Isso também pode causar confusão. Não entendendo a conversão forçada, os programadores podem enlouquecer quando codificam em R, pois o R se comporta de maneira bem diferente da maioria das outras linguagens nesse sentido. Vamos aprender mais com alguns exemplos.
Dissemos que os vetores devem ser todos do mesmo tipo. Portanto, se tentarmos combinar, por exemplo, números e caracteres, você pode esperar um erro:
x <- c(1, "canada", 3)Mas o código acima não retorna um erro. Nem mesmo um aviso! O que aconteceu? Observe x e sua classe:
x
#> [1] "1" "canada" "3"
class(x)
#> [1] "character"R forçou uma conversão dos dados em caracteres. Como inserimos uma sequência de caracteres no vetor, R adivinhou que nossa intenção era que 1 e 3 fossem as strings "1" e "3". O fato de nem sequer emitir um aviso é um exemplo de como a conversão forçada pode causar muitos erros que não serão percebidos no R.
R também oferece funções para mudar de um tipo para outro. Por exemplo, pode-se converter números em caracteres com:
x <- 1:5
y <- as.character(x)
y
#> [1] "1" "2" "3" "4" "5"Pode-se reverter isso com as.numeric:
as.numeric(y)
#> [1] 1 2 3 4 5Essa função é realmente bastate útil, uma vez que datasets que incluem tanto valores numéricos, quanto cadeias de caracteres, são comuns.
2.7.1 Valores NA
Quando uma função tenta forçar uma conversão de um tipo para outro e encontra um caso impossível, R geralmente nos dá um aviso e converte a entrada em um valor especial chamado NA o que significa “não disponível” (Not Available em inglês). Por exemplo:
x <- c("1", "b", "3")
as.numeric(x)
#> Warning: NAs introduced by coercion
#> [1] 1 NA 3R não tem qualquer palpite sobre o número que você queria quando escreveu b, por isso ele nem tenta adivinhar.
Como cientista de dados, você encontrará NAs frequentemente, uma vez que tais valores, geralmente, são usados para representar dados ausentes, um problema comum em datasets do mundo real.
2.8 Exercícios
1. Use a função c para criar um vetor com as temperaturas médias altas em janeiro para Pequim, Lagos, Paris, Rio de Janeiro, San Juan e Toronto, com 35, 88, 42, 84, 81 e 30 graus Fahrenheit. Chame o objeto de temp.
2. Agora crie um vetor com os nomes das cidades e chame o objeto de city.
3. Use a função names e os objetos definidos nos exercícios anteriores para associar os dados de temperatura à cidade correspondente.
4. Use operadores [ e : para acessar a temperatura das três primeiras cidades da lista.
5. Use o operador [ para acessar a temperatura de Paris e San Juan.
6. Use o operador : para criar uma sequência de números \(12,13,14,\dots,73\).
7. Crie um vetor contendo todos os números ímpares positivos menores que 100.
8. Crie um vetor de números que comece em 6, não ultrapasse 55 e adicione números em incrementos de 4/7: 6, 6 + 4/7, 6 + 8/7, e assim por diante. Quantos números a lista possui? Dica: use seq e length.
9. Qual é a classe do seguinte objeto: a <- seq(1, 10, 0.5)?
10. Qual é a classe do seguinte objeto: a <- seq(1, 10)?
11. A classe de class(a<-1) é numeric, e não integer. R por padrão usa o tipo numeric. Para forçar o uso do tipo integer, você deve adicionar a letra L. Confirme se a classe de 1L é integer.
12. Defina o seguinte vetor:
x <- c("1", "3", "5")a seguir, converta esse vetor para o tipo integer.
2.9 Ordenação
Agora que dominamos alguns conhecimentos básicos de R, vamos tentar obter alguns insights sobre segurança em diferentes estados no contexto de assassinatos por armas de fogo.
2.9.1 sort
Digamos que desejemos classificar os estados, do menor para o maior, com base no índice de assassinatos por armas. A função sort classifica um vetor em ordem crescente. Portanto, podemos ver o maior número de assassinatos por arma, escrevendo:
library(dslabs)
data(murders)
sort(murders$total)
#> [1] 2 4 5 5 7 8 11 12 12 16 19 21 22
#> [14] 27 32 36 38 53 63 65 67 84 93 93 97 97
#> [27] 99 111 116 118 120 135 142 207 219 232 246 250 286
#> [40] 293 310 321 351 364 376 413 457 517 669 805 1257Entretanto, isso não nos fornece informações vinculando quais estados têm quais índices de assassinatos. Por exemplo, não sabemos em que estado apresentou 1257 assassinatos.
2.9.2 order
A função order é mais apropriada para o que queremos fazer. order recebe um vetor como entrada e retorna um vetor de índices que classifica o vetor de entrada. Isso pode parecer um pouco confuso, então vamos analisar um exemplo simples. Podemos criar um vetor e ordená-lo:
x <- c(31, 4, 15, 92, 65)
sort(x)
#> [1] 4 15 31 65 92Em vez de ordenar o vetor de entrada, a função order retorna o índice que classifica o vetor de entrada:
index <- order(x)
x[index]
#> [1] 4 15 31 65 92Este é o mesmo resultado retornado por sort(x). Se olharmos para os índices, veremos porque isso funciona:
x
#> [1] 31 4 15 92 65
order(x)
#> [1] 2 3 1 5 4A segunda entrada de x é o menor valor, logo order(x) começa com o índice 2. O próximo menor valor é a terceira entrada, portanto, o segundo índice é 3, e assim por diante.
Como isso nos ajuda a classificar os estados por assassinato? Primeiro, lembre-se de que as entradas de vetores que você acessa com $ seguem a mesma ordem que as linhas da tabela. Por exemplo, estes dois vetores que contêm os nomes dos estados e suas abreviações, respectivamente, seguem a mesma ordem:
murders$state[1:6]
#> [1] "Alabama" "Alaska" "Arizona" "Arkansas" "California"
#> [6] "Colorado"
murders$abb[1:6]
#> [1] "AL" "AK" "AZ" "AR" "CA" "CO"Isso significa que podemos classificar os nomes dos estados com base no total de assassinatos. Primeiro, obtemos o índice que ordena os vetores pelo número total de assassinatos. A seguir, indexamos o vetor de nomes de estados:
ind <- order(murders$total)
murders$abb[ind]
#> [1] "VT" "ND" "NH" "WY" "HI" "SD" "ME" "ID" "MT" "RI" "AK" "IA" "UT"
#> [14] "WV" "NE" "OR" "DE" "MN" "KS" "CO" "NM" "NV" "AR" "WA" "CT" "WI"
#> [27] "DC" "OK" "KY" "MA" "MS" "AL" "IN" "SC" "TN" "AZ" "NJ" "VA" "NC"
#> [40] "MD" "OH" "MO" "LA" "IL" "GA" "MI" "PA" "NY" "FL" "TX" "CA"De acordo com o código acima, a Califórnia teve o maior número de assassinatos.
2.9.3 max e which.max
Se estivermos interessados apenas na entrada com o valor mais alto, podemos usar max para obter esse valor:
max(murders$total)
#> [1] 1257e which.max para o índice de valor mais alto:
i_max <- which.max(murders$total)
murders$state[i_max]
#> [1] "California"Para determinar o menor valor, podemos usar min e which.min do mesmo modo.
Isso significa que a Califórnia é o estado mais perigoso? Em uma próxima seção, argumentamos que devemos considerar proporções e não totais. Antes de fazer isso, apresentaremos uma última função relacionada à ordem: rank.
2.9.4 rank
Embora não seja usada com tanta frequência quanto order e sort, a função rank também pode ser utilizada para classificação e pode ser bastante útil.
Para qualquer vetor, rank retorna um outro vetor com a posição de classificação dos itens do vetor de entrada quando ordenados. Aqui está um exemplo simples:
x <- c(31, 4, 15, 92, 65)
rank(x)
#> [1] 3 1 2 5 4Para resumir, vejamos os resultados das três funções que apresentamos:
| original | sort | order | rank |
|---|---|---|---|
| 31 | 4 | 2 | 3 |
| 4 | 15 | 3 | 1 |
| 15 | 31 | 1 | 2 |
| 92 | 65 | 5 | 5 |
| 65 | 92 | 4 | 4 |
2.9.5 Cuidado com a reciclagem
Outra fonte comum de erros que podem passar despercebidos no R é o uso de reciclagem (recycling no inglês). Vimos que os vetores são adicionados elemento a elemento. Portanto, se os vetores não coincidirem em comprimento, é natural supor que receberemos um erro. Mas esse não é o caso. Veja o que acontece:
x <- c(1, 2, 3)
y <- c(10, 20, 30, 40, 50, 60, 70)
x+y
#> Warning in x + y: longer object length is not a multiple of shorter
#> object length
#> [1] 11 22 33 41 52 63 71Recebemos um aviso, mas não há erro. Para o resultado, R reciclou os números em x. Veja o último dígito dos números na saída (ou seja, nessa soma a reciclagem faz x ser equivalente a c(1, 2, 3, 1, 2, 3, 1)).
2.10 Exercícios
Para os exercícios a seguir, usaremos o dataset de assassinatos nos EUA. Certifique-se de carregá-lo antes de começar.
library(dslabs)
data("murders")1. Use o operador $ para acessar os dados de tamanho da população e armazená-los em um objeto denominado pop. Então use a função sort ordenar pop. Por fim, use o operador [ para indicar o menor tamanho populacional.
2. Agora, em vez de determinar o valor do menor tamanho populacional, encontre o índice da entrada com o menor tamanho populacional. Dica: use order ao invés de sort.
3. Podemos realizar a mesma operação que no exercício anterior usando a função which.min. Escreva uma linha de código que faça isso.
4. Agora sabemos o quão pequeno é o menor estado e qual linha o representa. Que estado é esse? Defina uma variável denominada states para receber os nomes dos estados do data frame murders. Digite o nome do estado com a menor população.
5. Você pode criar um data frame usando a função data.frame. Aqui está um exemplo:
temp <- c(35, 88, 42, 84, 81, 30)
city <- c("Beijing", "Lagos", "Paris", "Rio de Janeiro",
"San Juan", "Toronto")
city_temps <- data.frame(name = city, temperature = temp)Use a função rank para determinar a faixa populacional de cada estado, do menos populoso ao mais populoso. Armazene esses intervalos em um objeto chamado ranks, e crie um data frame com o nome do estado e sua posição no rank. Nomeie o data frame como my_df.
6. Repita o exercício anterior, mas desta vez ordene my_df para que os estados estejam na ordem de menos populosos para os mais populosos. Dica: crie um objeto ind que armazena os índices necessários para ordenar os valores da população. Em seguida, use o operador de suporte [ para reordenar cada coluna no data frame.
7. O vetor na_example representa uma série de contagens. Você pode navegar rapidamente pelo objeto usando:
data("na_example")
str(na_example)
#> int [1:1000] 2 1 3 2 1 3 1 4 3 2 ...No entanto, quando calculamos a média com a função mean, obtemos um NA:
mean(na_example)
#> [1] NAA função is.na retorna um vetor lógico que nos diz quais entradas são NA. Atribua esse vetor lógico a um objeto chamado ind e determine quantas entradas NA existem em na_example.
8. Agora calcule a média novamente apenas para as entradas que não são NA. Dica: lembre-se do operador !.
2.11 Aritmética vetorial
A Califórnia teve mais assassinatos, mas isso significa que é o estado mais perigoso? E se ela apenas possuir muito mais pessoas do que qualquer outro estado? Podemos confirmar rapidamente que a Califórnia tem a maior população:
library(dslabs)
data("murders")
murders$state[which.max(murders$population)]
#> [1] "California"com mais do que 37 milhões de habitantes. Portanto, é injusto comparar os totais se estivermos interessados em saber quão seguro é o estado. O que realmente devemos calcular são os assassinatos per capita. Os relatórios que descrevemos na seção motivadora usam assassinatos por 100.000 habitantes como unidade. Para calcular essa quantidade, usamos os poderosos recursos aritméticos vetoriais de R.
2.11.1 Reescalonando um vetor
Em R, operações aritméticas em vetores ocorrem elemento a elemento. Como exemplo, suponha que tenhamos as seguintes alturas em polegadas (1 polegada é equivalente a 2,54 centímetros):
inches <- c(69, 62, 66, 70, 70, 73, 67, 73, 67, 70)e queremos convertê-las em centímetros. Observe o que acontece quando multiplicamos inches por 2.54:
inches * 2.54
#> [1] 175 157 168 178 178 185 170 185 170 178Acima, multiplicamos cada elemento por 2,54. Da mesma forma, se para cada entrada queremos calcular o quanto cada uma é maior ou menor que 69 polegadas (a altura média para homens), podemos subtraí-las de cada entrada desta maneira:
inches - 69
#> [1] 0 -7 -3 1 1 4 -2 4 -2 12.11.2 Dois vetores
Se tivermos dois vetores de mesmo comprimento e os somá-los usando R, eles serão somados entrada por entrada da seguinte maneira:
\[ \begin{pmatrix} a\\ b\\ c\\ d \end{pmatrix} + \begin{pmatrix} e\\ f\\ g\\ h \end{pmatrix} = \begin{pmatrix} a +e\\ b + f\\ c + g\\ d + h \end{pmatrix} \]
O mesmo se aplica a outras operações matemáticas, como -, * e /.
Isso implica que, para calcular as taxas de homicídio (murder rates em inglês), podemos simplesmente escrever:
murder_rate <- murders$total / murders$population * 100000Ao fazer isso, percebemos que a Califórnia não está mais perto do topo da lista. De fato, podemos usar o que aprendemos para colocar os estados em ordem com base na taxa de homicídios:
murders$abb[order(murder_rate)]
#> [1] "VT" "NH" "HI" "ND" "IA" "ID" "UT" "ME" "WY" "OR" "SD" "MN" "MT"
#> [14] "CO" "WA" "WV" "RI" "WI" "NE" "MA" "IN" "KS" "NY" "KY" "AK" "OH"
#> [27] "CT" "NJ" "AL" "IL" "OK" "NC" "NV" "VA" "AR" "TX" "NM" "CA" "FL"
#> [40] "TN" "PA" "AZ" "GA" "MS" "MI" "DE" "SC" "MD" "MO" "LA" "DC"2.12 Exercícios
1. Criamos anteriormente este data frame:
temp <- c(35, 88, 42, 84, 81, 30)
city <- c("Beijing", "Lagos", "Paris", "Rio de Janeiro",
"San Juan", "Toronto")
city_temps <- data.frame(name = city, temperature = temp)Recrie o data frame usando o código acima, mas adicione uma linha que converta a temperatura de Fahrenheit em Celsius. A conversão é \(C = \frac{5}{9} \times (F - 32)\).
2. Qual é o resultado da seguinte soma? \(1+1/2^2 + 1/3^2 + \dots 1/100^2\)? Dica: Graças a Euler, sabemos que o resultado deve ser próximo de \(\pi^2/6\).
3. Calcule a taxa de homicídios por 100.000 habitantes para cada estado e armazene-a no objeto murder_rate. Em seguida, encontre a taxa média de homicídios nos EUA com função mean. Qual é a média?
2.13 Indexação
R fornece uma maneira poderosa e conveniente para indexar vetores. Podemos, por exemplo, criar um subconjunto de um vetor com base nas propriedades de outro vetor. Nesta seção, continuaremos a trabalhar em nosso exemplo de assassinato nos EUA, que podemos carregar assim:
library(dslabs)
data("murders")2.13.1 Criando subconjuntos com objetos do tipo lógico
Agora calculamos a taxa de homicídios usando:
murder_rate <- murders$total / murders$population * 100000Imagine se mudar da Itália onde, segundo uma reportagem do canal de notícias ABC News, a taxa de homicídios é de apenas 0,71 por 100.000. Você prefereria se mudar para um estado com uma taxa de homicídios semelhante. Outro recurso poderoso do R é que podemos usar operadores lógicos para indexar vetores. Se compararmos um vetor com um único número, R realiza o teste para cada entrada. Aqui está um exemplo relacionado à questão anterior:
ind <- murder_rate < 0.71Se, em vez disso, queremos saber se um valor é menor ou igual, podemos usar:
ind <- murder_rate <= 0.71Note que que recuperamos um vetor lógico com TRUE para cada entrada menor ou igual a 0,71. Para ver quais são esses estados, podemos tirar proveito do fato de que vetores podem ser indexados com objetos do tipo lógico.
murders$state[ind]
#> [1] "Hawaii" "Iowa" "New Hampshire" "North Dakota"
#> [5] "Vermont"Para contar quantas entradas são verdadeiras (TRUE), a função sum retorna a soma das entradas de um vetor e força a conversão de vetores lógicos em números com TRUE codificado como 1 e FALSE como 0. Portanto, podemos contar os estados usando:
sum(ind)
#> [1] 52.13.2 Operadores lógicos
Suponha que gostemos de montanhas e que desejemos mudar para um estado seguro na região oeste do país. Queremos que a taxa de homicídios seja no máximo 1. Nesse caso, queremos que duas coisas diferentes sejam verdadeiras. Aqui podemos usar o operador lógico and, que em R é representado por &. Esta operação resulta em TRUE somente quando ambas as lógicas são TRUE, isto é, verdadeiras. Para ver isso, considere este exemplo:
TRUE & TRUE
#> [1] TRUE
TRUE & FALSE
#> [1] FALSE
FALSE & FALSE
#> [1] FALSEPara o nosso exemplo, podemos formar duas condições lógicas:
west <- murders$region == "West"
safe <- murder_rate <= 1e podemos usar o & para obter um vetor lógico que nos diz quais estados satisfazem ambas as condições:
ind <- safe & west
murders$state[ind]
#> [1] "Hawaii" "Idaho" "Oregon" "Utah" "Wyoming"2.13.3 which
Suponha que queremos ver a taxa de homicídios da Califórnia. Para esse tipo de operação, é conveniente converter vetores lógicos em índices em vez de manter vetores lógicos longos. A função which nos diz quais entradas de um vetor lógico são verdadeiras. Então podemos escrever:
ind <- which(murders$state == "California")
murder_rate[ind]
#> [1] 3.372.13.4 match
Se, em vez de um único estado, desejamos descobrir as taxas de assassinatos de vários estados, digamos Nova York, Flórida e Texas, podemos usar a função match. Essa função nos diz quais índices de um segundo vetor correspondem a cada uma das entradas de um primeiro vetor:
ind <- match(c("New York", "Florida", "Texas"), murders$state)
ind
#> [1] 33 10 44Agora podemos ver as taxas de homicídio:
murder_rate[ind]
#> [1] 2.67 3.40 3.202.13.5 %in%
Se, em vez de um índice, desejamos que uma expressão lógica nos diga se cada elemento de um primeiro vetor está em um segundo vetor, podemos usar a função %in%. Vamos imaginar que você não tem certeza se Boston, Dakota e Washington são estados. Você pode descobrir assim:
c("Boston", "Dakota", "Washington") %in% murders$state
#> [1] FALSE FALSE TRUELembre-se de que usaremos %in% frequentemente ao longo do livro.
Avançado: existe uma conexão entre match e %in% através de which. Para ver isso, observe que as duas linhas a seguir produzem o mesmo índice (embora em ordem diferente):
match(c("New York", "Florida", "Texas"), murders$state)
#> [1] 33 10 44
which(murders$state%in%c("New York", "Florida", "Texas"))
#> [1] 10 33 442.14 Exercícios
Comece carregando a biblioteca e os dados.
library(dslabs)
data(murders)1. Calcule a taxa de homicídios por 100.000 habitantes para cada estado e armazene-a em um objeto chamado murder_rate. Em seguida, use operadores lógicos para criar um vetor lógico chamado low que nos diz quais entradas de murder_rate são menores que 1.
2. Agora use os resultados do exercício anterior e a função which para determinar os índices de murder_rate associados a valores menores que 1.
3. Use os resultados do exercício anterior para indicar os nomes dos estados com taxas de homicídio menores que 1.
4. Agora estenda o código dos Exercícios 2 e 3 para indicar os estados do nordeste com taxas de homicídios menores que 1. Dica: Use o vetor lógico predefinido low e o operador lógico &.
5. Em um exercício anterior, calculamos a taxa de homicídios de cada estado e a média desses números. Quantos estados estão abaixo da média?
6. Use a função match para identificar estados com as abreviações AK, MI e IA. Dica: Comece definindo um índice das entradas em murders$abb que correspondem às três abreviações. Então use o operador [ para extrair os estados.
7. Use o operador %in% para criar um vetor lógico que responda à pergunta: quais das seguintes abreviações são reais: MA, ME, MI, MO, MU?
8. Estenda o código usado no Exercício 7 para descobrir a única entrada que não é uma abreviação real. Dica: use o operador !, que converte FALSE para TRUE e vice-versa, e depois which para obter um índice.
2.15 Gráficos básicos
No capítulo 7 descrevemos um pacote complementar que oferece uma abordagem poderosa para a produção de gráficos (plots em inglês) em R. Em seguida, temos uma parte completa sobre &Quot;Visualização de dados", na qual oferecemos muitos exemplos. Aqui, descrevemos brevemente algumas das funções disponíveis em uma instalação básica do R.
2.15.1 plot
A função plot pode ser usada para criar diagramas de dispersão (scatterplots em inglês). Aqui está um gráfico do total de assassinatos versus população.
x <- murders$population/ 10^6
y <- murders$total
plot(x, y)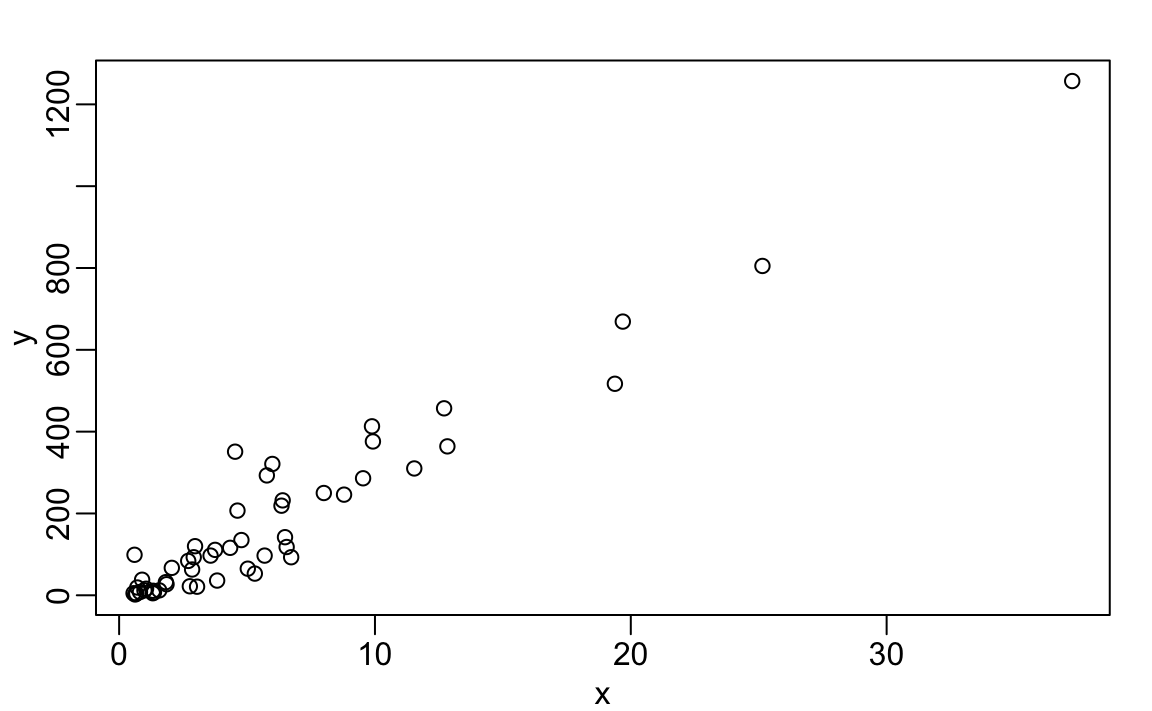
Para criar um gráfico rápido que não acessa variáveis duas vezes, podemos usar a função with:
with(murders, plot(population, total))A função with nos permite usar os nomes das colunas de murders na função plot. Também funciona com qualquer data frame e qualquer função.
2.15.2 hist
Vamos descrever os histogramas relacionados à distribuição na seção de “Visualização de dados” deste livro. Aqui, observaremos simplesmente que os histogramas são um resumo gráfico poderoso de uma lista de números que fornece uma visão geral dos tipos de valores que você possui. Podemos fazer um histograma de nossas taxas de assassinatos simplesmente digitando:
x <- with(murders, total/ population * 100000)
hist(x)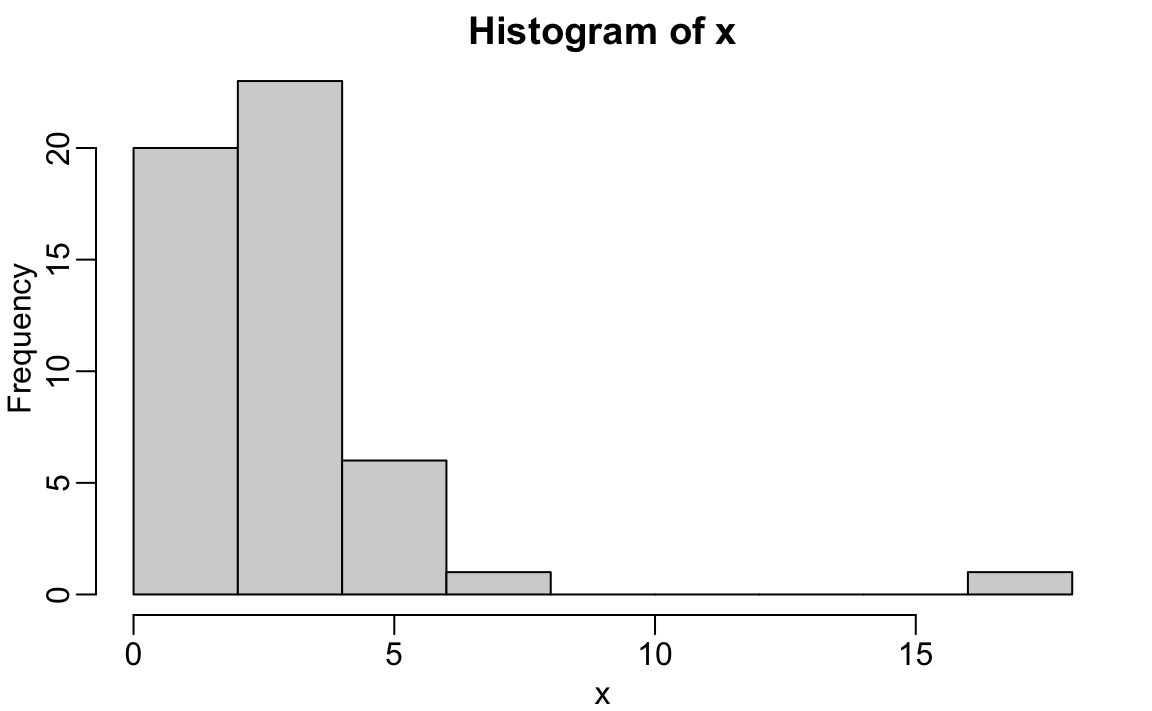
Podemos ver que há uma grande variedade de valores, com a maioria entre 2 e 3, e um caso muito extremo com uma taxa de homicídios acima de 15:
murders$state[which.max(x)]
#> [1] "District of Columbia"2.15.3 boxplot
Os diagramas de caixa (boxplots em inglês) também serão descritos na parte “Visualização de dados” do livro. Eles fornecem um resumo mais conciso do que os histogramas, mas são mais fáceis de comparar com outros boxplots. Por exemplo, aqui podemos usá-los para comparar diferentes regiões:
murders$rate <- with(murders, total/ population * 100000)
boxplot(rate~region, data = murders)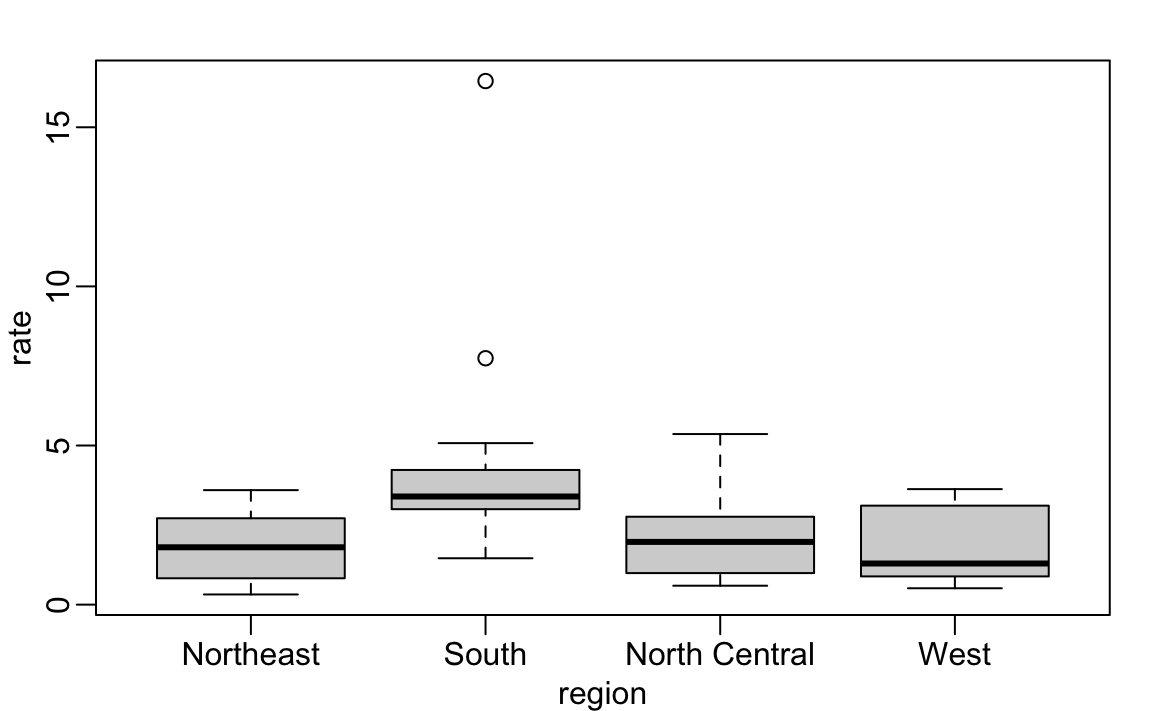
Podemos ver que o Sul tem taxas mais altas de assassinatos do que as outras três regiões.
2.15.4 image
A função image exibe os valores em uma matriz usando cores. Aqui está um exemplo rápido:
x <- matrix(1:120, 12, 10)
image(x)
2.16 Exercícios
1. Fizemos um gráfico do total de assassinatos versus população e notamos um forte relacionamento. Não é de se surpreender que os estados com populações maiores tenham mais assassinatos.
library(dslabs)
data(murders)
population_in_millions <- murders$population/10^6
total_gun_murders <- murders$total
plot(population_in_millions, total_gun_murders)Lembre-se de que muitos estados têm populações inferiores a 5 milhões e estão agrupados. Podemos obter mais informações criando esse gráfico na escala logarítmica. Transforme as variáveis usando transformação log10 e depois crie um gráfico com os resultados.
2. Crie um histograma das populações dos estados.
3. Gere boxplots das populações estaduais por região.