Capítulo 10 Princípios de visualização de dados
Já definimos algumas regras a serem seguidas ao criar gráficos para nossos exemplos. Aqui, nosso objetivo é oferecer alguns princípios gerais que podemos usar como um guia para uma visualização eficaz dos dados. Grande parte desta seção é baseada em uma palestra de Karl Broman33 intitulada “Criando figuras e tabelas eficazes”34 e inclui algumas das figuras que foram criadas com códigos que Karl disponibiliza em seu repositório GitHub35. Também nos baseamos em anotações das aulas do curso “Introdução à visualização de dados” de Peter Aldhous36. Seguindo a abordagem de Karl, mostramos alguns exemplos de estilos de gráficos que devem ser evitados, explicamos como melhorá-los e depois os usamos como motivação para uma lista de princípios. Além disso, comparamos e contrastamos gráficos que seguem esses princípios com outros que os ignoram.
Os princípios são baseados principalmente em pesquisas relacionadas à forma como os seres humanos detectam padrões e fazem comparações visuais. As abordagens preferidas são as que melhor se adaptam à maneira como nossos cérebros processam as informações visuais. Ao escolher as ferramentas de visualização, é importante ter em mente nosso objetivo. Podemos comparar um número suficientemente pequeno de números que podem ser distinguidos, descrevendo distribuições de dados categóricos ou valores numéricos, comparando os dados de dois grupos ou descrevendo a relação entre duas variáveis e isso afeta a apresentação que escolheremos. Como observação final, queremos enfatizar que é importante para cientistas de dados adaptar e otimizar gráficos para o público. Por exemplo, um gráfico exploratório feito para nós mesmos será diferente de um gráfico destinado a comunicação de uma descoberta a um público em geral.
Vamos usar estas bibliotecas:
library(tidyverse)
library(dslabs)
library(gridExtra)10.1 Codificando dados usando dicas visuais
Vamos começar descrevendo alguns princípios para codificar dados. Existem várias abordagens à nossa disposição, incluindo posição, comprimento, ângulos, área, brilho e cor.
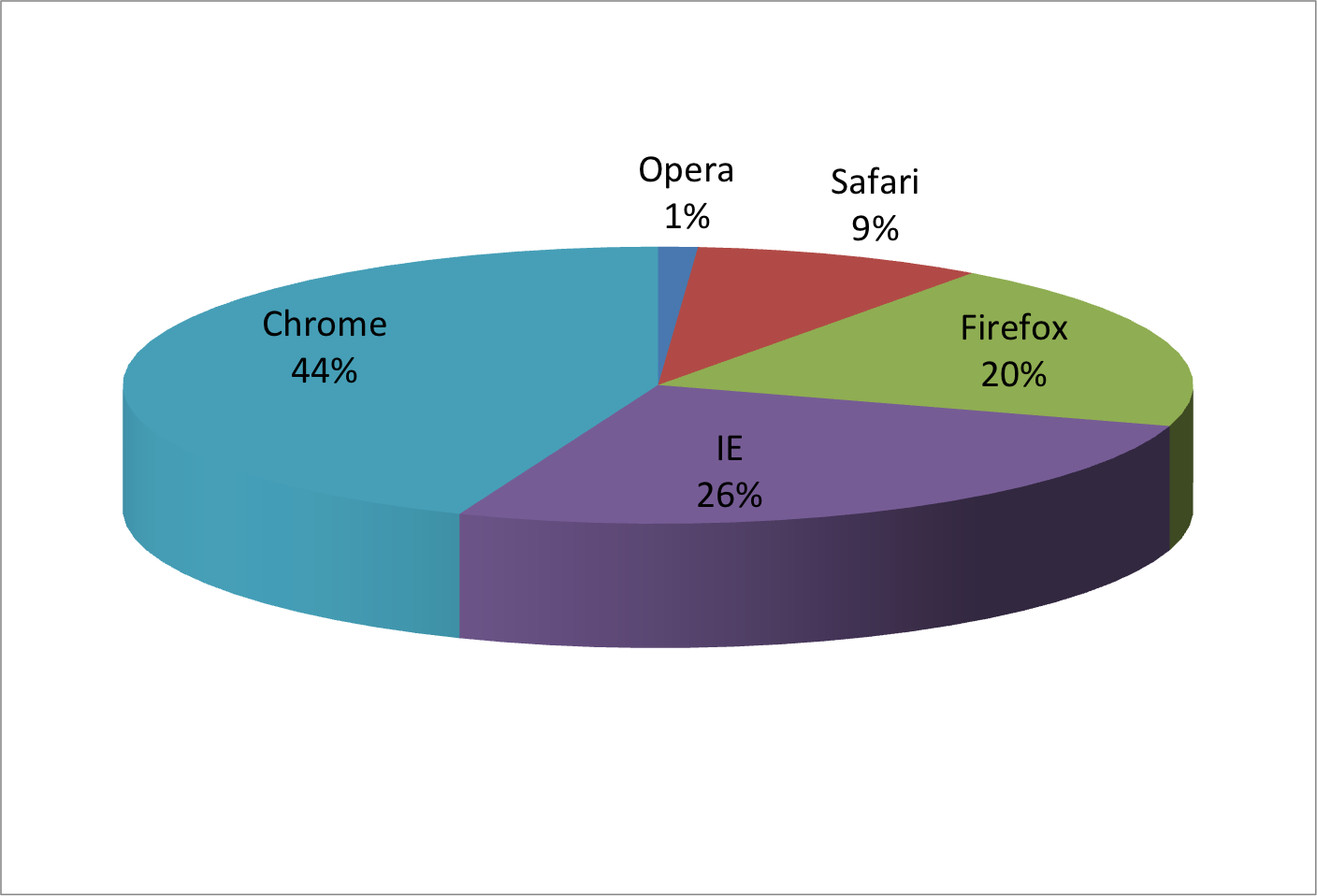
Para ilustrar como algumas dessas estratégias se comparam, vamos supor que desejamos relatar os resultados de duas pesquisas hipotéticas relacionadas à preferência por navegador de Internet (browser), realizadas em 2000 e 2015, respectivamente. Para cada ano, estamos simplesmente comparando cinco quantidades: as cinco porcentagens. Uma representação gráfica de porcentagens amplamente usada e popularizada pelo Microsoft Excel é o gráfico de pizza:
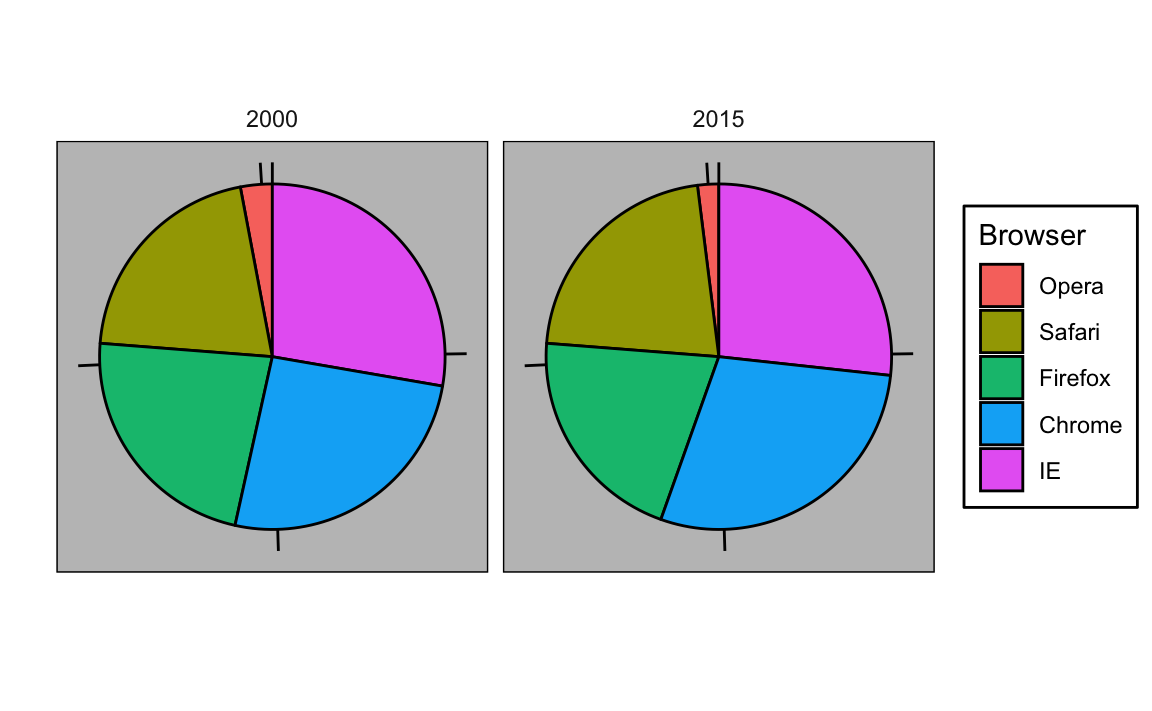
Aqui, estamos representando as quantidades através das áreas e dos ângulos, uma vez que o ângulo e a área de cada seção do gráfico são proporcionais à quantidade que o setor representa. Isso acaba sendo uma opção abaixo do ideal, pois, como demonstrado por estudos perceptivos, os seres humanos não são bons em quantificar com precisão ângulos e são ainda piores quando a área é o único sinal visual disponível. O gráfico de rosca é um exemplo de gráfico que usa apenas a área:
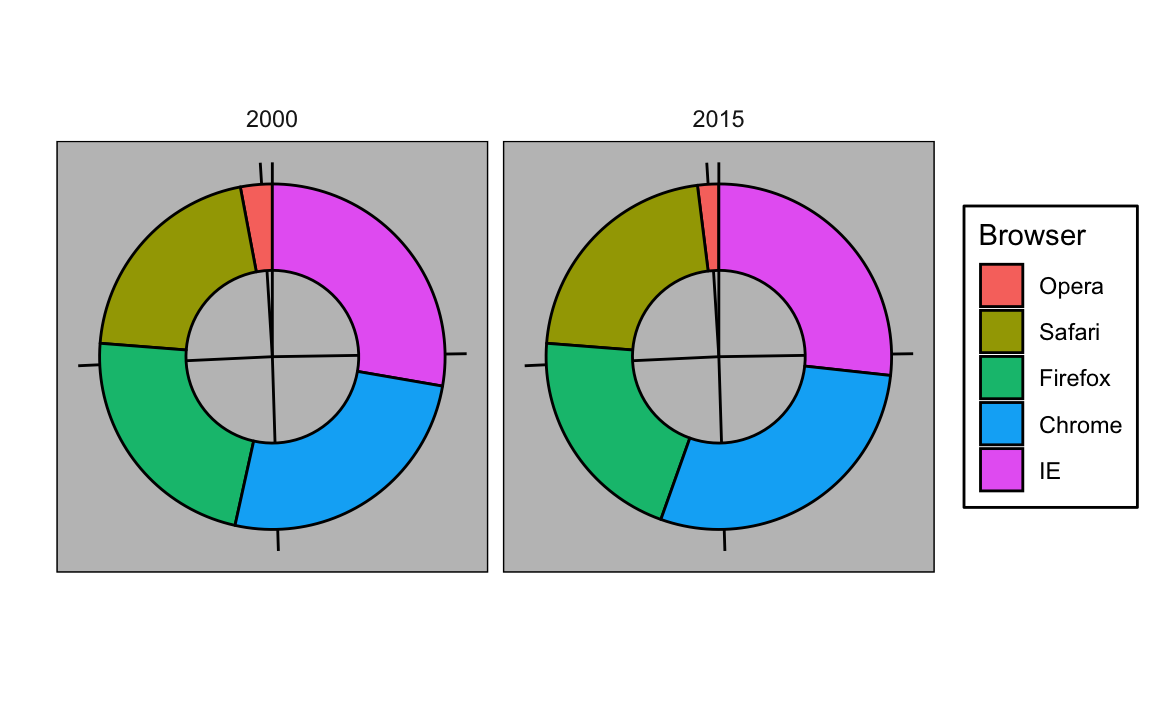
Para ver como é difícil quantificar ângulos e áreas, note que as classificações e todas as porcentagens nos gráficos acima foram alteradas entre 2000 e 2015. Você pode determinar as porcentagens reais e classificar a popularidade dos navegadores? Você pode ver como as porcentagens mudaram de 2000 para 2015? Não é fácil identificar isso através desse gráfico. De fato, a função pie da página de ajuda de R afirma que:
Os gráficos de pizza são uma forma ruim de exibir informações. O olho humano é bom em julgar medições lineares, mas ruim em julgar áreas relativas. Gráficos de barras ou de pontos são maneiras preferíveis de exibir esse tipo de dados.
Nesse caso, simplesmente exibir os números não é apenas mais claro, mas também reduziria custos caso você queira imprimir uma cópia em papel:
| Browser | 2000 | 2015 |
|---|---|---|
| Opera | 3 | 2 |
| Safari | 21 | 22 |
| Firefox | 23 | 21 |
| Chrome | 26 | 29 |
| IE | 28 | 27 |
Uma maneira preferivelmente melhor de representar graficamente essas quantidades é usar comprimento e posição como pistas visuais, uma vez que os humanos são muito melhores em julgar medições lineares. O gráfico de barras usa essa abordagem usando barras de comprimento proporcionais às quantias de interesse. Ao adicionar linhas horizontais a valores estrategicamente escolhidos, neste caso a cada múltiplo de 10, amenizamos a carga visual permitindo a identificação de quantidades através da posição da parte superior das barras. Compare e contraste as informações que podemos extrair das duas figuras abaixo.

Observe como é fácil ver as diferenças no gráfico de barras. De fato, agora podemos determinar as porcentagens reais seguindo as linhas horizontais ao eixo x.
Se, por algum motivo, você precisar criar um gráfico de pizza, rotule cada seção do círculo com sua respectiva porcentagem para que o público não precise inferi-las a partir dos ângulos ou da área:
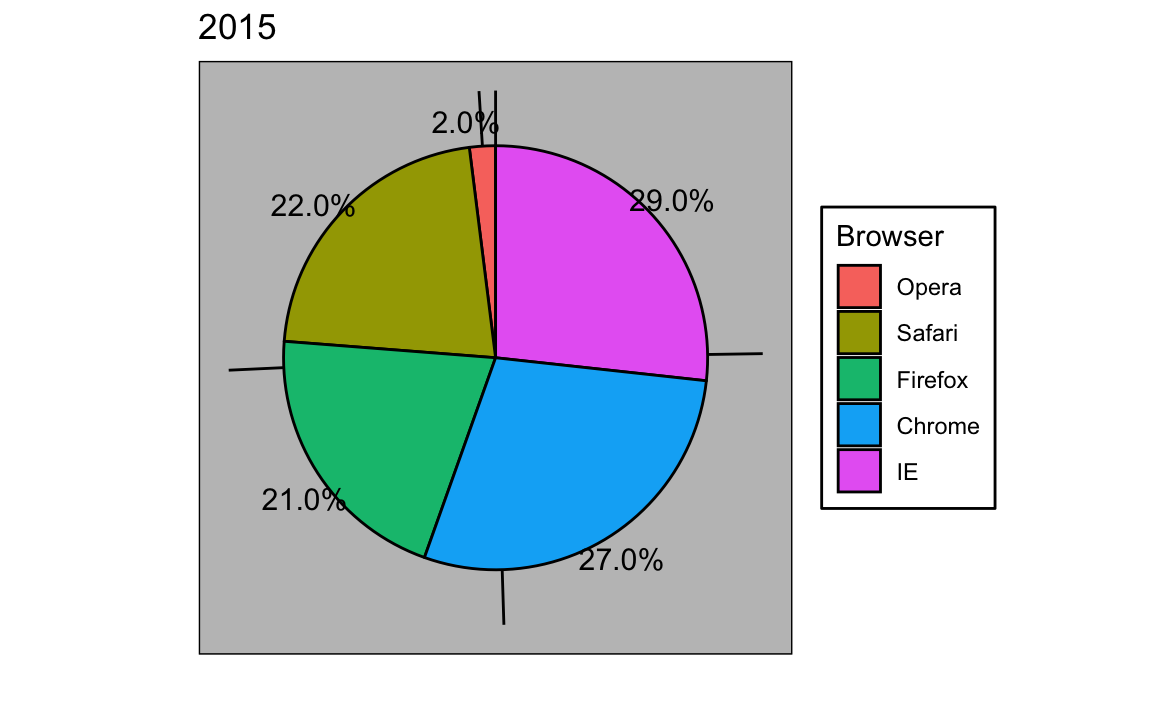
Em geral, ao exibir quantidades, posições e comprimentos são preferíveis do que exibir ângulos e/ou áreas. Além disso, brilho e cor são ainda mais difíceis de quantificar do que os ângulos. Mas, como veremos mais adiante, às vezes são úteis quando mais de duas dimensões devem ser exibidas ao mesmo tempo.
10.2 Saiba quando incluir 0
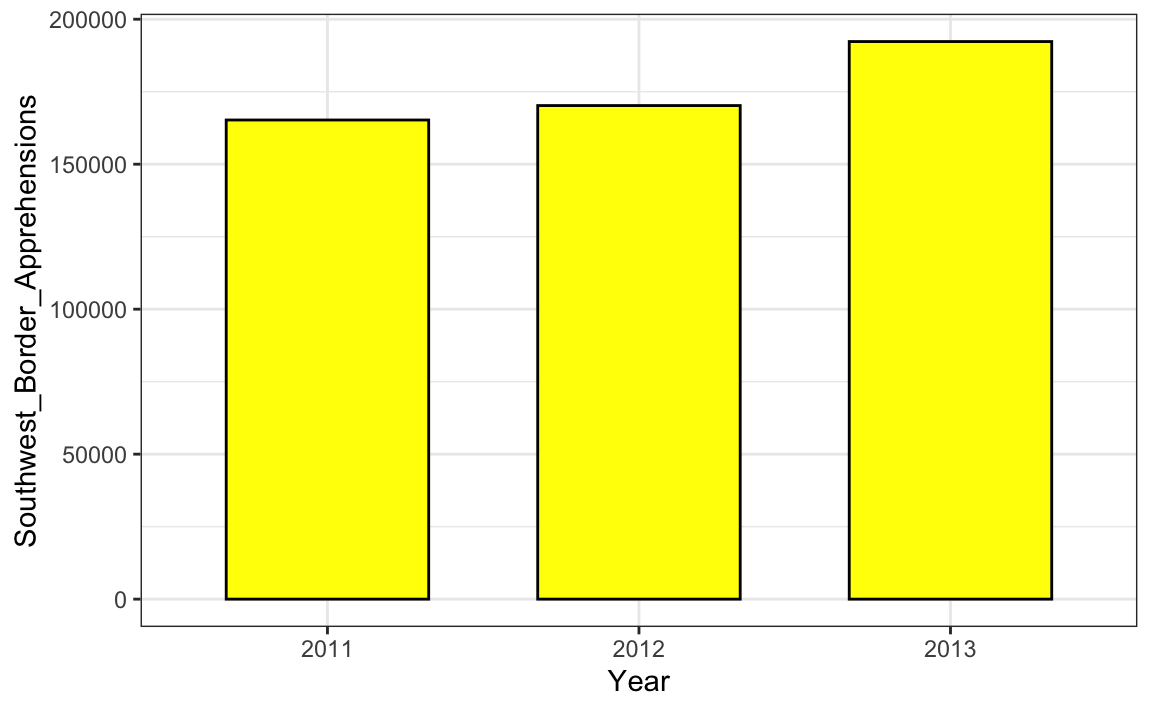
Ao usar gráficos de barras, é considerado desinformativo não iniciar as barras em 0. Isso ocorre porque, ao usar um gráfico de barras, estamos sugerindo que o comprimento é proporcional às quantidades mostradas. Evitando iniciar em 0, você pode fazer com que diferenças relativamente pequenas pareçam muito maiores do que realmente são. Essa abordagem é frequentemente usada por políticos ou organizações midiáticas tentando exagerar a diferença. Abaixo está um exemplo ilustrativo usado por Peter Aldhous nesta palestra: http://paldhous.github.io/ucb/2016/dataviz/week2.html.

(Detenções nas fronteiras dos Estados Unidos entre 2011 e 2013. Fonte: Fox News, via Media Matters37.)
No gráfico acima, as detenções parecem ter triplicado quando, de fato, elas aumentaram apenas cerca de 16%. Iniciar o gráfico em 0 ilustra isso claramente:
Abaixo, vemos outro exemplo, que é descrito em detalhes em um artigo do blog “Flowing Data”:
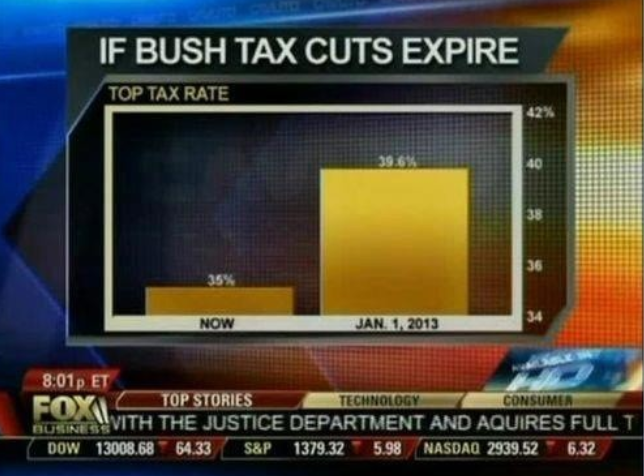 (Previsão do aumento de taxas nos Estados Unidos se o corte de impostos determinado no governo do presidente Bush expirar. Fonte: Fox News, através da Flowing Data38)
(Previsão do aumento de taxas nos Estados Unidos se o corte de impostos determinado no governo do presidente Bush expirar. Fonte: Fox News, através da Flowing Data38)
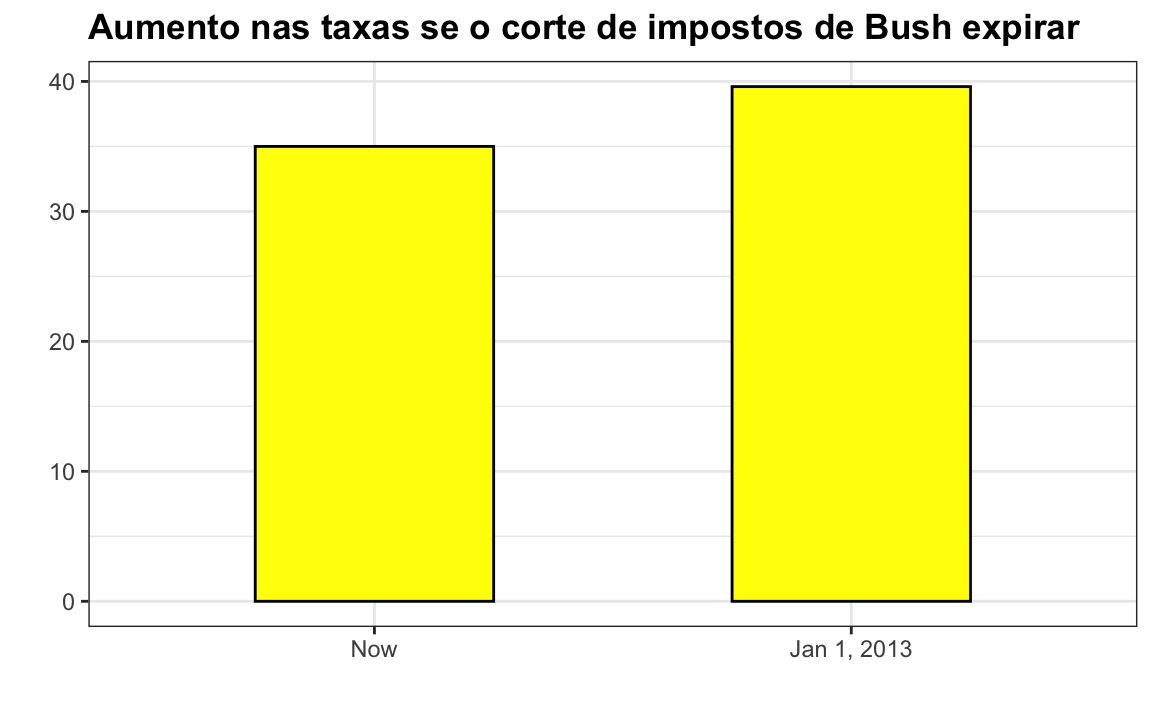
Este gráfico faz um aumento de 13% parecer cinco vezes maior. Aqui está um gráfico mais apropriado:
Finalmente, aqui está um exemplo extremo que faz uma diferença muito pequena de menos de 2% parecer 10 a 100 vezes maior:

(Fonte: Televisão venezuelana via Pakistan Today39 e Diego Mariano)
Aqui está um gráfico mais apropriado:

Ao construir gráficos que usam posições em vez de comprimentos, não é necessário iniciar o eixo y em 0. Particularmente, esse é o caso quando queremos comparar as diferenças entre grupos considerando o quanto seus dados variam. Aqui está um exemplo ilustrativo mostrando a expectativa média de vida de cada país estratificada por continente em 2012:
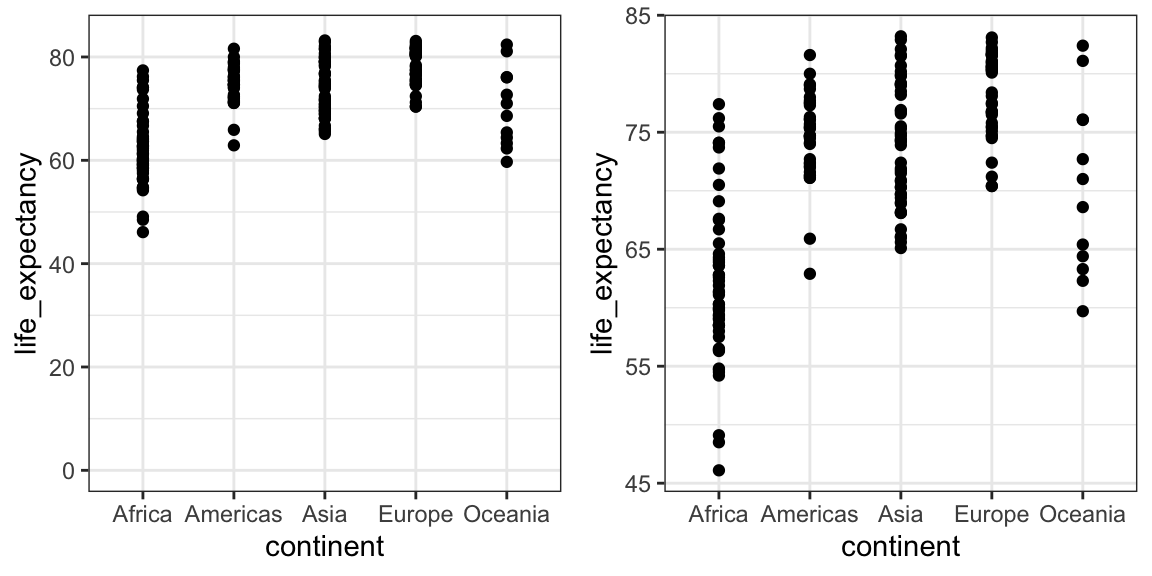
Observe que, no gráfico à esquerda (que inicia em 0), o espaço entre 0 e 43 não adiciona informações relevantes e, ainda, dificulta a comparação da variabilidade dentre grupos e dentro de cada grupo.
10.3 Não distorça quantidades
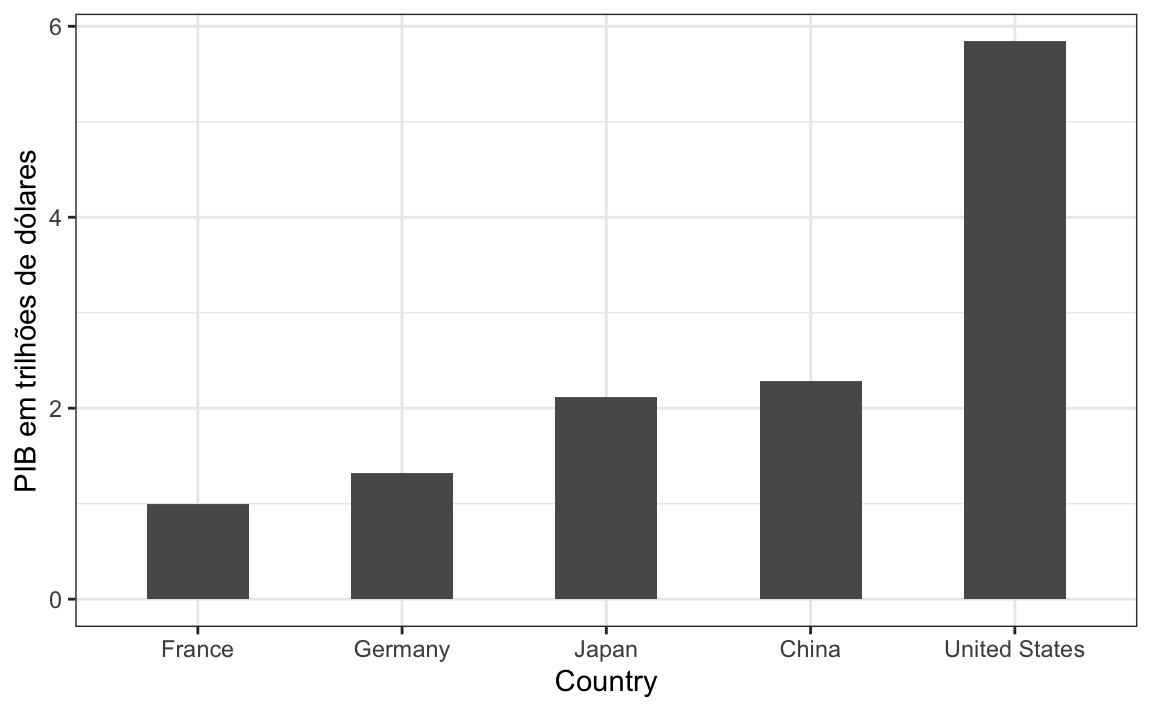
Durante o discurso do Estado da União do presidente Barack Obama em 2011, o gráfico a seguir foi usado para comparar o PIB dos EUA com o PIB de quatro nações concorrentes:
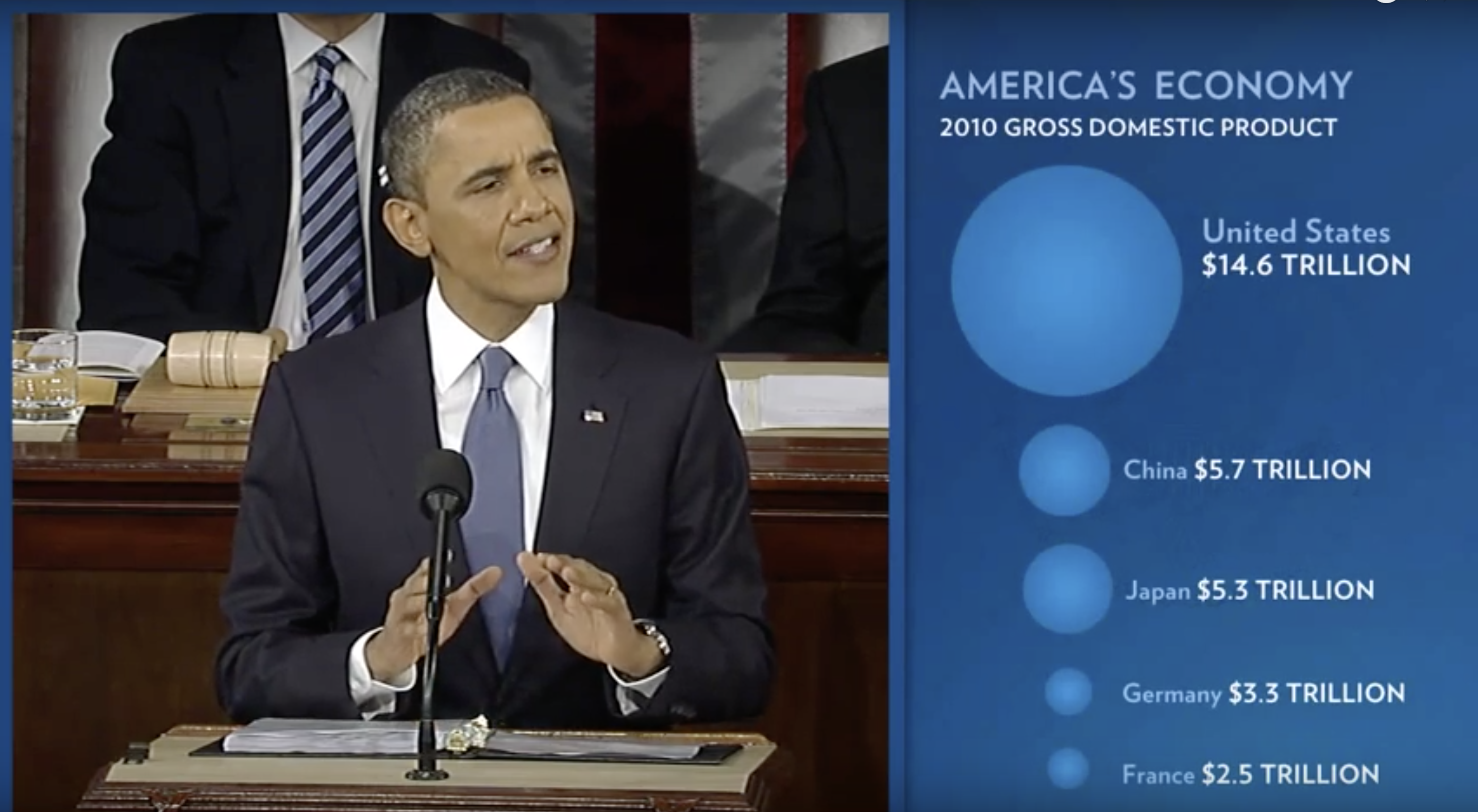 (Fonte: Discurso do Estado da União de 201140)
(Fonte: Discurso do Estado da União de 201140)
Se julgarmos pela área dos círculos, os Estados Unidos parecem ter uma economia cinco vezes maior do que a da China e mais de 30 vezes maior do que a da França. No entanto, se olharmos para os números atuais, veremos que esse não é o caso. As proporções são 2,6 e 5,8 vezes superiores às da China e da França, respectivamente. A razão para essa distorção é que foram utilizados os raios dos círculos para representar as quantidades, em vez das áreas. Como a proporção entre as áreas é ao quadrado, 2,6 se torna 6,5 e 5,8 se torna 34,1. Aqui está uma comparação entre círculos para valores proporcionais ao raio (esquerda) e à área (direita):
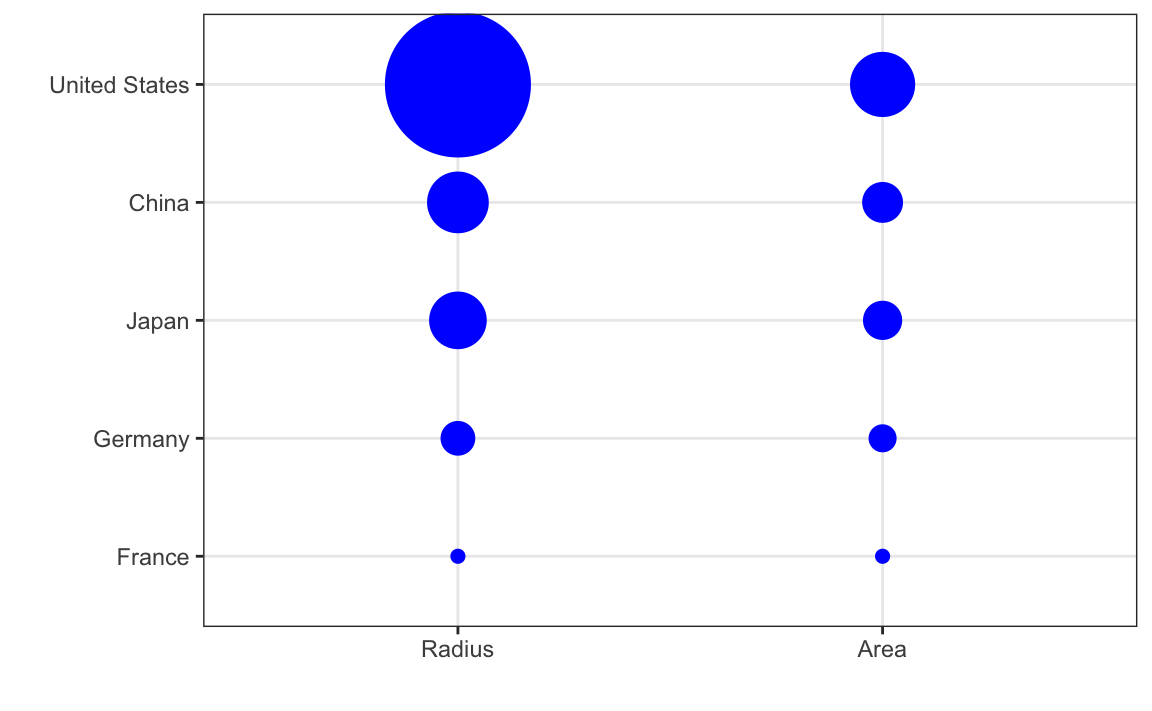
Não é surpresa que ggplot2 use por padrão a área em vez do raio. Obviamente, nesse caso, não devemos usar a área, pois podemos usar a posição e o comprimento:
10.4 Ordenando categorias por um valor significativo
Quando um dos eixos é usado para exibir categorias, como nos gráficos de barras, o comportamento padrão do ggplot2 é classificar as categorias em ordem alfabética quando definidas por cadeias de caracteres. Se as categorias forem definidas por fatores, elas são ordenados de acordo com os níveis dos fatores. Nesses casos, raramente queremos usar a ordem alfabética. Em vez disso, devemos ordenar por quantidades significativa. Em todos os casos apresentados anteriormente, gráficos de barras foram ordenados de acordo com os valores mostrados, exceto nos gráficos de barras comparando navegadores. Nesse caso, mantivemos a ordem igual em todos os gráficos de barras para facilitar a comparação. Especificamente, em vez de ordenar os navegadores separadamente nos dois anos, ordenamos ambos os anos pelo valor médio de 2000 e 2015.
Anteriormente, aprendemos a usar a função reorder, o que nos ajuda a alcançar esse objetivo. Para avaliar como a ordem correta pode ajudar a transmitir uma mensagem, suponha que desejamos criar um gráfico para comparar a taxa de homicídios em todos os estados dos EUA. Estamos particularmente interessados nos estados mais perigosos e nos mais seguros. Note a diferença de quando ordenamos alfabeticamente (a ação padrão) versus quando ordenamos pela taxa real:
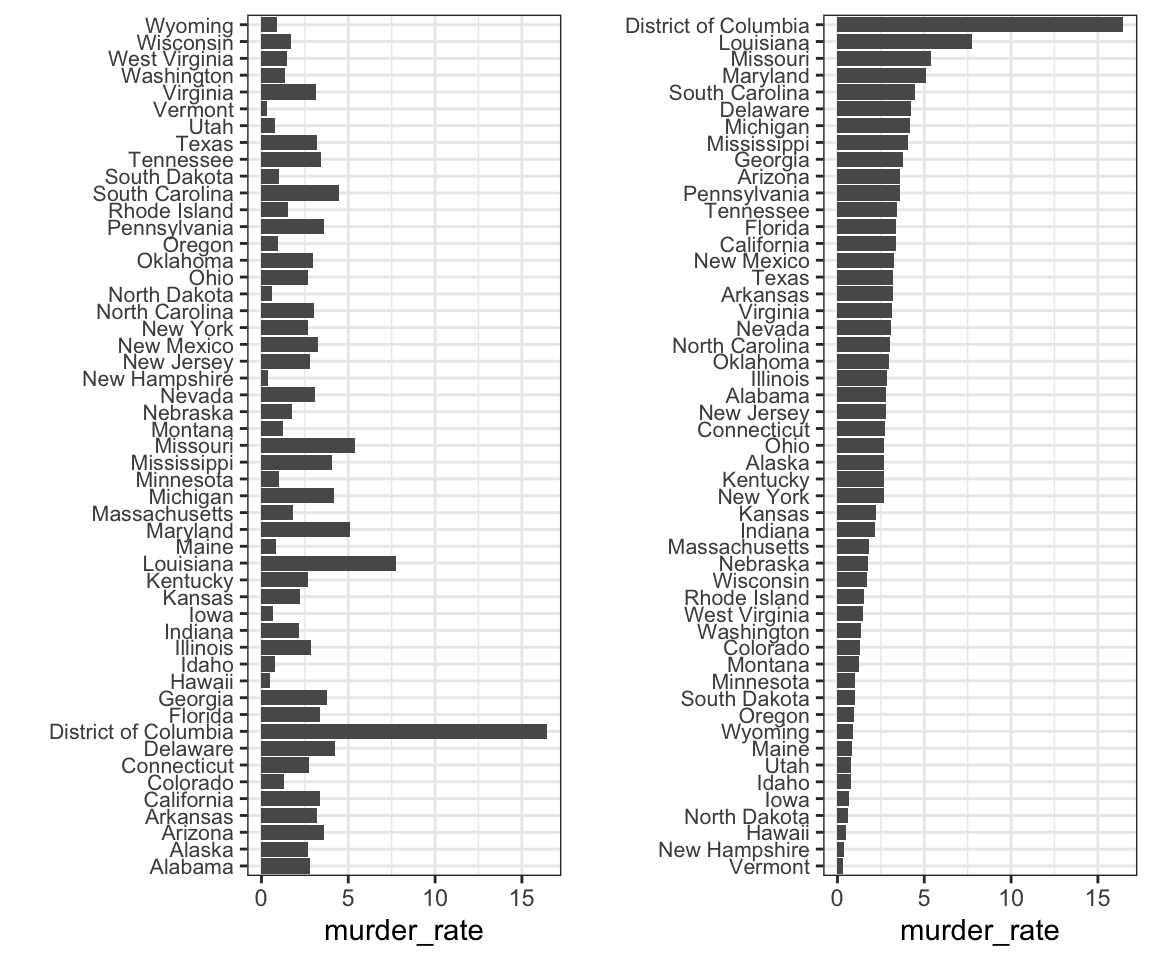
Podemos fazer o segundo gráfico desta forma:
data(murders)
murders %>% mutate(murder_rate = total/ population * 100000) %>%
mutate(state = reorder(state, murder_rate)) %>%
ggplot(aes(state, murder_rate)) +
geom_bar(stat="identity") +
coord_flip() +
theme(axis.text.y = element_text(size = 6)) +
xlab("")A função reorder também nos permite reordenar grupos. Anteriormente, vimos um exemplo relacionado à distribuição de renda entre regiões. Aqui vemos as duas versões representadas graficamente lado a lado:

O primeiro gráfico classifica as regiões em ordem alfabética, enquanto o segundo as classifica de acordo com a mediana do grupo.
10.5 Mostre os dados
Nós temos focando em exibir quantidades únicas em todas as categorias. Agora, voltamos nossa atenção para a visualização de dados, com foco na comparação de grupos.
Para motivar nosso primeiro princípio, “mostre os dados,” retornamos ao nosso exemplo artificial de descrição de alturas para ET, o extraterrestre. Desta vez, suponha que o ET esteja interessado nas diferenças de alturas entre homens e mulheres. Um gráfico comumente usado para comparações de grupos, popularizado por programas como o Microsoft Excel, é o gráfico de dinamite (dynamite plot), que mostra a média e o erro padrão (os erros padrão são definidos em um capítulo posterior, mas não os confundem com o desvio padrão de dados). O gráfico fica assim:
#> `summarise()` ungrouping output (override with `.groups` argument)
A média de cada grupo é representada pelo topo de cada barra e as antenas se estendem da média até mais dois erros padrão. Se tudo o que o ET receber for esse gráfico, ele terá poucas informações sobre o que esperar se encontrar um grupo de homens e mulheres. As barras iniciam em 0: isso significa que existem seres humanos pequenos com menos de 30 centímetros de altura? Todos os homens são mais altos mesmo comparados com as mulheres mais altas? Existe uma variedade de alturas? O ET é incapaz de responder a essas perguntas, pois mal lhe fornecemos informações sobre a distribuição de alturas.
Isso nos leva ao nosso primeiro princípio: exibir os dados. Este simples código do ggplot2 gera um gráfico mais informativo que o gráfico de barras, simplesmente exibindo todos os pontos de dados:
heights %>%
ggplot(aes(sex, height)) +
geom_point()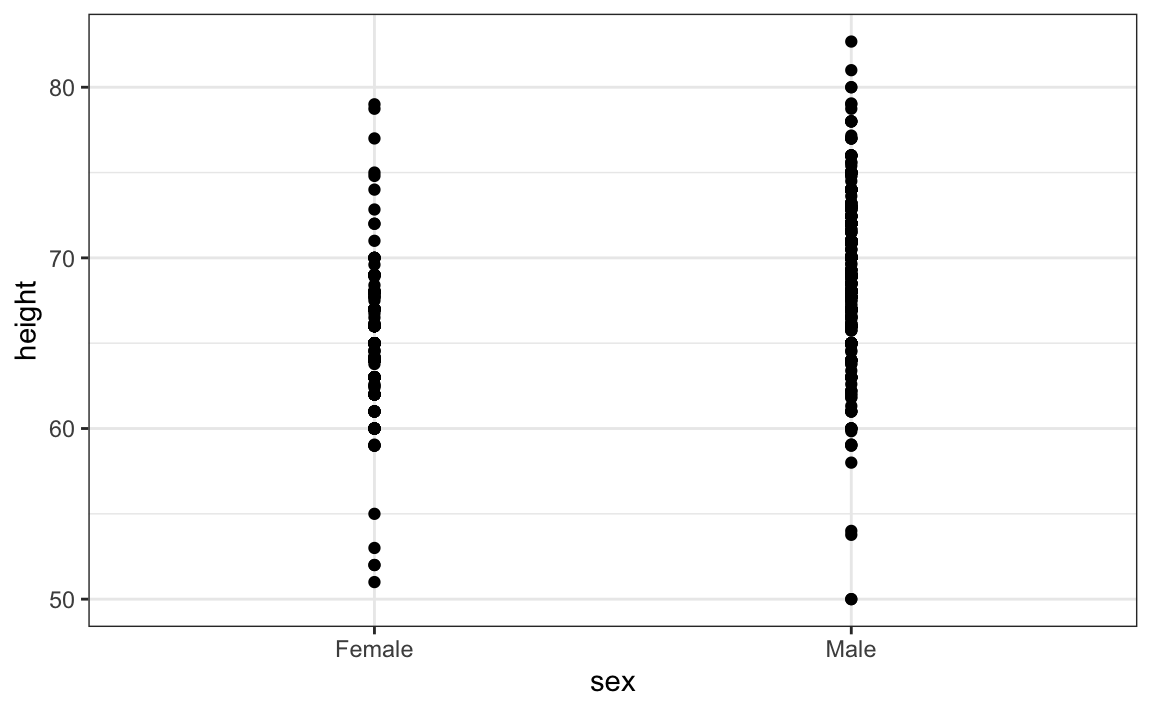
O gráfico acima nos dá uma ideia da variação dos dados. No entanto, esee gráfico também possui limitações, uma vez que não podemos realmente ver toda a soma de todos os FALSE, FALSE, FALSE, FALSE, FALSE, TRUE, TRUE, TRUE, TRUE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, TRUE, TRUE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, TRUE, FALSE, FALSE, FALSE, TRUE, TRUE, TRUE, FALSE, FALSE, TRUE, FALSE, TRUE, FALSE, FALSE, TRUE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, TRUE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, TRUE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, TRUE, FALSE, FALSE, TRUE, TRUE, FALSE, FALSE, FALSE, FALSE, TRUE, TRUE, FALSE, FALSE, FALSE, TRUE, FALSE, TRUE, FALSE, TRUE, TRUE, FALSE, FALSE, TRUE, TRUE, FALSE, FALSE, TRUE, FALSE, TRUE, TRUE, FALSE, TRUE, TRUE, FALSE, FALSE, TRUE, FALSE, FALSE, TRUE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, TRUE, TRUE, FALSE, FALSE, TRUE, TRUE, TRUE, FALSE, TRUE, TRUE, TRUE, FALSE, TRUE, FALSE, TRUE, FALSE, FALSE, FALSE, TRUE, FALSE, TRUE, TRUE, FALSE, FALSE, FALSE, FALSE, TRUE, FALSE, FALSE, TRUE, FALSE, TRUE, FALSE, FALSE, FALSE, FALSE, TRUE, TRUE, TRUE, TRUE, TRUE, TRUE, TRUE, FALSE, TRUE, TRUE, FALSE, FALSE, TRUE, TRUE, FALSE, FALSE, FALSE, FALSE, FALSE, TRUE, FALSE, FALSE, FALSE, FALSE, TRUE, FALSE, FALSE, FALSE, TRUE, TRUE, TRUE, FALSE, TRUE, FALSE, FALSE, TRUE, TRUE, TRUE, TRUE, FALSE, TRUE, FALSE, FALSE, TRUE, FALSE, FALSE, TRUE, FALSE, FALSE, FALSE, TRUE, FALSE, TRUE, FALSE, FALSE, FALSE, FALSE, TRUE, TRUE, FALSE, TRUE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, TRUE, TRUE, TRUE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, TRUE, FALSE, FALSE, TRUE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, TRUE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, TRUE, FALSE, TRUE, TRUE, TRUE, TRUE, FALSE, FALSE, TRUE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, TRUE, FALSE, FALSE, FALSE, FALSE, TRUE, TRUE, TRUE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, TRUE, FALSE, FALSE, TRUE, FALSE, FALSE, FALSE, TRUE, FALSE, FALSE, FALSE, TRUE, FALSE, FALSE, FALSE, FALSE, FALSE, TRUE, FALSE, FALSE, FALSE, FALSE, TRUE, FALSE, TRUE, FALSE, FALSE, FALSE, FALSE, TRUE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, TRUE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, TRUE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, TRUE, FALSE, FALSE, FALSE, FALSE, TRUE, FALSE, FALSE, FALSE, TRUE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, TRUE, TRUE, FALSE, FALSE, FALSE, FALSE, FALSE, TRUE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, TRUE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, TRUE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, TRUE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, TRUE, FALSE, FALSE, TRUE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, TRUE, FALSE, FALSE, FALSE, FALSE, TRUE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, TRUE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, TRUE, FALSE, FALSE, FALSE, FALSE, TRUE, TRUE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, TRUE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, TRUE, FALSE, TRUE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, TRUE, FALSE, FALSE, TRUE, FALSE, FALSE, FALSE, TRUE, FALSE, FALSE, TRUE, FALSE, TRUE, TRUE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, TRUE, TRUE, FALSE, FALSE, FALSE, TRUE, FALSE, FALSE, FALSE, TRUE, FALSE, FALSE, FALSE, TRUE, FALSE, TRUE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, TRUE, TRUE, TRUE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, TRUE, FALSE, FALSE, FALSE, TRUE, FALSE, FALSE, FALSE, FALSE, FALSE, TRUE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, TRUE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, TRUE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, TRUE, FALSE, FALSE, FALSE, FALSE, TRUE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, TRUE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, TRUE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, TRUE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, TRUE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, TRUE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, TRUE, TRUE, FALSE, TRUE, FALSE, FALSE, FALSE, FALSE, TRUE, TRUE, TRUE, TRUE, TRUE, TRUE, FALSE, FALSE, TRUE, TRUE, TRUE, FALSE, TRUE, TRUE, TRUE, FALSE, TRUE, TRUE, FALSE, FALSE, FALSE, TRUE, TRUE, TRUE, TRUE, TRUE, TRUE, TRUE, TRUE, TRUE, FALSE, TRUE, TRUE, TRUE, TRUE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, TRUE, FALSE, TRUE, FALSE, FALSE, FALSE, TRUE, FALSE, TRUE, FALSE, FALSE, FALSE, TRUE, TRUE, FALSE, FALSE, FALSE, TRUE, FALSE, TRUE, FALSE, TRUE, FALSE, FALSE, FALSE, FALSE, TRUE, FALSE, FALSE, TRUE, TRUE, FALSE, FALSE, TRUE, TRUE, TRUE, FALSE, TRUE, FALSE, TRUE, FALSE, TRUE, FALSE, FALSE, FALSE, TRUE, TRUE, TRUE, FALSE, FALSE, FALSE, TRUE, FALSE, FALSE, FALSE, FALSE, TRUE, FALSE, FALSE, TRUE, TRUE, FALSE, FALSE, TRUE, FALSE, FALSE, TRUE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, TRUE, TRUE, TRUE, FALSE, FALSE, FALSE, FALSE, TRUE, FALSE, TRUE, FALSE, FALSE, FALSE, FALSE, TRUE, FALSE, TRUE, FALSE, TRUE, TRUE, FALSE, FALSE, FALSE, FALSE, FALSE, TRUE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, TRUE, TRUE, TRUE, FALSE, FALSE, FALSE, FALSE, FALSE, TRUE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, TRUE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, TRUE, TRUE, FALSE, FALSE, FALSE, FALSE, TRUE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, TRUE, TRUE, TRUE, FALSE, FALSE, FALSE, TRUE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, TRUE, FALSE, FALSE, TRUE, FALSE, FALSE, TRUE, FALSE, FALSE, FALSE, FALSE, TRUE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, TRUE, FALSE, FALSE, FALSE, FALSE, FALSE, TRUE, FALSE, FALSE, TRUE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, TRUE, FALSE, FALSE, FALSE, FALSE e 812 pontos plotados para mulheres e homens, respectivamente, e muitos pontos são plotados um sobre o outro. Como descrevemos anteriormente, visualizar a distribuição é muito mais informativo. Porém, antes de fazer isso, podemos apontar duas maneiras de melhorar um gráfico que mostra todos os pontos.
A primeira é adicionar jitter, que adiciona um pequeno deslocamento aleatório a cada ponto. Nesse caso, adicionar jitter horizontal não altera a interpretação, pois as alturas dos pontos não mudam. Além disso, minimizamos o número de pontos que se sobrepõem e, assim, temos uma melhor ideia visual de como os dados estão distribuídos. Uma segunda melhoria vem do uso de alpha blending, que torna os pontos um pouco transparentes. Quanto mais pontos se sobrepuserem, mais escuro será o gráfico, o que também nos ajudará a ter uma ideia de como os pontos estão distribuídos. Aqui está o mesmo gráfico com jitter e alpha blending aplicados:
heights %>%
ggplot(aes(sex, height)) +
geom_jitter(width = 0.1, alpha = 0.2)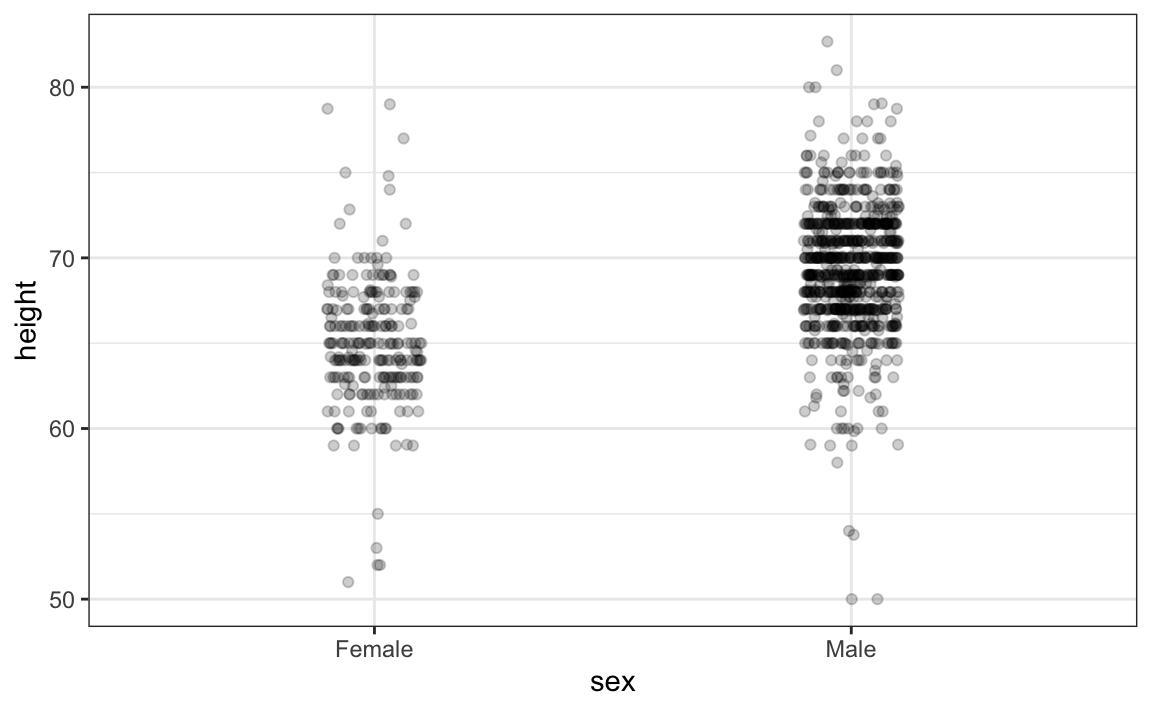
Agora começamos a sentir que, em média, os homens são mais altos que as mulheres. Também observamos faixas horizontais de pontos mais escuras, demonstrando que muitos valores relatados foram arredondados para o número inteiro mais próximo.
10.6 Facilite comparações
10.6.1 Use eixos em comum
Uma vez que existem muitos pontos, é mais eficaz mostrar distribuições do que pontos individuais. Portanto, mostramos histogramas para cada grupo:
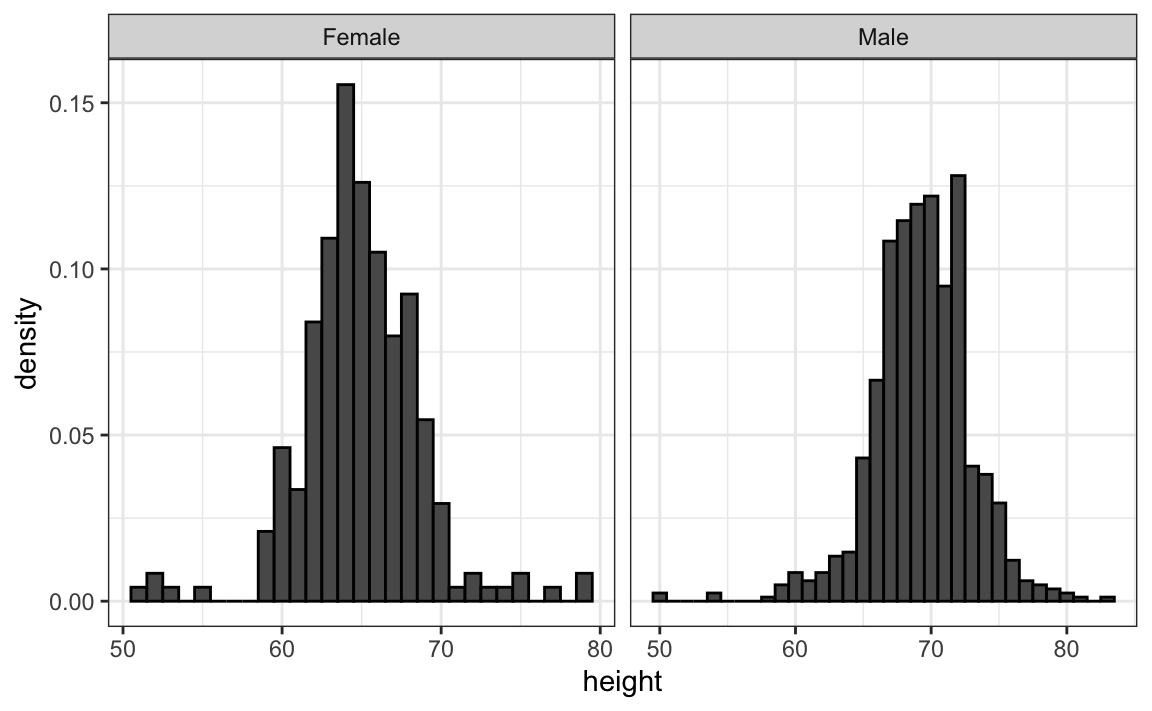
No entanto, olhando para o gráfico acima, não é imediatamente óbvio que homens são, em média, mais altos que mulheres. Temos que observar com atenção para perceber que o eixo x tem uma faixa de valores mais alta no histograma masculino. Um princípio importante aqui é manter os eixos iguais ao comparar dados em dois gráficos. A seguir, vemos como a comparação se torna mais fácil:
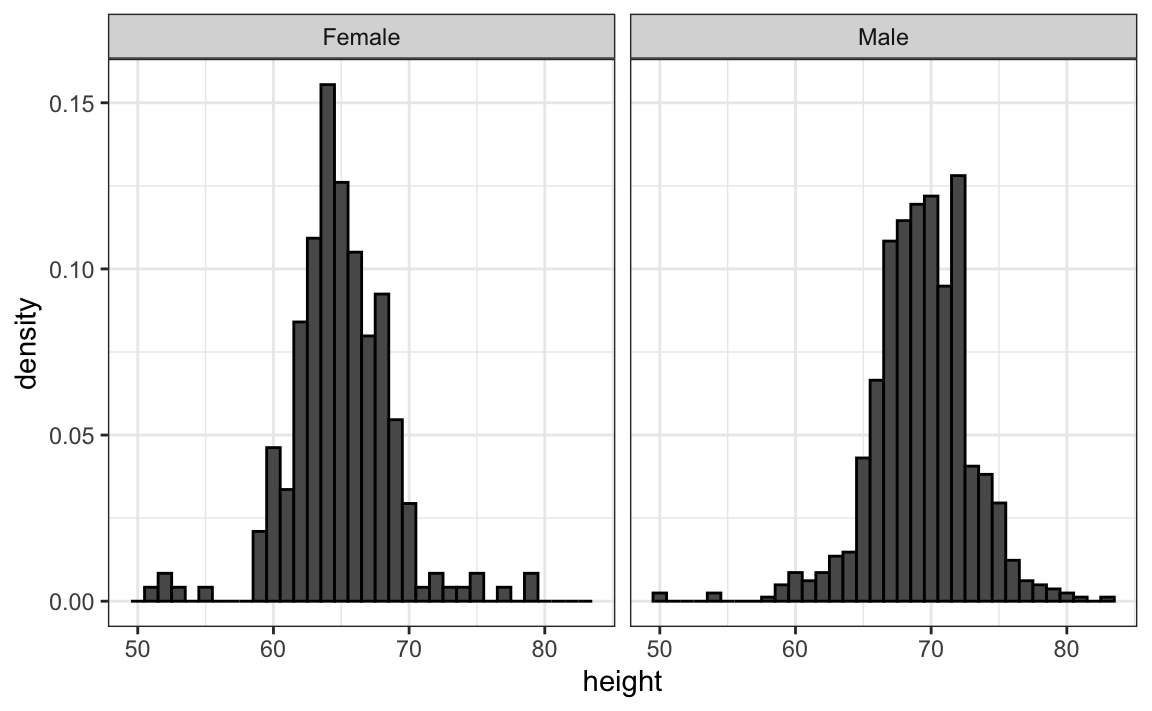
10.6.2 Alinhe os gráficos verticalmente para ver alterações horizontais e horizontalmente para ver alterações verticais
Nesses histogramas, o sinal visual relacionado a reduções ou aumentos de altura são deslocamentos para a esquerda ou para a direita, respectivamente: alterações horizontais. O alinhamento vertical dos gráficos nos ajuda a ver essa alteração quando os eixos são fixos:
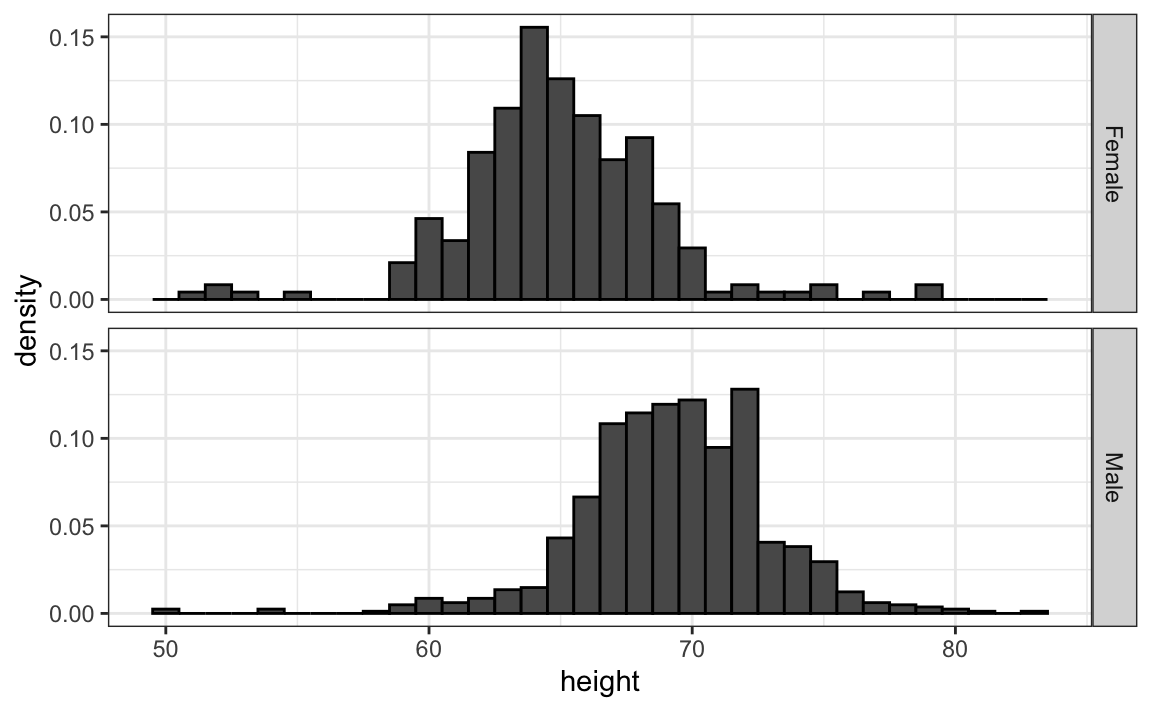
heights %>%
ggplot(aes(height, ..density..)) +
geom_histogram(binwidth = 1, color="black") +
facet_grid(sex~.)O gráfico acima facilita notar que homens são, em média, mais altos.
Se quisermos obter o resumo compacto que os boxplots oferecem, precisamos alinhá-los horizontalmente, uma vez que, por padrão, os boxplots se movem para cima e para baixo com base nas mudanças de altura. Seguindo o princípio “mostre os dados,” devemos sobrepor todos os pontos de dados:
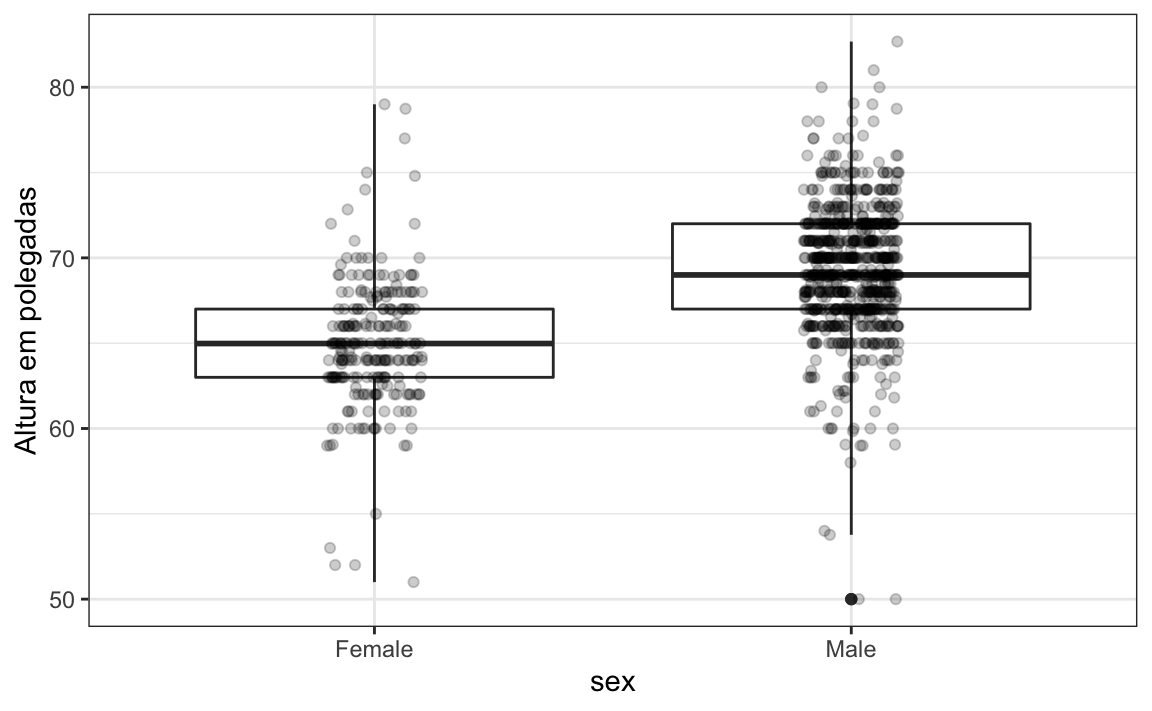
heights %>%
ggplot(aes(sex, height)) +
geom_boxplot(coef=3) +
geom_jitter(width = 0.1, alpha = 0.2) +
ylab("Altura em polegadas")Agora compare e contraste estes três gráficos baseados exatamente nos mesmos dados:
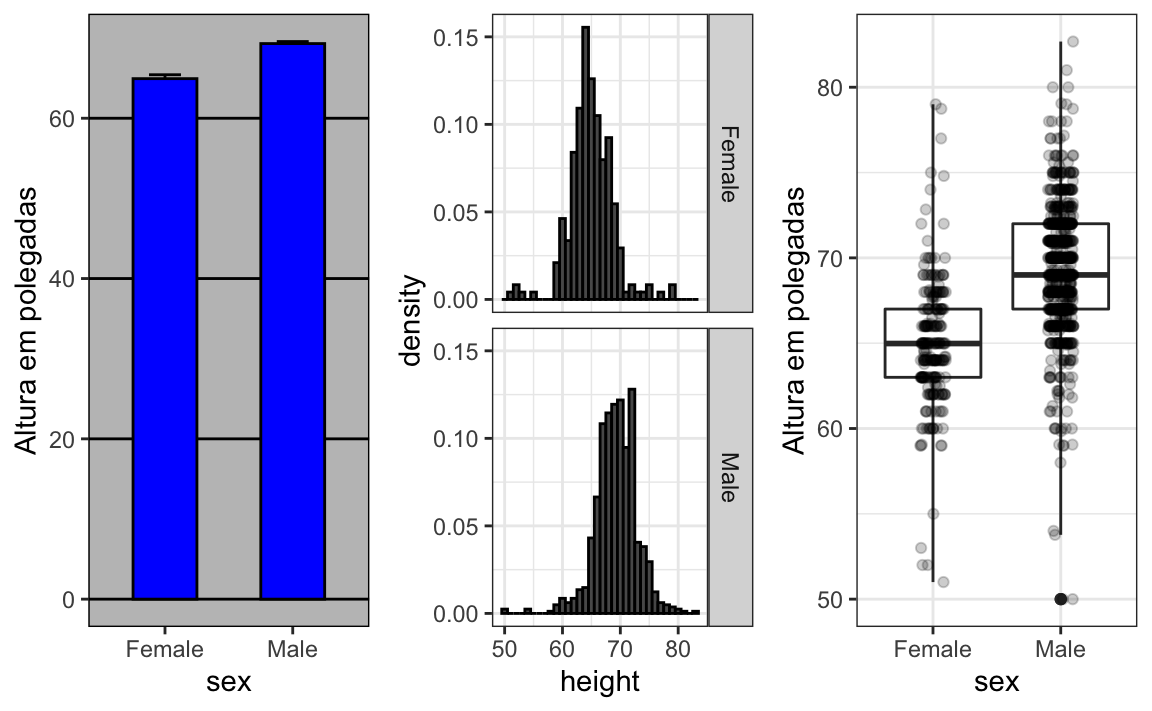
Observe o quanto aprendemos mais nos dois gráficos à direita. Os gráficos de barras são úteis para exibir um número, mas não são muito úteis quando queremos descrever distribuições.
10.6.3 Considere transformações
Incentivamos o uso de transformação logarítmica nos casos em que as mudanças são multiplicativas. O tamanho da população foi um exemplo em que estabelecemos uma transformação logarítmica para produzir uma transformação mais informativa.
A combinação de um gráfico de barras escolhido incorretamente e a não utilização de uma transformação logarítmica, quando necessária, podem particularmente causar distorções. Como exemplo, considere este gráfico de barras mostrando os tamanhos médios da população para cada continente em 2015:
#> `summarise()` ungrouping output (override with `.groups` argument)![]()
Observando o gráfico acima, conclui-se que os países asiáticos são muito mais populosos do que os de outros continentes. Seguindo o princípio “mostre os dados,” notamos rapidamente que isso se deve a dois países muito grandes, que presumimos serem a Índia e a China:
![]()
Usar uma transformação logarítmica aqui produz um gráfico muito mais informativo. Comparamos o gráfico de barras original com um boxplot usando a transformação de escala logarítmica para o eixo y:
![]()
Com o novo gráfico, percebemos que os países africanos realmente têm uma população mediana maior que os da Ásia.
Outras transformações a considerar são a transformação logística (logit), que é útil para ver melhor as alterações nas probabilidades e a transformação da raiz quadrada ( sqrt), que é útil para contagens.
10.6.4 As indicações visuais comparadas devem ser adjacentes
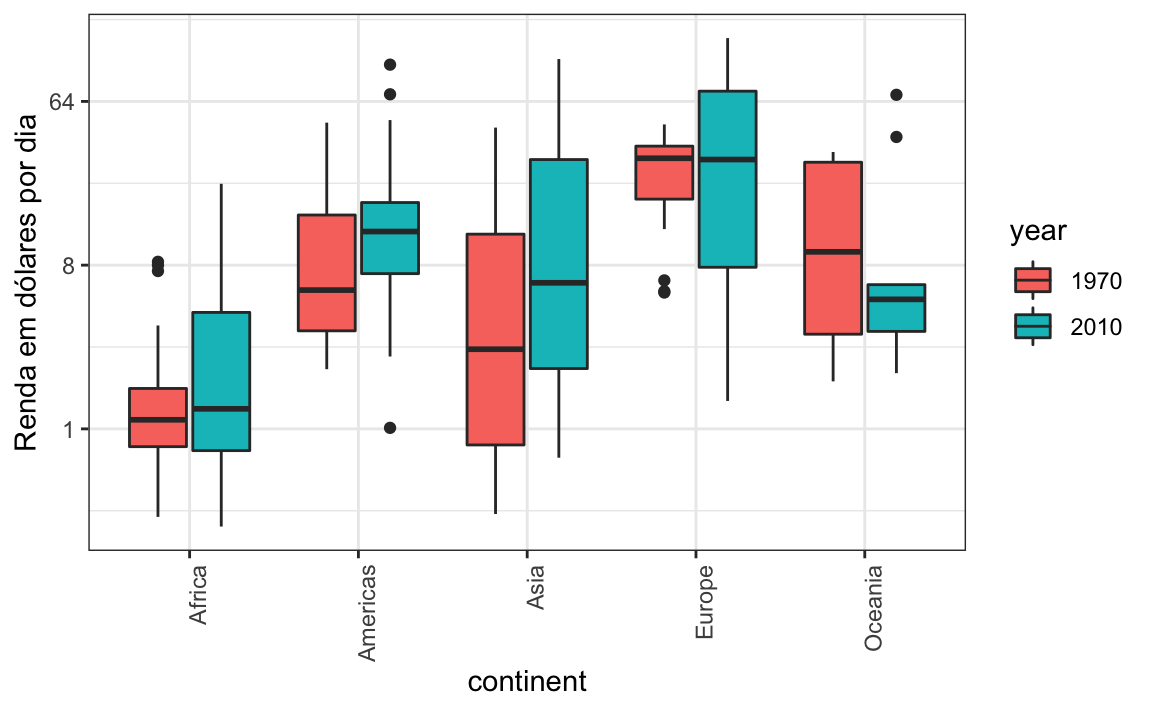
Para cada continente, vamos comparar a renda em 1970 versus 2010. Quando comparamos dados de renda por regiões entre 1970 e 2010, construímos um gráfico semelhante à figura abaixo. Desta vez, investigamos os continentes em vez de regiões.
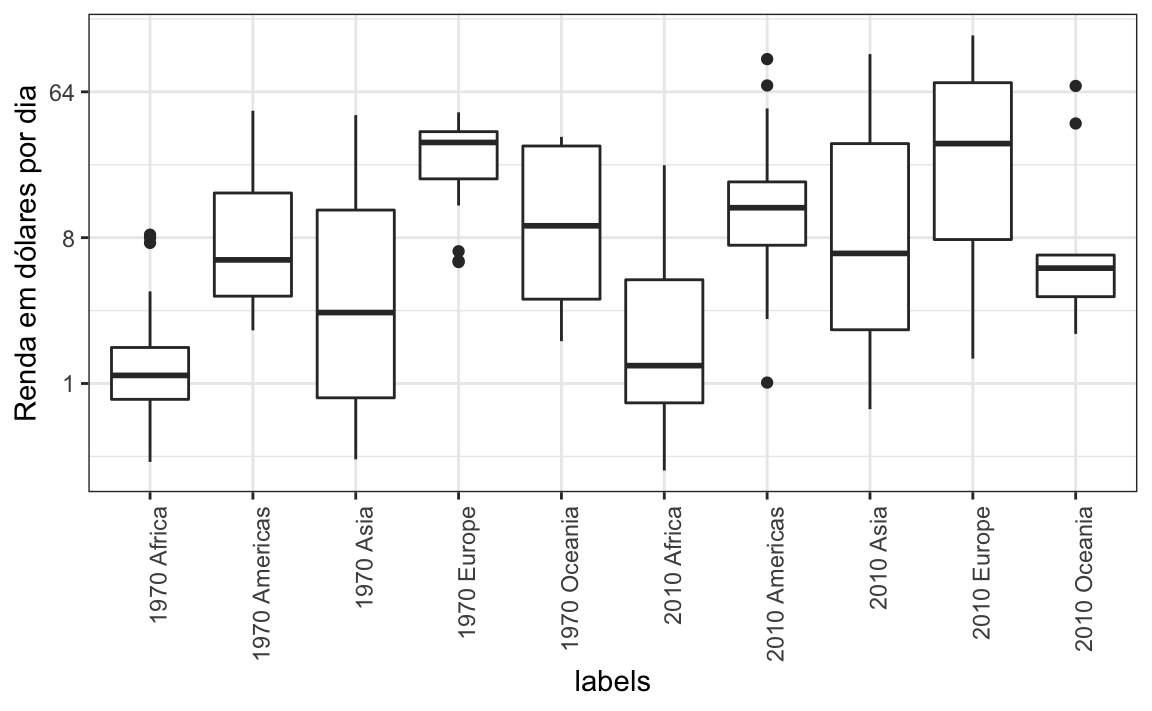
O comportamento padrão do ggplot2 é classificar os rótulos em ordem alfabética de modo que os rótulos com 1970 venham antes dos rótulos com 2010. Isso dificulta as comparações porque a distribuição de um continente em 1970 é visualmente distante da sua distribuição em 2010. É muito mais fácil fazer a comparação entre 1970 e 2010 para cada continente quando seus boxplots estiverem lado a lado:
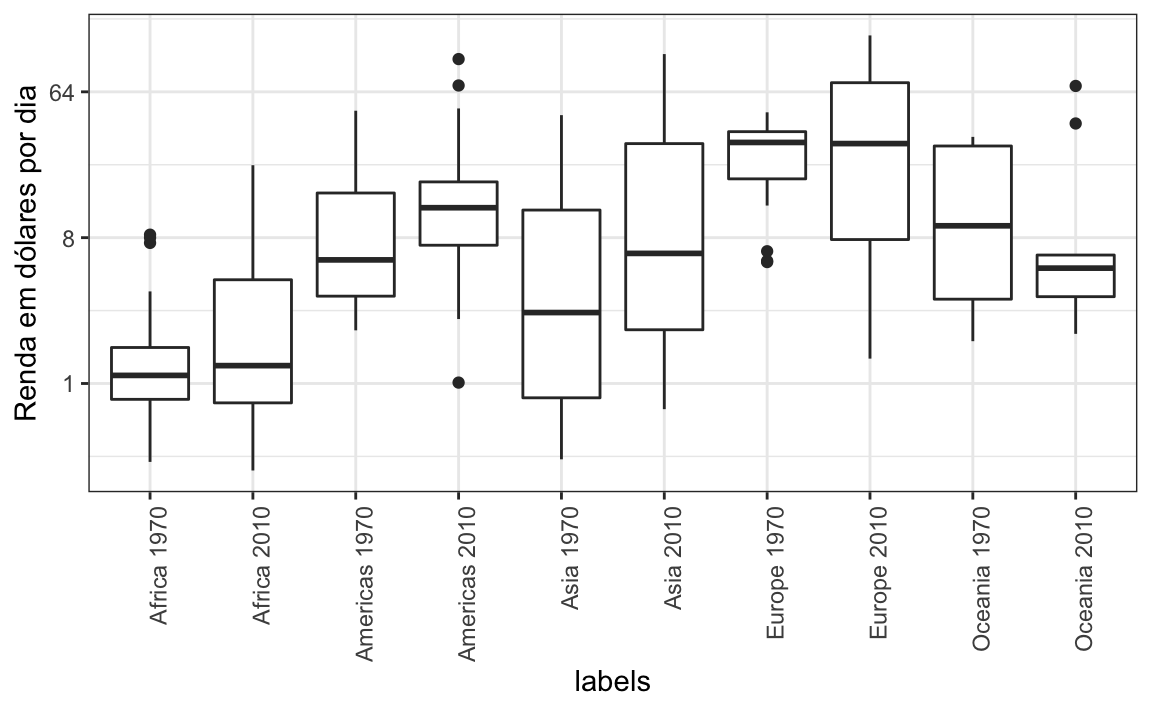
10.6.5 Use cores
A comparação é ainda mais fácil se usarmos cores para indicar as duas coisas que queremos comparar:
10.7 Pense no daltônico
Cerca de 10% da população é daltônica. Infelizmente, as cores padrão usadas em ggplot2 não são ideais para esse grupo. No entanto, ggplot2 facilita a alteração da paleta de cores usada nos gráficos. Aqui está um exemplo de como podemos usar uma paleta que considera daltônicos: http://www.cookbook-r.com/Graphs/Colors_(ggplot2)/#a-colorblind-friendly-palette:
color_blind_friendly_cols <-
c("#999999", "#E69F00", "#56B4E9", "#009E73",
"#F0E442", "#0072B2", "#D55E00", "#CC79A7")Aqui estão as cores:

Além disso, existem vários recursos que podem ajudá-lo a selecionar cores, por exemplo, este: http://bconnelly.net/2013/10/creating-colorblind-friendly-figures/.
10.8 Plotagens para duas variáveis
Em geral, deve-se usar gráficos de dispersão para visualizar o relacionamento entre duas variáveis. Em todos os casos em que examinamos a relação entre duas variáveis, incluindo assassinatos totais versus tamanho da população, expectativa de vida versus taxas de fertilidade e mortalidade infantil versus renda, usamos gráficos de dispersão. Esse é o gráfico que geralmente recomendamos. Entretanto, existem algumas exceções e aqui descrevemos dois gráficos alternativos: o gráfico de inclinação (slope chart) e o gráfico de Bland-Altman (Bland-Altman plot).
10.8.1 Gráficos de inclinação
Uma exceção onde outro tipo de gráfico pode ser mais informativo é quando compara-se variáveis do mesmo tipo, mas em momentos diferentes e para um número relativamente pequeno de comparações. Por exemplo, se estivermos comparando a expectativa de vida entre 2010 e 2015. Nesse caso, poderíamos recomendar um gráfico de inclinação.
Não há geometria para gráficos de inclinação no ggplot2, mas podemos construir um usando geom_line. Precisamos apenas fazer alguns ajustes para adicionar os rótulos. Abaixo, é apresentado um exemplo comparando a expectativa de vida de 2010 a 2015 para os grandes países ocidentais:
west <- c("Western Europe","Northern Europe","Southern Europe",
"Northern America","Australia and New Zealand")
dat <- gapminder %>%
filter(year%in% c(2010, 2015) & region %in% west &
!is.na(life_expectancy) & population > 10^7)
dat %>%
mutate(location = ifelse(year == 2010, 1, 2),
location = ifelse(year == 2015 &
country %in% c("United Kingdom", "Portugal"),
location+0.22, location),
hjust = ifelse(year == 2010, 1, 0)) %>%
mutate(year = as.factor(year)) %>%
ggplot(aes(year, life_expectancy, group = country)) +
geom_line(aes(color = country), show.legend = FALSE) +
geom_text(aes(x = location, label = country, hjust = hjust),
show.legend = FALSE) +
xlab("") + ylab("Expectativa de Vida")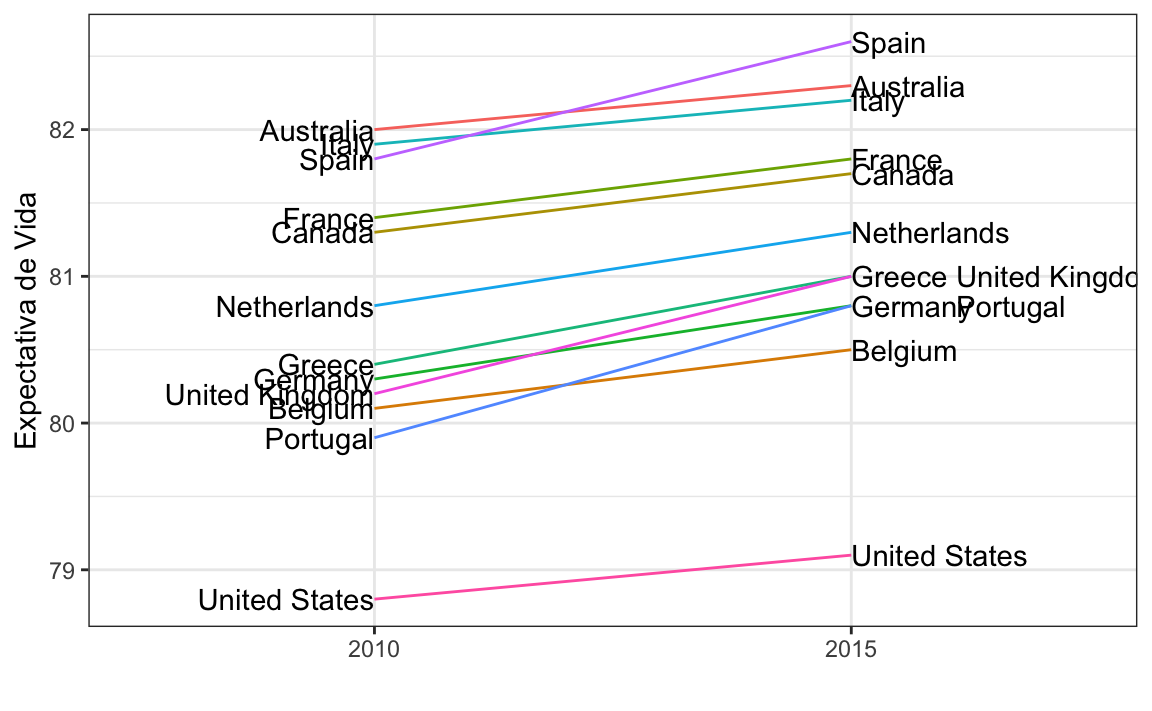
Uma vantagem do gráfico de inclinação é que ele rapidamente nos dá uma ideia das mudanças com base na inclinação das linhas. Embora estejamos usando o ângulo como uma sugestão visual, também estamos usando a posição para determinar valores exatos. Comparar melhorias é um pouco mais difícil com um gráfico de dispersão:
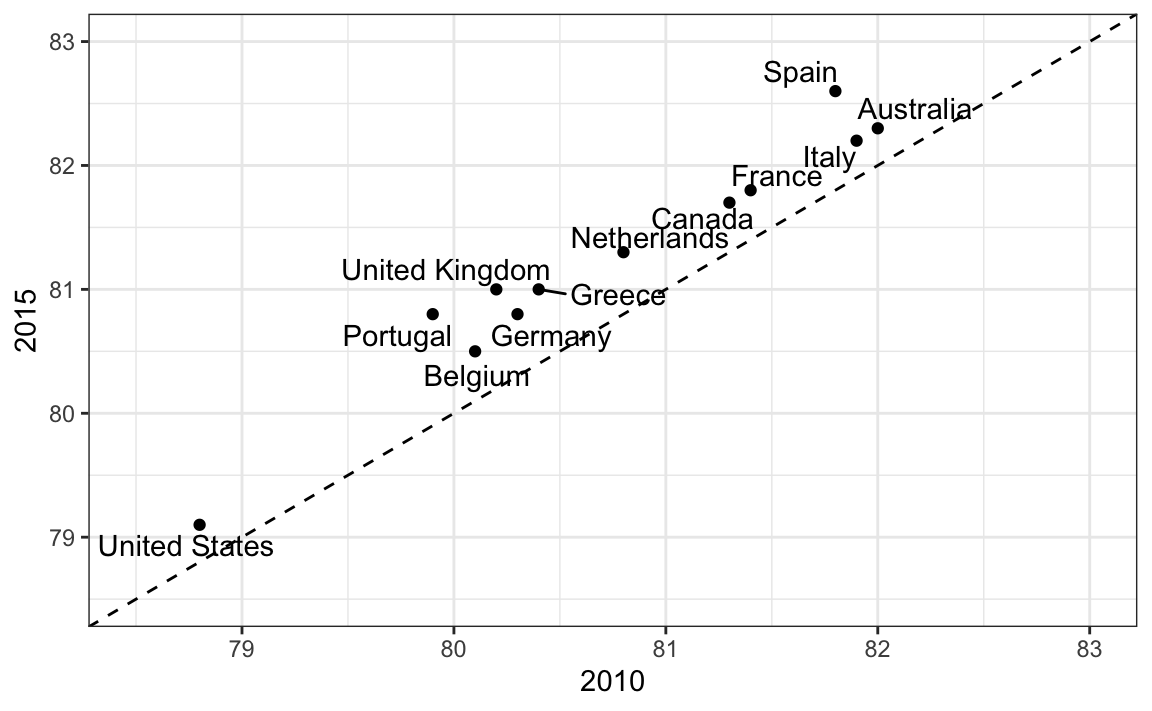
No gráfico de dispersão, seguimos o princípio use eixos comuns, uma vez que estamos comparando antes e depois. No entanto, se tivermos muitos pontos, os gráficos de inclinação deixam de ser úteis, pois se torna difícil ver todas as linhas.
10.8.2 Gráfico de Bland-Altman
Como estamos interessados principalmente na diferença, faz sentido dedicar um de nossos eixos a ela. O gráfico de Bland-Altman, também conhecido como gráfico de diferença média de Tukey ou MA plot, mostra a diferença em relação à média:
library(ggrepel)
dat %>%
mutate(year = paste0("life_expectancy_", year)) %>%
select(country, year, life_expectancy) %>%
spread(year, life_expectancy) %>%
mutate(average = (life_expectancy_2015 + life_expectancy_2010)/2,
difference = life_expectancy_2015 - life_expectancy_2010) %>%
ggplot(aes(average, difference, label = country)) +
geom_point() +
geom_text_repel() +
geom_abline(lty = 2) +
xlab("Média de 2010 e 2015") +
ylab("Diferença entre 2015 e 2010")
Aqui, simplesmente olhando o eixo y, vemos rapidamente quais países mostraram a maior melhoria. Além disso, temos uma ideia do valor geral do eixo x.
10.9 Codificando uma terceira variável
Um gráfico de dispersão, apresentado anteriormente, mostrou a relação entre sobrevivência infantil e renda média. Abaixo está uma versão desse gráfico que codifica três variáveis: participação na OPEP (Organização dos Países Exportadores de Petróleo), região e população.

Codificamos variáveis categóricas com cor e forma. Essas formas podem ser controladas com o argumento shape. Abaixo, mostramos as formas disponíveis para uso no R. Para as últimas cinco, cores podem ser usadas para preencher o interior da forma.

Para variáveis contínuas, podemos usar cor, intensidade ou tamanho. Aqui está um exemplo de como fazer isso com um estudo de caso.
Ao selecionar cores para quantificar uma variável numérica, escolhemos entre duas opções: sequencial ou divergente. Cores sequenciais são adequadas para dados que variam do mais alto ao mais baixo. Valores altos são claramente diferenciados de valores baixos. Aqui estão alguns exemplos oferecidos pelo pacote RColorBrewer:
library(RColorBrewer)
display.brewer.all(type="seq")
Cores divergentes são usadas para representar valores que divergem de um centro. Colocamos ênfase igual nos dois extremos do intervalo de dados: mais alto que o centro e mais baixo que o centro. Um exemplo de quando usaríamos um padrão divergente seria se tivéssemos que mostrar a altura em desvios-padrão da média. Aqui estão alguns exemplos de padrões divergentes:
library(RColorBrewer)
display.brewer.all(type="div")
10.10 Evite gráficos pseudo-tridimensionais
A figura a seguir, extraída da literatura científica41, mostra três variáveis: dose, tipo de medicamento e sobrevida. Embora telas ou páginas de livro sejam planas e bidimensionais, o gráfico tenta imitar três dimensões, atribuindo uma dimensão para cada variável.
 (Imagem cortesia de Karl Broman)
(Imagem cortesia de Karl Broman)
Seres humanos não são bons em ver em três dimensões (o que explica por que é tão difícil realizar uma baliza para estacionar). Nossa limitação é ainda pior em relação aos espaços pseudo-tridimensionais. Para ver isso, tente determinar os valores da variável de sobrevivência no gráfico acima. Você pode dizer quando a fita roxa intercepta a fita vermelha? Abaixo está um exemplo em que podemos facilmente usar cores para representar a variável categórica em vez de um pseudo-3D:
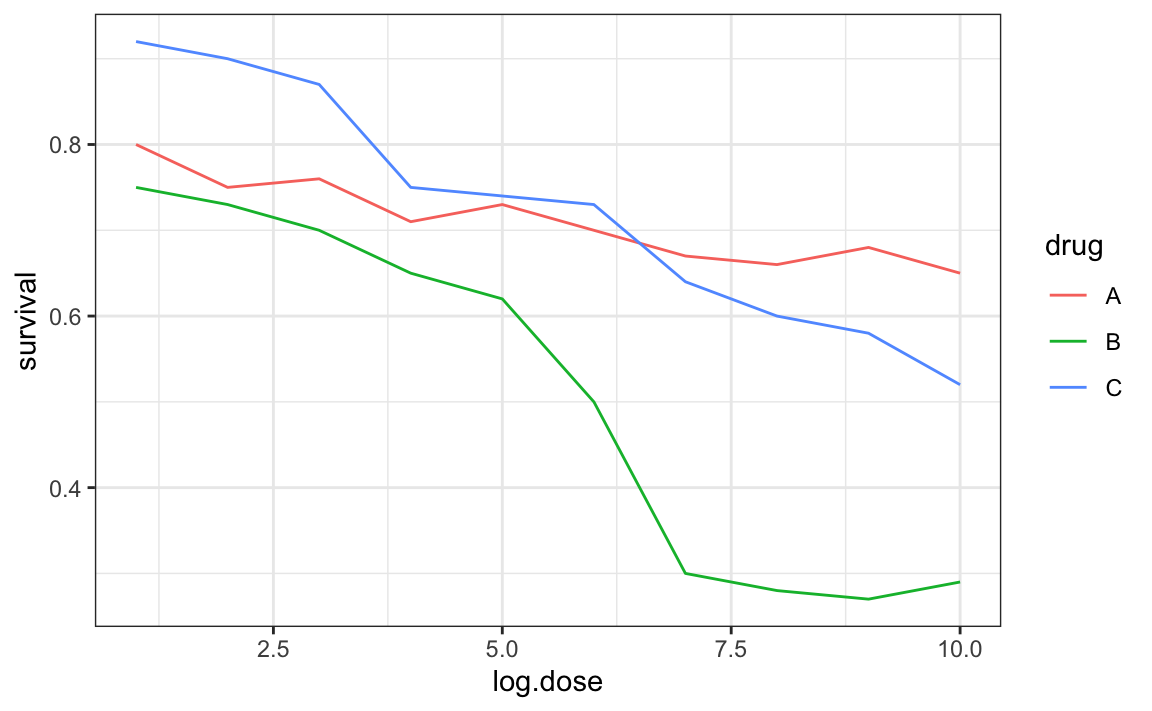
Note como é mais fácil determinar os valores de sobrevivência.
Às vezes, o pseudo-3D é usado de forma totalmente gratuita: os gráficos são criados para parecer 3D, mesmo quando a terceira dimensão não representa uma quantidade. Isso apenas aumenta a confusão e torna mais difícil transmitir sua mensagem. Aqui estão dois exemplos:

 (Imagens cortesia de Karl Broman)
(Imagens cortesia de Karl Broman)
10.11 Evite muitos dígitos significativos
Por padrão, softwares estatísticos como R retornam muitos dígitos significativos. O comportamento padrão do R é exibir 7 dígitos significativos. Esse número de dígitos geralmente não adiciona informações e a desordem visual adicionada pode dificultar o entendimento da mensagem. Como exemplo, aqui estão as taxas de doenças por 10.000 habitantes para a Califórnia em cinco décadas, calculadas a partir dos totais e da população com R:
| state | year | Measles | Pertussis | Polio |
|---|---|---|---|---|
| California | 1940 | 37.8826320 | 18.3397861 | 0.8266512 |
| California | 1950 | 13.9124205 | 4.7467350 | 1.9742639 |
| California | 1960 | 14.1386471 | NA | 0.2640419 |
| California | 1970 | 0.9767889 | NA | NA |
| California | 1980 | 0.3743467 | 0.0515466 | NA |
(Measles: Sarampo, Pertussis: Coqueluche, Polio: Poliomielite)
Nesse caso, estamos relatando precisão de até 0,00001 casos por 10.000, um valor muito pequeno no contexto das mudanças que estão ocorrendo nas datas. Nesse caso, dois algarismos significativos são mais do que suficientes e deixam claro que as taxas estão diminuindo:
| state | year | Measles | Pertussis | Polio |
|---|---|---|---|---|
| California | 1940 | 37.9 | 18.3 | 0.8 |
| California | 1950 | 13.9 | 4.7 | 2.0 |
| California | 1960 | 14.1 | NA | 0.3 |
| California | 1970 | 1.0 | NA | NA |
| California | 1980 | 0.4 | 0.1 | NA |
Para alterar o número de dígitos significativos ou números redondos, usamos signif e round. Você pode definir globalmente o número de dígitos significativos, configurando as opções desta forma: options(digits = 3).
Outro princípio relacionado à exibição de tabelas é colocar os valores que são comparados em colunas em vez de linhas. Observe que nossa tabela acima é mais fácil de ler do que esta:
| state | disease | 1940 | 1950 | 1960 | 1970 | 1980 |
|---|---|---|---|---|---|---|
| California | Measles | 37.9 | 13.9 | 14.1 | 1 | 0.4 |
| California | Pertussis | 18.3 | 4.7 | NA | NA | 0.1 |
| California | Polio | 0.8 | 2.0 | 0.3 | NA | NA |
10.12 Conheça seu público
Fráficos podem ser usados para: (1) nossas próprias análises exploratórias de dados, (2) para transmitir uma mensagem a especialistas, ou (3) para ajudar a contar uma história para o público em geral. Logo, certifique-se de que o público-alvo entenda cada elemento do gráfico.
Como um simples exemplo, considere que, para sua própria exploração, pode ser mais útil transformar os dados logaritmicamente e depois plotá-los. No entanto, para uma audiência geral que não está familiarizada com a conversão de valores logarítmicos em medições originais, será muito mais fácil entender o uso de uma escala logarítmica para o eixo, em vez de valores transformados logaritmicamente.
10.13 Exercícios
Para esses exercícios, usaremos os dados de vacinas do pacote dslabs:
library(dslabs)
data(us_contagious_diseases)1. Os gráficos de pizza são adequados:
- Quando queremos mostrar porcentagens.
- Quando ggplot2 não estiver disponível.
- Quando estou em uma pizzaria.
- Nunca. Gráficos de barras e tabelas são sempre melhores.
2. Qual é o problema com o gráfico abaixo:
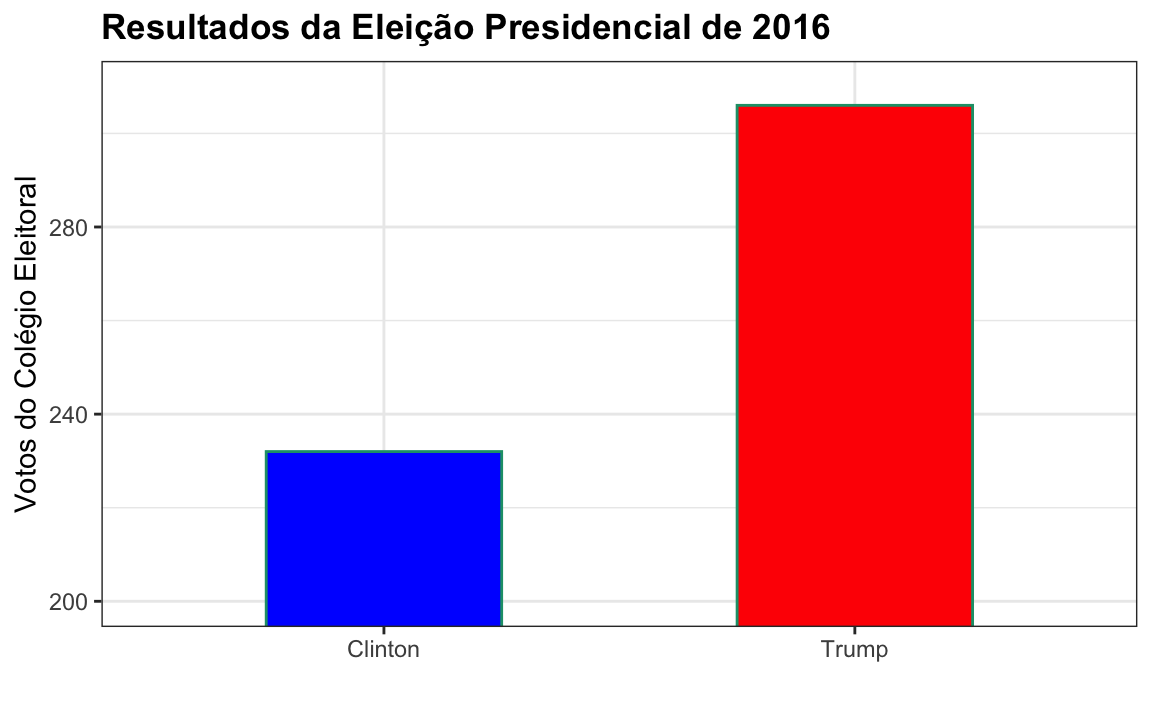
- Os valores estão errados. A votação final foi 306-232.
- O eixo não começa em 0. A julgar pelo comprimento, parece que Trump recebeu três vezes mais votos quando, na verdade, recebeu aproximadamente 30% a mais.
- As cores devem ser as mesmas.
- As porcentagens devem ser mostradas como um gráfico de pizza.
3. Veja os dois gráficos a seguir. Eles mostram a mesma informação: taxas de sarampo em 1928 em todos os 50 estados dos EUA.
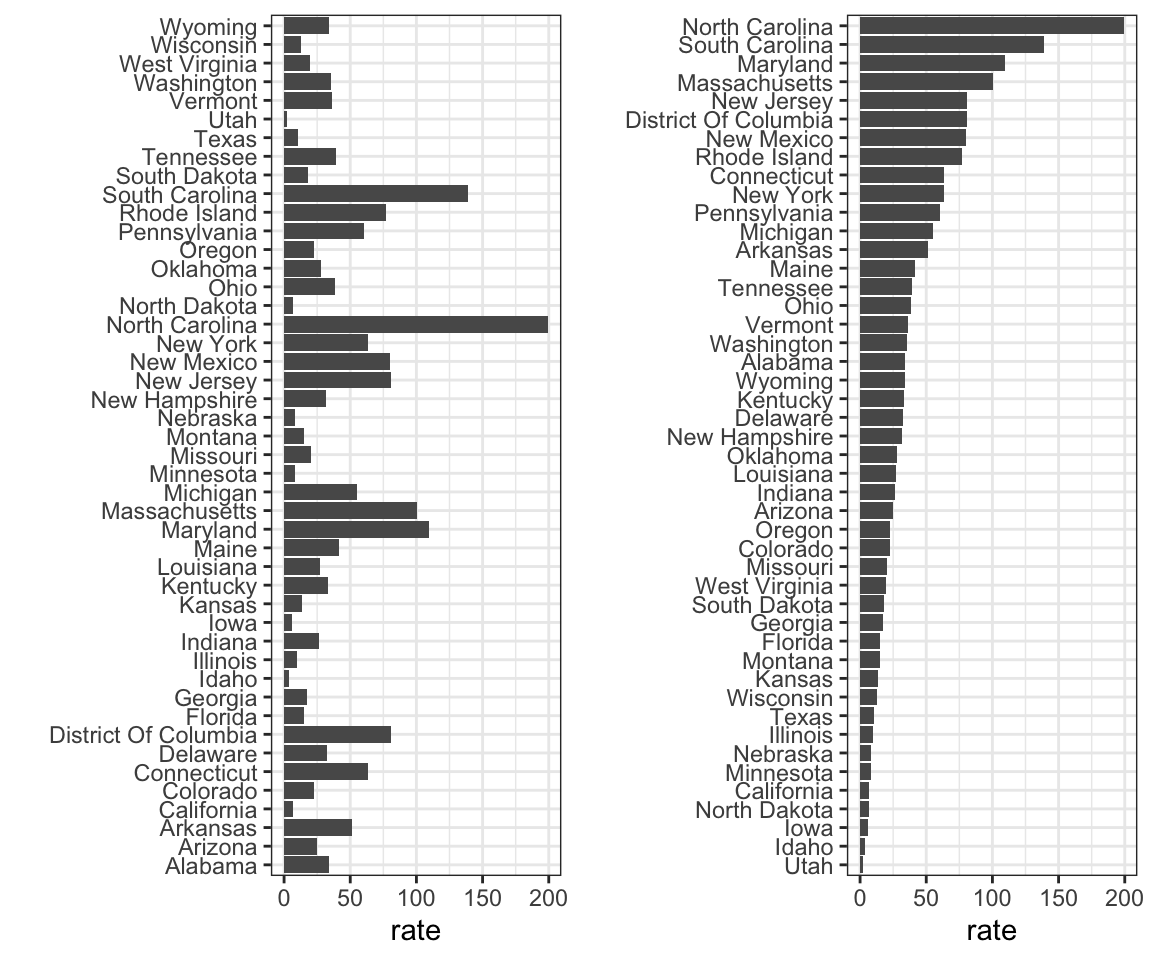 Qual gráfico é mais fácil de ler se você deseja determinar quais são os melhores e os piores estados em termos de taxas? Por quê?
Qual gráfico é mais fácil de ler se você deseja determinar quais são os melhores e os piores estados em termos de taxas? Por quê?
- Eles dão a mesma informação, então ambos são igualmente bons.
- O gráfico à esquerda é melhor porque ordena os estados em ordem alfabética.
- O gráfico à direita é melhor porque a ordem alfabética não tem nada a ver com a doença e, ordenando de acordo com a taxa real, vemos rapidamente os estados com as taxas mais altas e mais baixas.
- Ambos os gráficos deveriam ser um gráfico de pizza.
4. Para fazer o gráfico à esquerda, precisamos reordenar os níveis das variáveis dos estados.
dat <- us_contagious_diseases %>%
filter(year == 1967 & disease=="Measles" & !is.na(population)) %>%
mutate(rate = count/ population * 10000 * 52/ weeks_reporting)Note o que acontece quando criamos um gráfico de barras:
dat %>% ggplot(aes(state, rate)) +
geom_bar(stat="identity") +
coord_flip()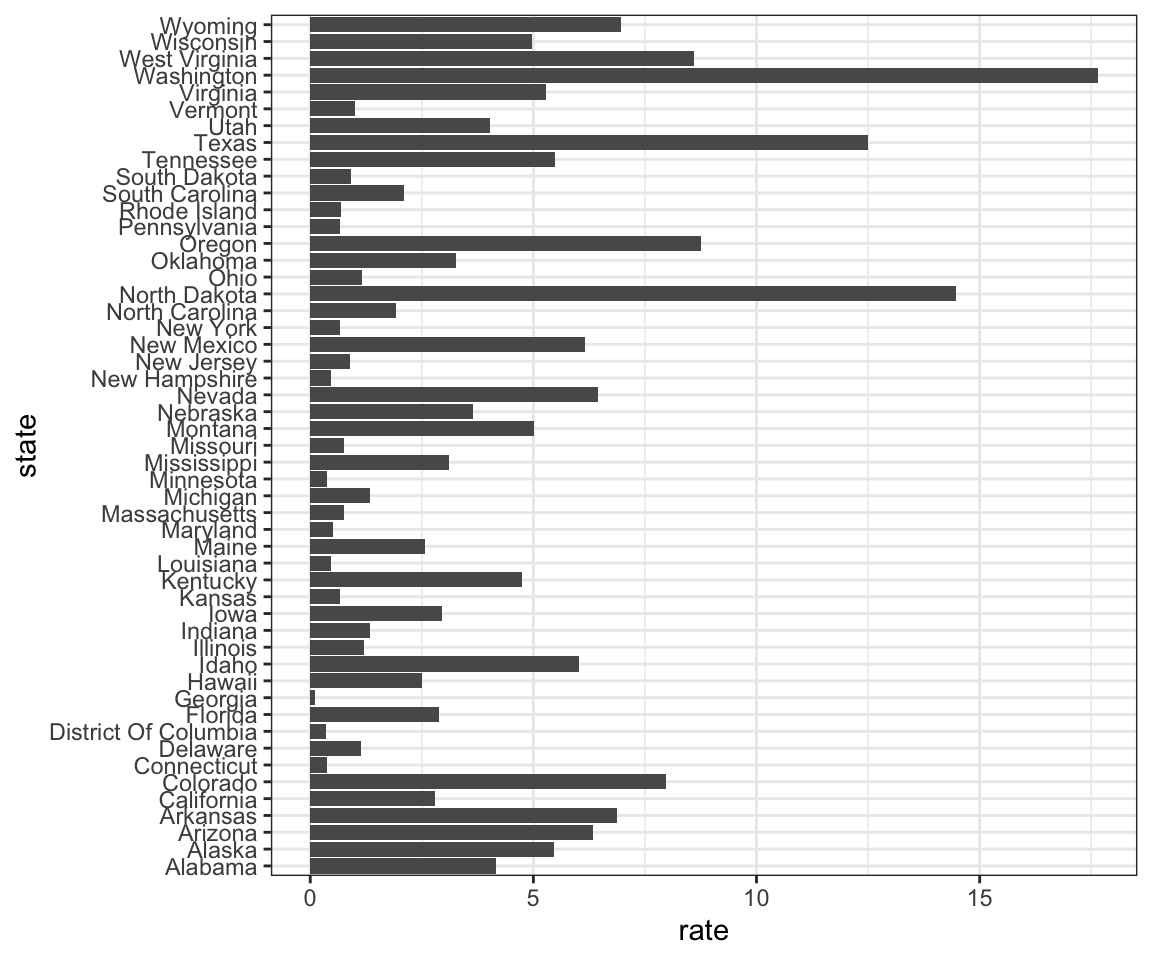
Defina estes objetos:
state <- dat$state
rate <- dat$count/dat$population*10000*52/dat$weeks_reportingRedefina o objeto state para que os níveis sejam reorganizados. Imprima o novo objeto state e seus níveis para que você possa ver que os níveis não reorganizam o vetor.
5. Agora, edite o código acima redefinindo dat para que os níveis da variável state sejam reordenados pela variável rate. Em seguida, faça um gráfico de barras usando o código acima, mas para este novo dat.
6. Digamos que você esteja interessado em comparar as taxas de homicídio por arma de fogo em todas as regiões dos EUA. Ao ver este gráfico:
library(dslabs)
data("murders")
murders %>% mutate(rate = total/population*100000) %>%
group_by(region) %>%
summarize(avg = mean(rate)) %>%
mutate(region = factor(region)) %>%
ggplot(aes(region, avg)) +
geom_bar(stat="identity") +
ylab("Média da taxa de homicídio")
#> `summarise()` ungrouping output (override with `.groups` argument)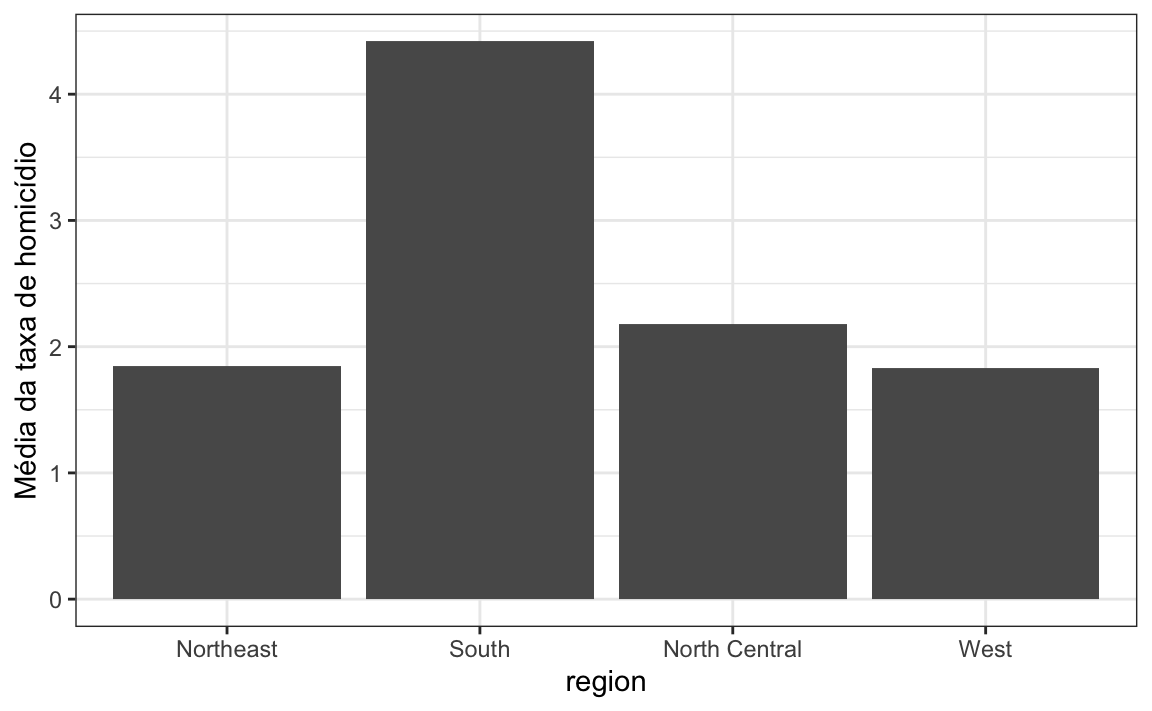 (Northeast: Nordeste, South: Sul, North Central: Centro-norte, West: Oeste)
(Northeast: Nordeste, South: Sul, North Central: Centro-norte, West: Oeste)
você decide se mudar para um estado na região oeste. Qual é o principal problema com essa interpretação?
- As categorias estão organizadas em ordem alfabética.
- O gráfico não mostra erros padrão.
- O gráfico não mostra todos os dados. Não vemos variabilidade dentro de uma região. É possível que estados mais seguros possam não estar no oeste.
- O Nordeste tem a menor média.
7. A taxa de homicídios pode ser definida da seguinte forma:
data("murders")
murders %>% mutate(rate = total/population*100000)Faça um boxplot das taxas de homicídio (murders) por região, mostrando todos os pontos e ordenando as regiões pela taxa média.
8. Os gráficos abaixo mostram três variáveis contínuas.
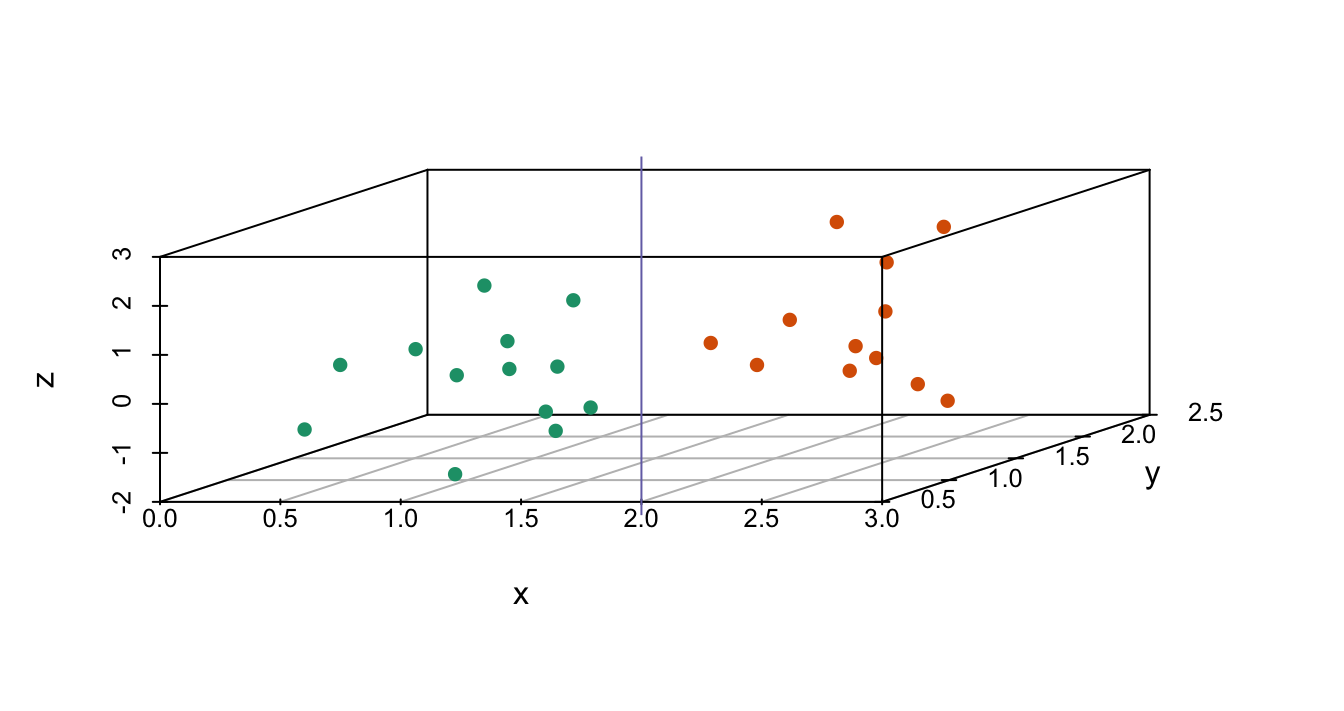
A linha \(x=2\) parece separar os pontos. Mas, na realidade, não é o caso, como vemos quando representamos graficamente os dados em um par de pontos bidimensionais.
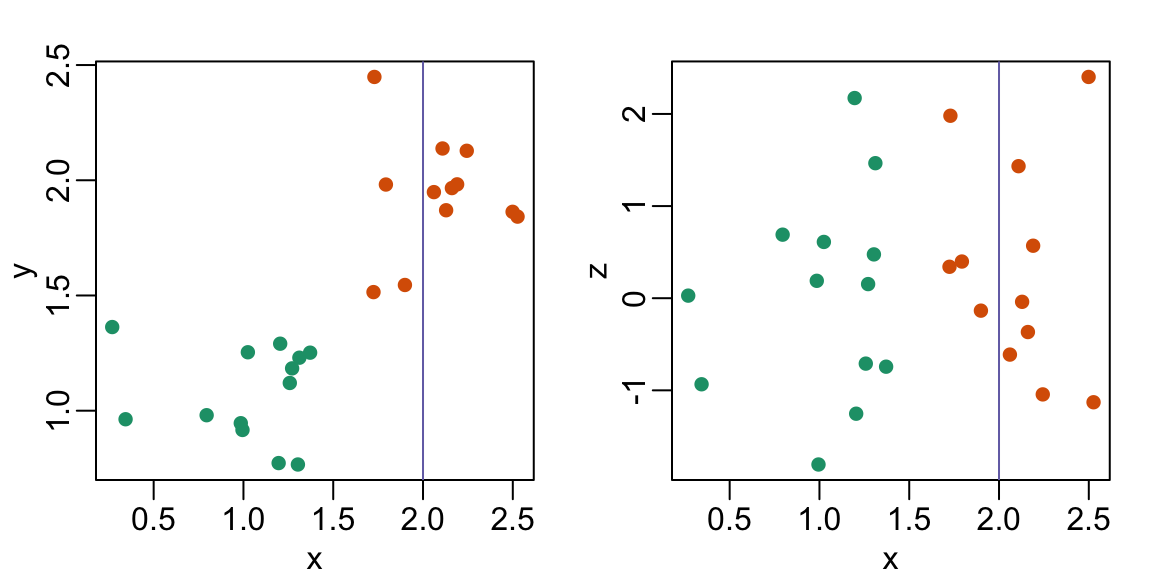
Por que acontece isso?
- Os seres humanos não são bons em ler gráficos pseudo-3D.
- Deve haver um erro no código.
- Cores nos confundem.
- Diagramas de dispersão não devem ser usados para comparar duas variáveis quando tivermos acesso a três variáveis.
9. Reproduza a imagem do gráfico que criamos anteriormente para varíola (smallpox). Para este gráfico, não inclua anos em que nenhum caso foi relatado em 10 ou mais semanas.
10. Agora, repita o gráfico de séries temporais que criamos anteriormente, mas desta vez seguindo as instruções da pergunta anterior.
11. Para o estado da Califórnia, faça gráficos de séries temporais que mostrem as taxas de todas as doenças. Inclua apenas anos nos quais os dados são fornecidos em 10 ou mais semanas. Use uma cor diferente para cada doença.
12. Agora faça o mesmo para as taxas dos EUA. Dica: calcule a taxa dos EUA usando summarize, o número total de casos dividido pela população total.
10.14 Estudo de caso: vacinas e doenças infecciosas
Vacinas ajudaram a salvar milhões de vidas. No século 19, antes da imunidade de rebanho ser alcançada por meio de programas de vacinação, as mortes por doenças infecciosas, como varíola e poliomielite, eram comuns. No entanto, hoje os programas de vacinação se tornaram um tanto controversos, apesar de todas as evidências científicas de sua importância.
A controvérsia começou com um artigo42 publicado em 1988 e liderado por Andrew Wakefield, que alegava a existência de uma ligação entre a administração da vacina contra sarampo, caxumba e rubéola e autismo e doenças intestinais. Apesar do grande conjunto de evidências científicas que contradizem esse achado, os relatos de tabloides e o sensacionalismo daqueles que acreditam em teorias da conspiração levaram parte do público a acreditar que as vacinas eram prejudiciais. Como resultado, muitos pais deixaram de vacinar seus filhos. Essa prática perigosa pode ser potencialmente desastrosa, uma vez que os Centros de Controle de Doenças dos EUA, ou CDC, estimam que a vacinação evitará mais de 21 milhões de hospitalizações e 732.000 mortes entre crianças americanas nascidas nos últimos 20 anos (consulte “Benefícios da imunização durante a era do programa Vacinas para crianças - Estados Unidos, 1994-2013, MMWR”43). Desde então, o periódico “The Lancet” retirou o artigo e Andrew Wakefield foi “removido do registro médico do Reino Unido, com uma declaração identificando falsificação deliberada na pesquisa publicada no The Lancet, e foi, portanto, impedido de praticar medicina no Reino Unido” (Fonte: Wikipedia44). Ainda assim, os equívocos permanecem, em parte por causa de ativistas autoproclamados que continuam a disseminar informações incorretas sobre vacinas.
A comunicação eficaz de dados é um forte antídoto para desinformação e os fomentadores de medo. Anteriormente, mostramos um exemplo de um artigo do Wall Street Journal45 que mostra dados relacionados ao impacto das vacinas na luta contra doenças infecciosas. Vamos reconstruir esse exemplo a seguir.
Os dados usados para esses gráficos foram coletados, organizados e distribuídos pelo Tycho Project46. Eles incluem, semanalmente, contagens reportadas para sete doenças de 1928 a 2011, para todos os 50 estados dos EUA. Incluímos os totais anuais no pacote dslabs:
library(tidyverse)
library(RColorBrewer)
library(dslabs)
data(us_contagious_diseases)
names(us_contagious_diseases)
#> [1] "disease" "state" "year"
#> [4] "weeks_reporting" "count" "population"Criamos um objeto temporário dat que armazena apenas os dados do sarampo, inclui a taxa por 100.000, ordena os estados de acordo com o valor médio da doença e remove o Alasca e o Havaí desde que esses dois se tornaram estados no final da década de 1950. Observe que existem uma coluna weeks_reporting que nos diz para quantas semanas do ano há dados relatados. Temos que ajustar esse valor ao calcular a taxa:
the_disease <- "Measles"
dat <- us_contagious_diseases %>%
filter(!state%in%c("Hawaii","Alaska") & disease == the_disease) %>%
mutate(rate = count/ population * 10000 * 52/ weeks_reporting) %>%
mutate(state = reorder(state, rate))Agora podemos facilmente plotar as taxas de doenças por ano. Aqui estão os dados de sarampo na Califórnia:
dat %>% filter(state == "California" & !is.na(rate)) %>%
ggplot(aes(year, rate)) +
geom_line() +
ylab("Casos por 10.000") +
geom_vline(xintercept=1963, col = "blue")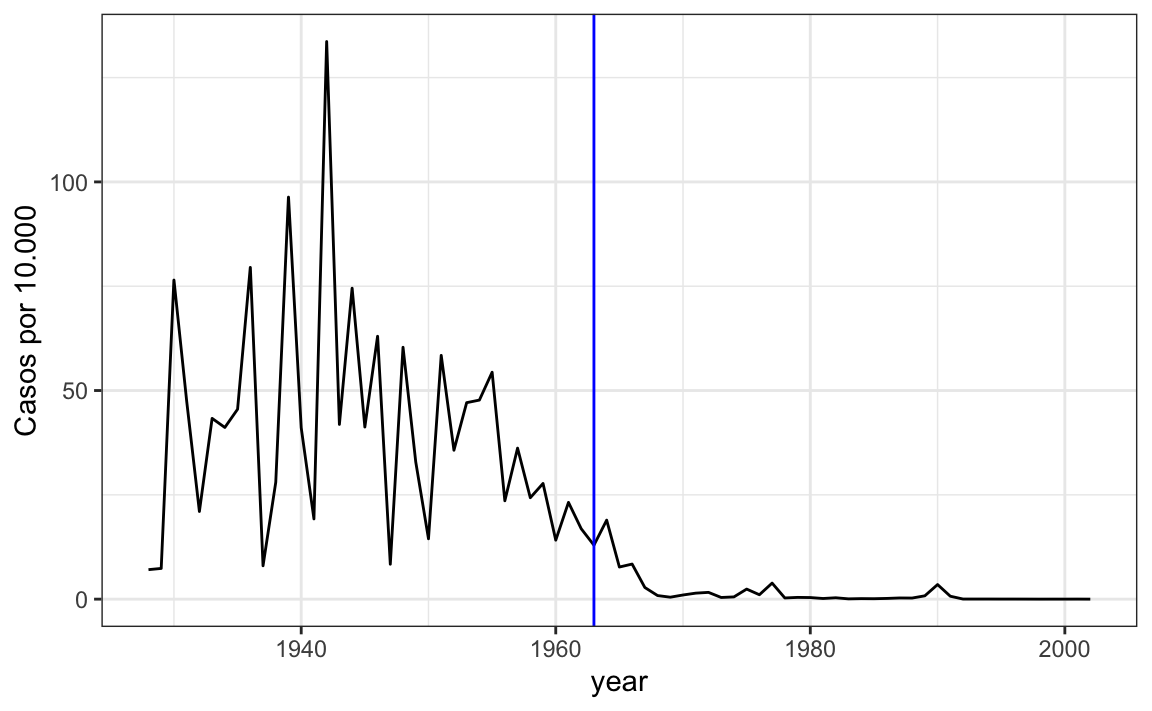
Adicionamos uma linha vertical em 1963, já que foi quando a vacina foi introduzida47.
Agora podemos exibir dados para todos os estados em um gráfico? Temos três variáveis para incluir: ano, estado e taxa. Na figura do WSJ, eles usam o eixo x para o ano, o eixo y para o estado e o tom da cor para representar as taxas. No entanto, a escala de cores que eles usam, que vai de amarelo a azul, a verde, a laranja e a vermelho, pode ser melhorada.
Em nosso exemplo, queremos usar uma paleta sequencial, pois não há um centro significativo, apenas taxas baixas e altas.
Usamos a geometria geom_tile preencher a região com cores que representam as taxas de doenças. Usamos uma transformação de raiz quadrada para impedir que contagens particularmente altas dominem o gráfico. Observe que os valores ausentes são mostrados em cinza. Além disso, observe que, assim que uma doença foi praticamente erradicada, alguns estados deixaram de relatar casos. É por essa razão que vemos tanto cinza depois de 1980.
dat %>% ggplot(aes(year, state, fill = rate)) +
geom_tile(color = "grey50") +
scale_x_continuous(expand=c(0,0)) +
scale_fill_gradientn(colors = brewer.pal(9, "Reds"), trans = "sqrt") +
geom_vline(xintercept=1963, col = "blue") +
theme_minimal() +
theme(panel.grid = element_blank(),
legend.position="bottom",
text = element_text(size = 8)) +
ggtitle(the_disease) +
ylab("") + xlab("")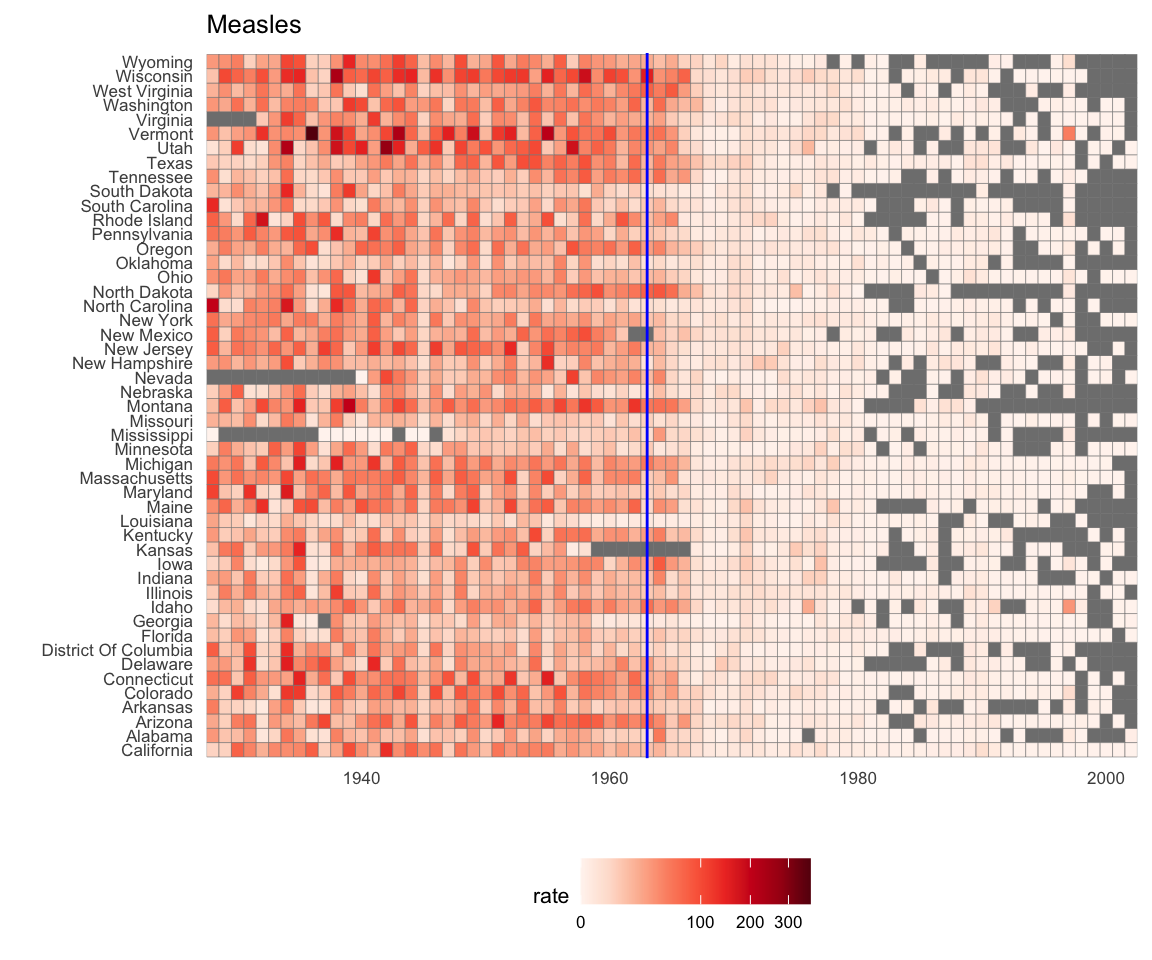
Este gráfico fornece impressionantes evidências em favor da contribuição das vacinas. Entretanto, uma limitação dessa visualização é que ela usa cores para representar quantidades, o que, como previamete explicado, dificulta conhecer exatamente quão altos são os valores. Posição e comprimento são melhores sinais. Se estamos dispostos a perder informações de estados, podemos fazer uma versão do gráfico que mostra os valores com posições. Também podemos mostrar a média para os EUA, que calculamos assim:
avg <- us_contagious_diseases %>%
filter(disease==the_disease) %>% group_by(year) %>%
summarize(us_rate = sum(count, na.rm = TRUE)/
sum(population, na.rm = TRUE) * 10000)
#> `summarise()` ungrouping output (override with `.groups` argument)Agora, para fazer o gráfico, simplesmente usamos a geometria geom_line:
dat %>%
filter(!is.na(rate)) %>%
ggplot() +
geom_line(aes(year, rate, group = state), color = "grey50",
show.legend = FALSE, alpha = 0.2, size = 1) +
geom_line(mapping = aes(year, us_rate), data = avg, size = 1) +
scale_y_continuous(trans = "sqrt", breaks = c(5, 25, 125, 300)) +
ggtitle("Casos por 10.000 por estado") +
xlab("") + ylab("") +
geom_text(data = data.frame(x = 1955, y = 50),
mapping = aes(x, y, label="Média nos EUA"),
color="black") +
geom_vline(xintercept=1963, col = "blue")
Em teoria, poderíamos usar cores para representar estados, que em uma variável categórica, mas é difícil escolher 50 cores diferentes.
10.15 Exercícios
Reproduza o mapa da matriz que fizemos anteriormente para varíola (smallpox). Para esse gráfico, não inclua os anos em que nenhum caso foi relatado por 10 ou mais semanas.
Agora, reproduza o gráfico de séries temporais que criamos anteriormente, mas desta vez seguindo as instruções da pergunta anterior para a varíola (smallpox).
Para o estado da Califórnia, faça um gráfico de série temporal mostrando as taxas de todas as doenças. Inclua apenas anos com 10 ou mais relatórios semanais. Use uma cor diferente para cada doença.
Agora faça o mesmo para as taxas dos EUA. Dica: calcule a taxa dos EUA usando
summarize: total dividido pelo tamanho da população total.
https://www.biostat.wisc.edu/~kbroman/presentations/graphs2017.pdf↩︎
http://mediamatters.org/blog/2013/04/05/fox-news-newest-dishonest-chart-immigration-enf/193507↩︎
http://flowingdata.com/2012/08/06/fox-news-continues-charting-excellence/↩︎
https://www.pakistantoday.com.pk/2018/05/18/whats-at-stake-in-venezuelan-presidential-vote↩︎
https://projecteuclid.org/download/pdf_1/euclid.ss/1177010488↩︎
http://www.thelancet.com/journals/lancet/article/PIIS0140-6736(97)11096-0/abstract↩︎
Control, Centers for Disease; Prevenção (2014). Informações de saúde do CDC para viagens internacionais em 2014 (o livro amarelo). p. 250. ISBN 9780199948505↩︎