Capítulo 9 Visualização de dados na prática
Neste capítulo, demonstraremos como códigos relativamente simples usando ggplot2 podem criar gráficos esclarecedores e esteticamente agradáveis. Como motivação, criaremos gráficos que nos ajudarão a entender melhor as tendências da saúde e da economia global. Vamos implementar o que aprendemos nos capítulos 7 e 8.16 e aprenderemos a expandir os códigos para aperfeiçoar os gráficos criados. À medida que prosseguimos em nosso estudo de caso, descreveremos os princípios gerais mais relevantes para a visualização de dados e aprenderemos conceitos como faceting, gráficos de séries temporais, transformações e gráficos de ridge.
9.1 Estudo de caso: novas perspectivas sobre pobreza
Hans Rosling29 foi co-fundador da Fundação Gapminder30, uma organização dedicada a educar o público através de dados para dissipar mitos comuns sobre o chamado mundo em desenvolvimento. A organização usa dados para mostrar como as tendências atuais nos campos da saúde e da economia contradizem as narrativas emanadas da cobertura sensacionalista da mídia sobre catástrofes, tragédias e outros eventos desafortunados. Conforme declarado no site da Fundação Gapminder:
Jornalistas e lobistas contam histórias dramáticas. Esse é o trabalho deles. Eles contam histórias sobre eventos extraordinários e pessoas incomuns. As pilhas de histórias dramáticas se acumulam na mente das pessoas gerando visões de mundo excessivamente dramáticas, estresse e fortes sentimentos negativos: “O mundo está ficando pior!” “Somos nós contra eles!” “Outras pessoas são estranhas!” “A população continua crescendo!” e “Ninguém liga!”
Hans Rosling decidiu, de maneira dramática, educar o público sobre tendências reais orientadas a dados usando visualizações eficazes. Esta seção é baseada em duas palestras que exemplificam essa perspectiva educacional: Novas Perspectivas Sobre a Pobreza31 e As Melhores Estatísticas Jamais Vistas32. Especificamente, nesta seção, usamos dados para tentar responder às duas perguntas a seguir:
- É uma caracterização justa dizer que, nos dias de hoje, o mundo está dividido em nações ocidentais ricas e nações em desenvolvimento na África, Ásia e América Latina?
- A desigualdade de renda piorou em todos os países nos últimos 40 anos?
Para responder a essas perguntas, usaremos a base de dados gapminder fornecida pelo dslabs. Esse dataset foi criado usando diversas planilhas disponibilizadas pela Fundação Gapminder. Você pode acessar essa tabela desta maneira:
library(tidyverse)
library(dslabs)
data(gapminder)
gapminder %>% as_tibble()
#> # A tibble: 10,545 x 9
#> country year infant_mortality life_expectancy fertility population
#> <fct> <int> <dbl> <dbl> <dbl> <dbl>
#> 1 Albania 1960 115. 62.9 6.19 1636054
#> 2 Algeria 1960 148. 47.5 7.65 11124892
#> 3 Angola 1960 208 36.0 7.32 5270844
#> 4 Antigu… 1960 NA 63.0 4.43 54681
#> 5 Argent… 1960 59.9 65.4 3.11 20619075
#> # … with 10,540 more rows, and 3 more variables: gdp <dbl>,
#> # continent <fct>, region <fct>9.1.1 Teste de Hans Rosling
Assim como na apresentação em vídeo Novas Perspectivas Sobre a Pobreza, começamos testando nossos conhecimentos sobre as diferenças na mortalidade infantil em diferentes países. Para cada um dos cinco pares de países abaixo, quais deles você imagina que tiveram as maiores taxas de mortalidade infantil em 2015? Quais pares você acha que são mais parecidos?
- Sri Lanka ou Turquia
- Polônia ou Coréia do Sul
- Malásia ou Rússia
- Paquistão ou Vietnã
- Tailândia ou África do Sul
Ao responder a essas perguntas sem dados, os países não europeus geralmente são escolhidos como os que apresentam as mais altas taxas de mortalidade infantil: Sri Lanka sobre a Turquia, Coreia do Sul sobre Polônia e Malásia sobre Rússia. Também é comum supor que os países considerados parte do mundo em desenvolvimento - Paquistão, Vietnã, Tailândia e África do Sul - têm taxas de mortalidade igualmente altas.
Para responder a essas perguntas com dados, podemos usar dplyr. Por exemplo, para a primeira comparação, vemos que:
gapminder %>%
filter(year == 2015 & country %in% c("Sri Lanka","Turkey")) %>%
select(country, infant_mortality)
#> country infant_mortality
#> 1 Sri Lanka 8.4
#> 2 Turkey 11.6A Turquia tem a maior taxa de mortalidade infantil.
Podemos usar esse código em todas as comparações e descobrir o seguinte:
#> New names:
#> * country -> country...1
#> * infant_mortality -> infant_mortality...2
#> * country -> country...3
#> * infant_mortality -> infant_mortality...4| country | infant mortality | country | infant mortality |
|---|---|---|---|
| Sri Lanka | 8.4 | Turkey | 11.6 |
| Poland | 4.5 | South Korea | 2.9 |
| Malaysia | 6.0 | Russia | 8.2 |
| Pakistan | 65.8 | Vietnam | 17.3 |
| Thailand | 10.5 | South Africa | 33.6 |
Vemos que os países europeus desta lista têm taxas de mortalidade infantil mais altas: a Polônia tem uma taxa mais alta do que a Coreia do Sul e a Rússia tem uma taxa mais alta que a Malásia. Também vemos que o Paquistão tem uma taxa muito mais alta do que o Vietnã e a África do Sul tem uma taxa muito mais alta do que a Tailândia. Acontece que, quando Hans Rosling deu esse teste para grupos de pessoas instruídas, a pontuação média foi inferior a 2,5 em 5, pior do que eles teriam obtido se tivessem apenas chutado as respostas. Isso implica que, mais do que ignorantes, estamos mal informados. Neste capítulo, vemos como a visualização dos dados ajuda a nos informar.
9.2 Diagramas de dispersão (scatterplots)
A razão disso decorre da noção preconcebida de que o mundo está dividido em dois grupos: o mundo ocidental (Europa Ocidental e América do Norte), caracterizado por uma longa expectativa de vida e famílias pequenas, versus o mundo em desenvolvimento (África, Ásia e América Latina), caracterizada por uma curta expectativa de vida e famílias numerosas. Mas os dados suportam essa visão dicotômica?
Os dados necessários para responder a essa pergunta também estão disponíveis em nossa tabela gapminder. Usando nossas habilidades de visualização de dados recém-aprendidas, podemos enfrentar esse desafio.
Para analisar essa visão de mundo, nosso primeiro plote é um gráfico de dispersão da expectativa de vida versus taxas de fertilidade (número médio de filhos por mulher). Começamos analisando os dados de cerca de 50 anos atrás, quando talvez essa visão tenha sido consolidada em nossas mentes.
filter(gapminder, year == 1962) %>%
ggplot(aes(fertility, life_expectancy)) +
geom_point()
A maioria dos pontos se enquadra em duas categorias diferentes:
- Expectativa de vida em torno de 70 anos e 3 ou menos filhos por família.
- Expectativa de vida menor que 65 anos e mais de 5 filhos por família.
Para confirmar que esses países são das regiões que esperamos, podemos usar cores para representar os continentes.
filter(gapminder, year == 1962) %>%
ggplot( aes(fertility, life_expectancy, color = continent)) +
geom_point()
Em 1962, a visão do “Ocidente versus mundo em desenvolvimento” era baseada em uma certa realidade. Será que ainda é assim 50 anos depois?
9.3 Separe em facetas
Podemos facilmente representar graficamente os dados de 2012 da mesma maneira que fizemos em 1962. No entanto, para comparação, é preferível representar graficamente lado a lado. No ggplot2, conseguimos isso separando as variáveis em facets: estratificamos os dados por alguma variável e fazemos o mesmo gráfico para cada estrato.
Para separar em facetas, adicionamos uma camada com a função facet_grid, que separa automaticamente os gráficos. Essa função permite separar até duas variáveis em facetas usando colunas para representar uma variável e linhas para representar a outra. A função espera que as variáveis de linha e coluna sejam separadas por um ~. Aqui vemos um exemplo de um diagrama de dispersão em que adicionamos facet_grid como a última camada:
filter(gapminder, year%in%c(1962, 2012)) %>%
ggplot(aes(fertility, life_expectancy, col = continent)) +
geom_point() +
facet_grid(continent~year)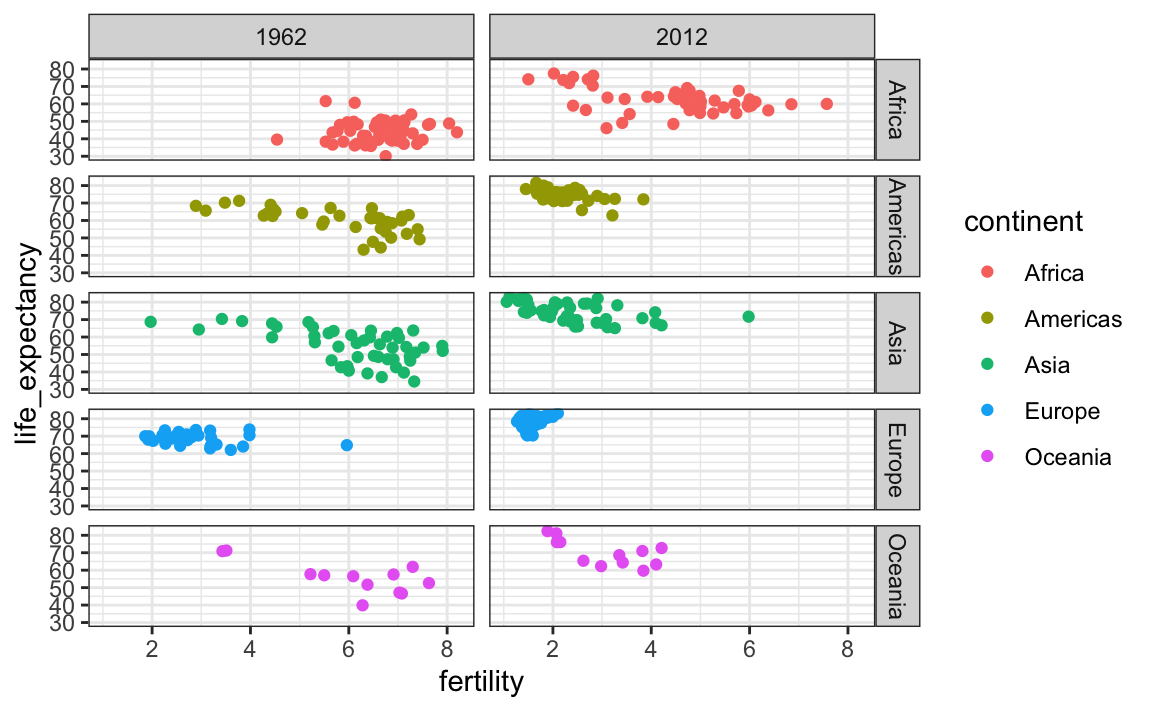
Acima, vemos um gráfico para cada combinação de continente/ano. No entanto, este exemplo apresenta mais do que queremos, que é simplesmente comparar dois anos: 1962 e 2012. Nesse caso, existe apenas uma variável. Podemos usar . para que facet_grid saiba que queremos usar todas as variáveis:
filter(gapminder, year%in%c(1962, 2012)) %>%
ggplot(aes(fertility, life_expectancy, col = continent)) +
geom_point() +
facet_grid(. ~ year)
Este gráfico mostra claramente que a maioria dos países mudou do cluster de países em desenvolvimento para o cluster de países ocidentais. Em 2012, a visão do mundo ocidental versus o mundo em desenvolvimento não faz mais sentido. Isso é particularmente evidente ao comparar a Europa com a Ásia, este último agora inclui vários países que apresentaram grandes melhorias.
9.3.1 facet_wrap
Para explorar como essa transformação ocorreu ao longo dos anos, podemos fazer o gráfico para vários anos. Por exemplo, podemos adicionar os anos 1970, 1980, 1990 e 2000. No entanto, se fizermos isso, não queremos todos os gráficos na mesma linha, que é o que faz facet_grid por padrão, pois eles parecerão muito estreitos para exibir os dados. Em vez disso, queremos usar várias linhas e colunas. A função facet_wrap nos permite fazer isso automaticamente, acomodando a série de gráficos para que cada imagem tenha dimensões visíveis:
years <- c(1962, 1980, 1990, 2000, 2012)
continents <- c("Europe", "Asia")
gapminder %>%
filter(year %in% years & continent %in% continents) %>%
ggplot( aes(fertility, life_expectancy, col = continent)) +
geom_point() +
facet_wrap(~year)
Este gráfico mostra claramente como a maioria dos países asiáticos melhorou a uma taxa muito mais rápida que os países europeus.
9.3.2 Escalas fixas para melhores comparações
A escolha padrão da faixa de eixos é importante. Quando não estiver usandofacet, esse intervalo é determinado pelos dados mostrados no gráfico. Usando facet, esse intervalo é determinado pelos dados exibidos em todos os gráficos e, portanto, permanece fixo em todas os plotes. Isso facilita muito nas comparações entre gráficos. Por exemplo, no gráfico acima, podemos ver que a expectativa de vida aumentou e a fertilidade diminuiu na maioria dos países. Vemos isso porque a nuvem de pontos está se movendo. Este não é o caso se ajustarmos as escalas:
filter(gapminder, year%in%c(1962, 2012)) %>%
ggplot(aes(fertility, life_expectancy, col = continent)) +
geom_point() +
facet_wrap(. ~ year, scales = "free")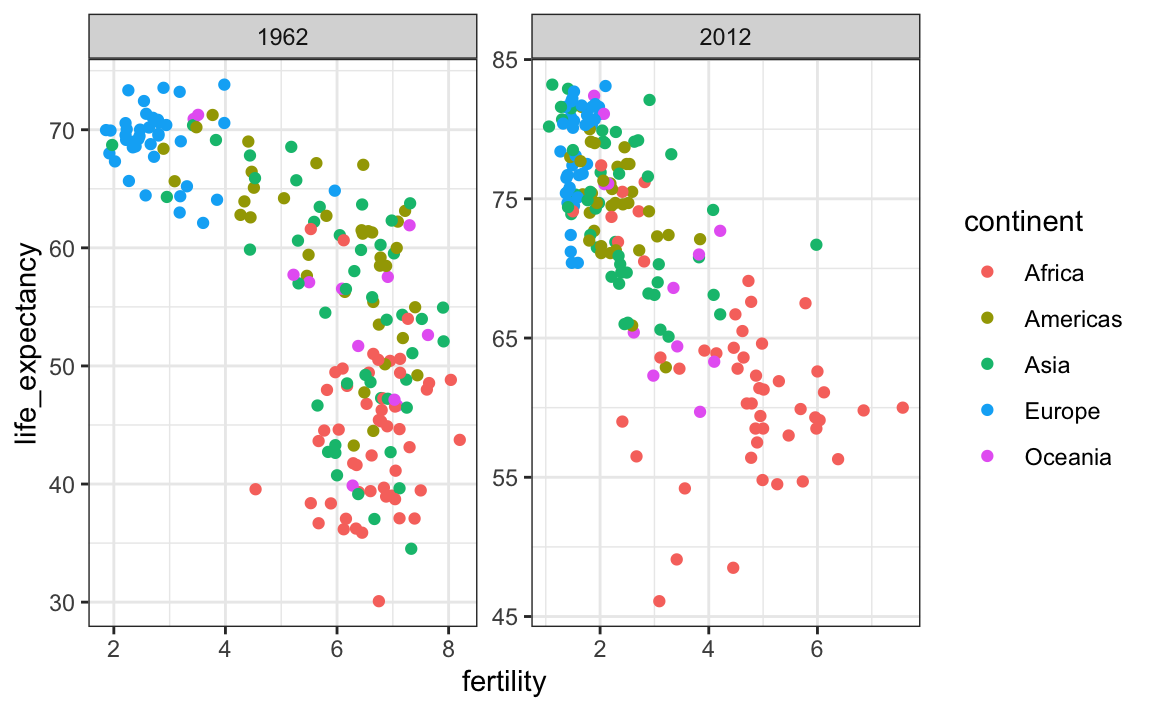
No gráfico acima, devemos prestar atenção especial ao intervalo para observar que o gráfico à direita tem uma expectativa de vida mais longa.
9.4 Gráficos de séries temporais
As visualizações acima ilustram efetivamente que os dados não são mais consistentes com a visão de mundo ocidental versus o mundo em desenvolvimento. Vendo esses gráficos, novas questões surgem. Por exemplo, quais países estão melhorando mais e quais menos? A melhoria foi constante nos últimos 50 anos ou acelerou mais em determinados períodos? Para uma análise mais detalhada que possa ajudar a responder a essas perguntas, apresentamos gráficos de séries temporais.
Os gráficos de séries temporais apresentam o tempo no eixo x e um resultado ou medida de interesse no eixo y. Por exemplo, aqui está um gráfico da tendência nas taxas de fertilidade nos Estados Unidos:
gapminder %>%
filter(country == "United States") %>%
ggplot(aes(year, fertility)) +
geom_point()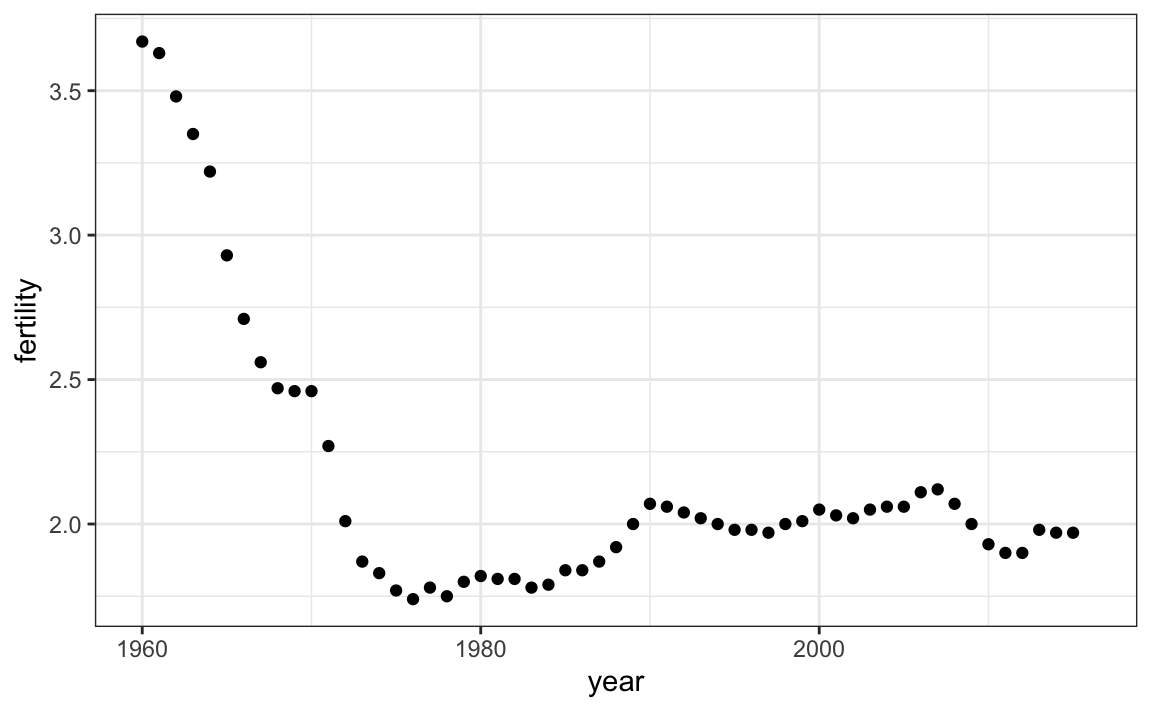
Observamos que a tendência não é linear. Em vez disso, há uma queda acentuada durante as décadas de 1960 e 1970 para menos de dois filhos em média por mulher. Em seguida, a tendência retorna a dois e se estabiliza nos anos 1990.
Quando os pontos são regularmente e densamente espaçados, como vemos acima, criamos uma curva que conecta os pontos às linhas, para transmitir a ideia de que esses dados são provenientes de uma única série, aqui representando um país. Para fazer isso, usamos a função geom_line em vez de geom_point.
gapminder %>%
filter(country == "United States") %>%
ggplot(aes(year, fertility)) +
geom_line()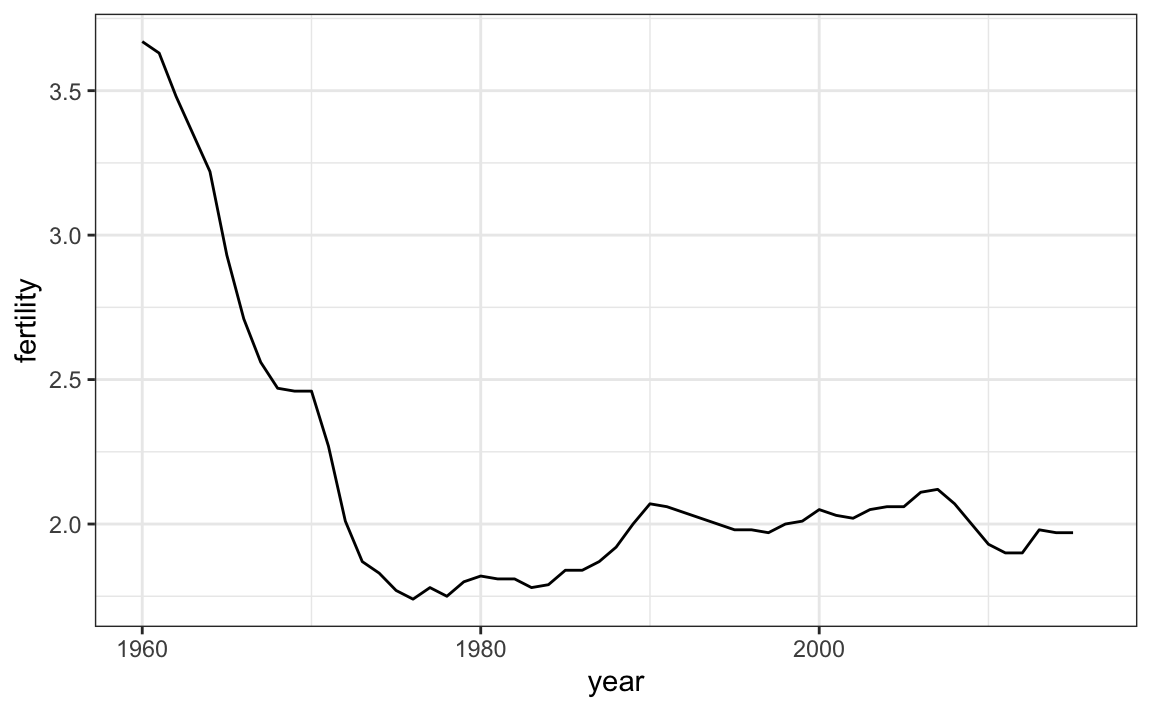
Isso é particularmente útil ao comparar dois países. Se criarmos um subconjunto dos dados para incluir dois países, um da Europa e outro da Ásia, podemos adaptar o código acima:
countries <- c("South Korea","Germany")
gapminder %>% filter(country %in% countries) %>%
ggplot(aes(year,fertility)) +
geom_line()
Claramente, esse não é o gráfico que queremos. Em vez de uma linha para cada país, os pontos dos dois países foram unidos porque não informamos a ggplot que queremos duas linhas independentes. Para que ggplot entenda que existem duas curvas que devem ser feitas separadamente, atribuímos cada ponto a um group, um para cada país:
countries <- c("South Korea","Germany")
gapminder %>% filter(country %in% countries & !is.na(fertility)) %>%
ggplot(aes(year, fertility, group = country)) +
geom_line()
Mas qual linha representa cada país? Podemos atribuir cores para fazer essa distinção.
Uma vantagem colateral do uso do argumento color para atribuir cores diferentes a diferentes países é que os dados são agrupados automaticamente:
countries <- c("South Korea","Germany")
gapminder %>% filter(country %in% countries & !is.na(fertility)) %>%
ggplot(aes(year,fertility, col = country)) +
geom_line()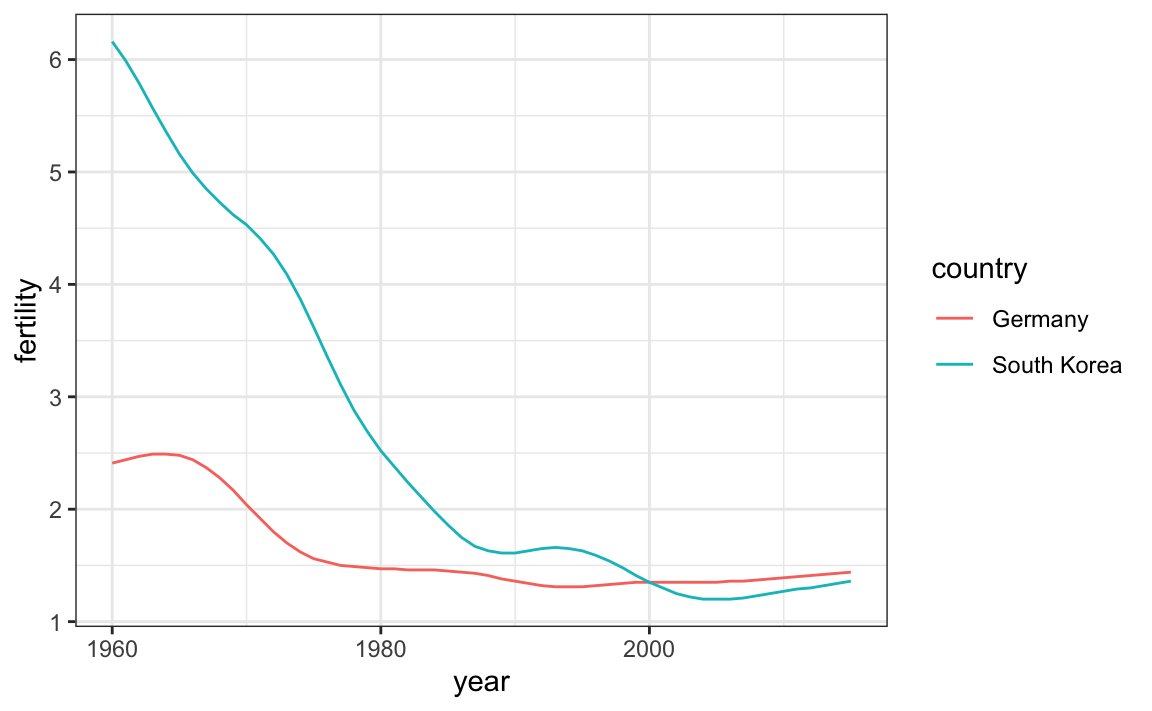
O gráfico mostra claramente como a taxa de fertilidade da Coreia do Sul caiu drasticamente durante as décadas de 1960 e 1970, e por volta de 1990 chegou a uma taxa semelhante à da Alemanha.
9.4.1 Rótulos em vez de legendas
Para gráficos de tendências, recomendamos rotular as linhas em vez de usar legendas. Assim, o espectador pode ver rapidamente qual linha representa qual país. Essa sugestão se aplica à maioria dos gráficos: rótulos geralmente são preferidos a legendas.
Demonstramos como fazer isso usando dados de expectativa de vida. Definimos uma tabela de dados com os locais dos rótulos e, em seguida, usamos uma segunda atribuição apenas para esses rótulos:
labels <- data.frame(country = countries, x = c(1975,1965), y = c(60,72))
gapminder %>%
filter(country %in% countries) %>%
ggplot(aes(year, life_expectancy, col = country)) +
geom_line() +
geom_text(data = labels, aes(x, y, label = country), size = 5) +
theme(legend.position = "none")
O gráfico mostra claramente como uma melhoria na expectativa de vida ocorreu em paralelo a quedas nas taxas de fertilidade. Em 1960, alemães viviam 15 anos a mais que sul-coreanos. Contudo, por volta de 2010, já não havia diferença. Isso exemplifica a melhoria que muitos países não ocidentais obtiveram nos últimos 40 anos.
9.5 Transformações de dados
Agora voltaremos nossa atenção para a segunda questão relacionada à ideia comum de que a distribuição da riqueza em todo o mundo piorou nas últimas décadas. Quando se pergunta ao público em geral se os países pobres se tornaram mais pobres e os países ricos se tornaram mais ricos, a maioria responde que sim. Usando estratificações, histogramas, gráficos de densidades e boxplots, podemos ver se isso é verdade. Primeiro, aprenderemos como as transformações às vezes podem ajudar a fornecer resumos e gráficos mais informativos.
A tabela de dados gapminder inclui uma coluna com o produto interno bruto (PIB) dos países. O PIB mede o valor de mercado de bens e serviços produzidos por um país em um ano. O PIB por pessoa é frequentemente usado como um resumo aproximado da riqueza de um país. Aqui, dividimos esse valor por 365 para obter uma medida mais interpretável: dólares por dia. Usando o dólar atual como unidade, uma pessoa que sobrevive com uma renda inferior a US$2 por dia é definida como vivendo em pobreza absoluta. Vamos adicionar essa variável à tabela de dados:
gapminder <- gapminder %>% mutate(dollars_per_day = gdp/population/365)Os valores do PIB são ajustados pela inflação e representam o dólar atual, portanto esses valores devem ser comparáveis ao longo dos anos. Obviamente, essas são as médias dos países e dentro de cada país há muita variabilidade. Todos os gráficos e percepções descritos abaixo se referem às médias dos países e não aos indivíduos dentro deles.
9.5.1 Transformação logarítmica
Abaixo está um histograma de renda por dia em 1970:
past_year <- 1970
gapminder %>%
filter(year == past_year & !is.na(gdp)) %>%
ggplot(aes(dollars_per_day)) +
geom_histogram(binwidth = 1, color = "black")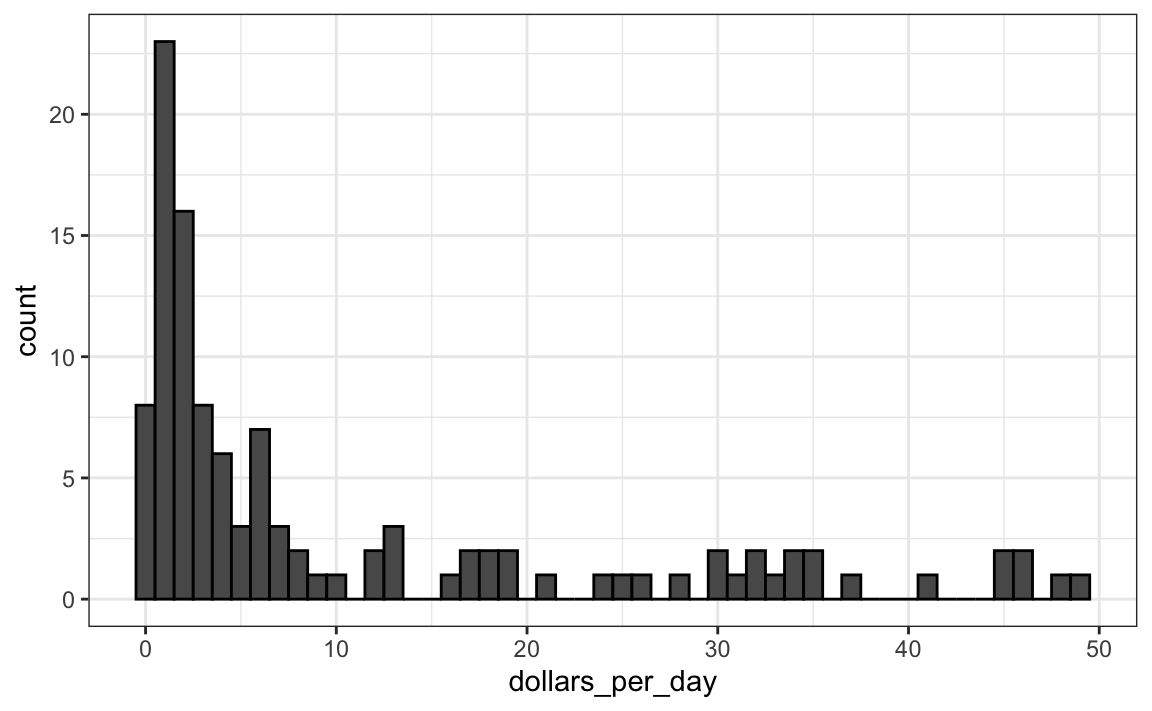
Usamos o argumento color = "black" para inserir bordas, e assim, distinguir claramente as barras.
Neste gráfico, vemos que, para a maioria dos países, as médias estão abaixo de $10 por dia. Entretanto, a maioria do eixo x está dedicado aos 35 países com médias abaixo de $10. Esse gráfico não é muito informativo em relação a esses países.
Seria mais informativo ver rapidamente quantos países têm renda média diária de cerca de $1 (extremadamente pobre), $2 (muito pobre), $4 (pobre), $8 (médio), $16 (bem de vida), $32 (rico), $64 (muito rico) por dia. Como essas mudanças são multiplicativas, as transformações logarítmicas permitem converter as alterações multiplicativas em aditivas: quando a base 2 é usada, dobrar um valor se torna um aumento de 1.
Aqui está a distribuição se aplicarmos uma transformação logarítmica de base 2:
gapminder %>%
filter(year == past_year & !is.na(gdp)) %>%
ggplot(aes(log2(dollars_per_day))) +
geom_histogram(binwidth = 1, color = "black")
É assim que observamos mais de perto os países de renda média e baixa.
9.5.2 Qual base?
No caso anterior, usamos a base 2 nas transformações logarítmicas. Outras opções comuns são a base \(\mathrm{e}\) (o logaritmo natural) e a base 10.
Em geral, não recomendamos o uso do logaritmo natural para exploração e visualização de dados. A razão disso é porque enquanto \(2^2, 2^3, 2^4, \dots\) ou \(10^2, 10^3, \dots\) são fáceis de calcular em nossas mentes, o mesmo não é verdade para \(\mathrm{e}^2, \mathrm{e}^3, \dots\). Essa escala não é intuitiva nem fácil de interpretar.
No exemplo da renda em dólares por dia, usamos a base 2 em vez da base 10 porque o intervalo resultante é mais fácil de interpretar. O intervalo dos valores plotados é 0.327, 48.885.
Na base 10, isso se torna um intervalo que inclui muito poucos números inteiros: apenas 0 e 1. Com a base dois, nosso intervalo inclui -2, -1, 0, 1, 2, 3, 4 e 5. É mais fácil de calcular \(2^x\) e \(10^x\) quando \(x\) é um número inteiro e está entre -10 e 10. Portanto, preferimos ter números inteiros menores na escala. Outra consequência de um intervalo limitado é que escolher a largura das barras (binwidth em inglês) é mais difícil. Com o log de base 2, sabemos que uma largura de barra igual a 1 será traduzida em uma barra com alcance de \(x\) a \(2x\).
Para um exemplo em que a base 10 faz mais sentido, considere os tamanhos de populações. Um logaritmo de base 10 é preferível uma vez que o intervalo para esse caso é:
filter(gapminder, year == past_year) %>%
summarize(min = min(population), max = max(population))
#> min max
#> 1 46075 8.09e+08Abaixo está o histograma dos valores transformados:
gapminder %>%
filter(year == past_year) %>%
ggplot(aes(log10(population))) +
geom_histogram(binwidth = 0.5, color = "black")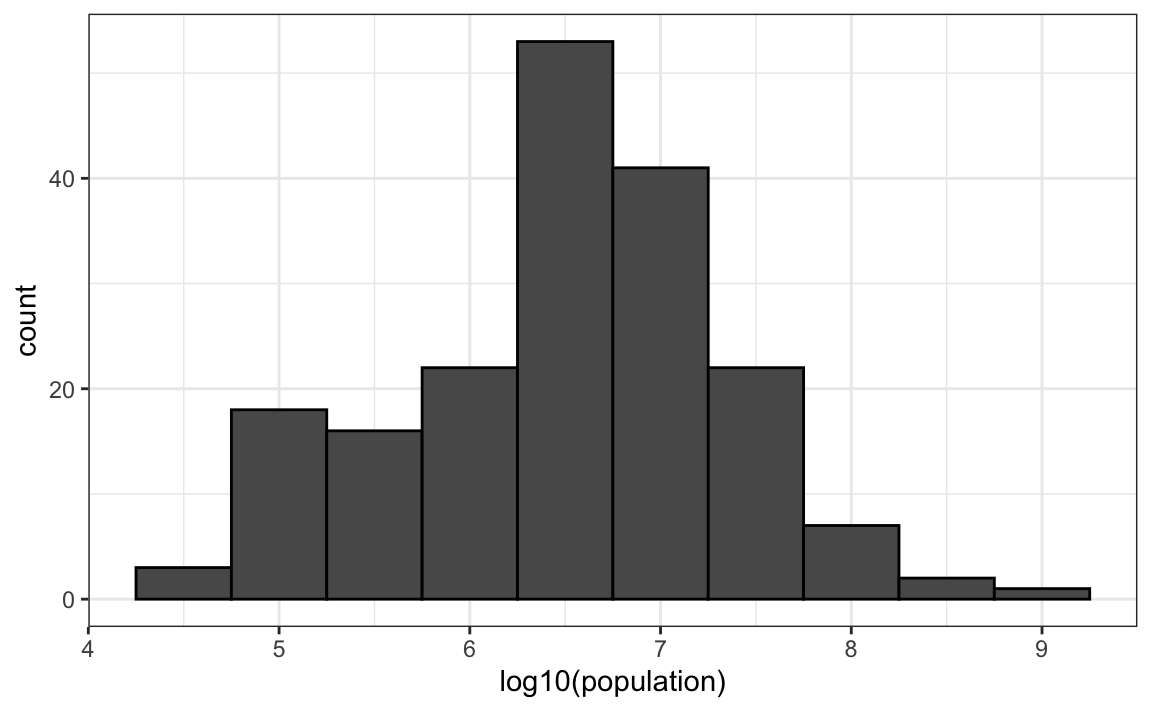
No gráfico acima, vemos rapidamente que as populações dos países variam entre dez mil e dez bilhões.
9.5.3 Transformar os valores ou a escala?
Existem duas maneiras de usar transformações logarítmicas em gráficos. Podemos pegar o logaritmo dos valores antes de representá-los graficamente ou usar escalas logarítmicas nos eixos. Ambas as abordagens são úteis e têm diferentes vantagens. Se transformarmos os dados em logaritmo, podemos interpretar mais facilmente os valores intermediários na escala. Por exemplo, se virmos:
----1----x----2--------3----
para dados transformados com o logaritmo, sabemos que o valor de \(x\) é aproximadamente 1,5. Se usarmos escalas logarítmicas:
----1----x----10------100---
então, para determinar x precisamos calcular \(10^{1.5}\), o que não é fácil de fazer mentalmente. A vantagem de usar escalas logarítmicas é que vemos os valores originais nos eixos. No entanto, a vantagem de apenas exibir essas escalas é que os valores originais são mostrados no gráfico e são mais fáceis de interpretar. Por exemplo, veríamos “32 dólares por dia” em vez de “5 log base 2 dólares por dia.”
Como aprendemos anteriormente, se quisermos dimensionar o eixo com logaritmos, podemos usar a função scale_x_continuous. Em vez de primeiro transformar os valores em logaritmo, aplicamos esta camada:
gapminder %>%
filter(year == past_year & !is.na(gdp)) %>%
ggplot(aes(dollars_per_day)) +
geom_histogram(binwidth = 1, color = "black") +
scale_x_continuous(trans = "log2")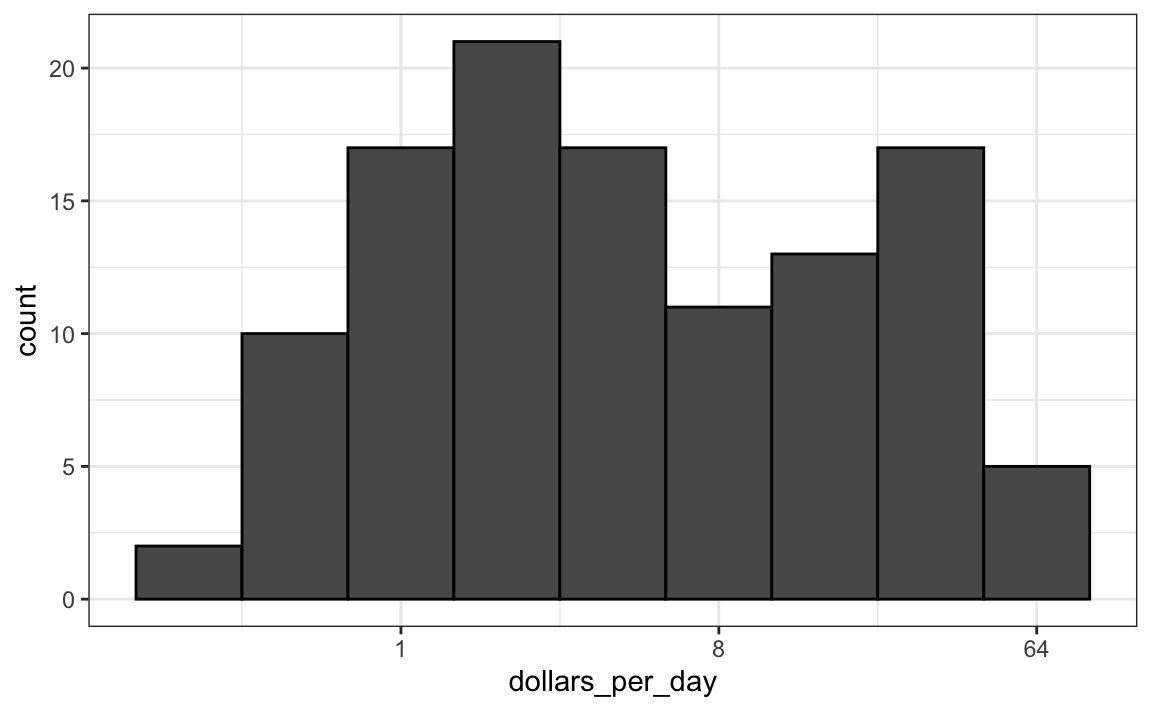
Observe que a transformação logarítmica da base 10 tem sua própria função: scale_x_log10(), mas atualmente a base 2 não, embora possamos definir facilmente a nossa própria.
Outras transformações estão disponíveis através do argumento trans. Como aprenderemos mais adiante, a transformação da raiz quadrada (sqrt) é útil ao considerar contagens. A transformação logística (logit) é útil ao plotar proporções entre 0 e 1. E a transformação reverse é útil quando queremos que os menores valores estejam à direita ou acima.
9.6 Como visualizar distribuições multimodais
No histograma acima, vemos dois picos: um aos 4 e outro aos 32. Estatisticamente, esses picos às vezes são chamados de modas. A moda de uma distribuição é o valor com a frequência mais alta. A moda de uma distribuição normal é a média. Quando uma distribuição, como aquela apresentada acima, não diminui monotonicamente na moda, chamamos os locais onde ela sobe e desce novamente de moda local e dizemos que a distribuição tem modas múltiplas.
O histograma acima sugere que a distribuição de renda dos países em 1970 possui duas modss: uma de aproximadamente 2 dólares por dia (1 na escala log 2) e outro de aproximadamente 32 dólares por dia (5 na escala log 2) . Essa bimodalidade é consistente com um mundo dicotômico composto por países com renda média inferior a $8 (3 na escala log 2) por dia e países acima disso.
9.7 Como comparar múltiplas distribuições com boxplots e gráficos ridge
De acordo com o histograma, os valores da distribuição de renda para 1970 mostram uma dicotomia. No entanto, o histograma não nos mostra se os dois grupos de países são ocidentais ou parte do mundo em desenvolvimento.
Vamos começar analisando rapidamente os dados por região. Reorganizamos as regiões pela mediana e usamos uma escala logarítmica.
gapminder %>%
filter(year == past_year & !is.na(gdp)) %>%
mutate(region = reorder(region, dollars_per_day, FUN = median)) %>%
ggplot(aes(dollars_per_day, region)) +
geom_point() +
scale_x_continuous(trans = "log2")
Já podemos ver que existe de fato uma dicotomia “ocidente versus o resto”: existem dois grupos claros, com o rico grupo constituído pela América do Norte, Europa do Norte e Ocidental, Nova Zelândia e Austrália. Definimos grupos com base nesta observação:
gapminder <- gapminder %>%
mutate(group = case_when(
region %in% c("Western Europe", "Northern Europe","Southern Europe",
"Northern America",
"Australia and New Zealand") ~ "West",
region %in% c("Eastern Asia", "South-Eastern Asia") ~ "East Asia",
region %in% c("Caribbean", "Central America",
"South America") ~ "Latin America",
continent == "Africa" &
region != "Northern Africa" ~ "Sub-Saharan",
TRUE ~ "Others"))Convertemos essa variável group em um factor para controlar a ordem dos níveis:
gapminder <- gapminder %>%
mutate(group = factor(group, levels = c("Others", "Latin America",
"East Asia", "Sub-Saharan",
"West")))Na próxima seção, mostraremos como visualizar e comparar distribuições entre grupos.
9.7.1 Boxplots (diagramas de caixa)
A análise exploratória dos dados acima revelou duas características sobre a distribuição de renda média em 1970. Usando um histograma, encontramos uma distribuição bimodal com modas relacionadas a países ricos e pobres. Agora, queremos comparar a distribuição entre esses cinco grupos para confirmar a dicotomia “oeste versus o resto.” O número de pontos em cada categoria é grande o suficiente para que um gráfico de resumo possa ser útil. Poderíamos gerar cinco histogramas ou cinco gráficos de densidade, mas pode ser mais prático ter todos os resumos visuais em um único gráfico. Portanto, vamos começar então colocando os boxplots lado a lado. Observe que adicionamos a camada theme(axis.text.x = element_text(angle = 90, hjust = 1)) para colocar os rótulos dos grupos na vertical, uma vez que, se os mostrarmos horizontalmente, eles não irão caber no eixo. Assim, podemos ganhar espaço.
p <- gapminder %>%
filter(year == past_year & !is.na(gdp)) %>%
ggplot(aes(group, dollars_per_day)) +
geom_boxplot() +
scale_y_continuous(trans = "log2") +
xlab("") +
theme(axis.text.x = element_text(angle = 90, hjust = 1))
p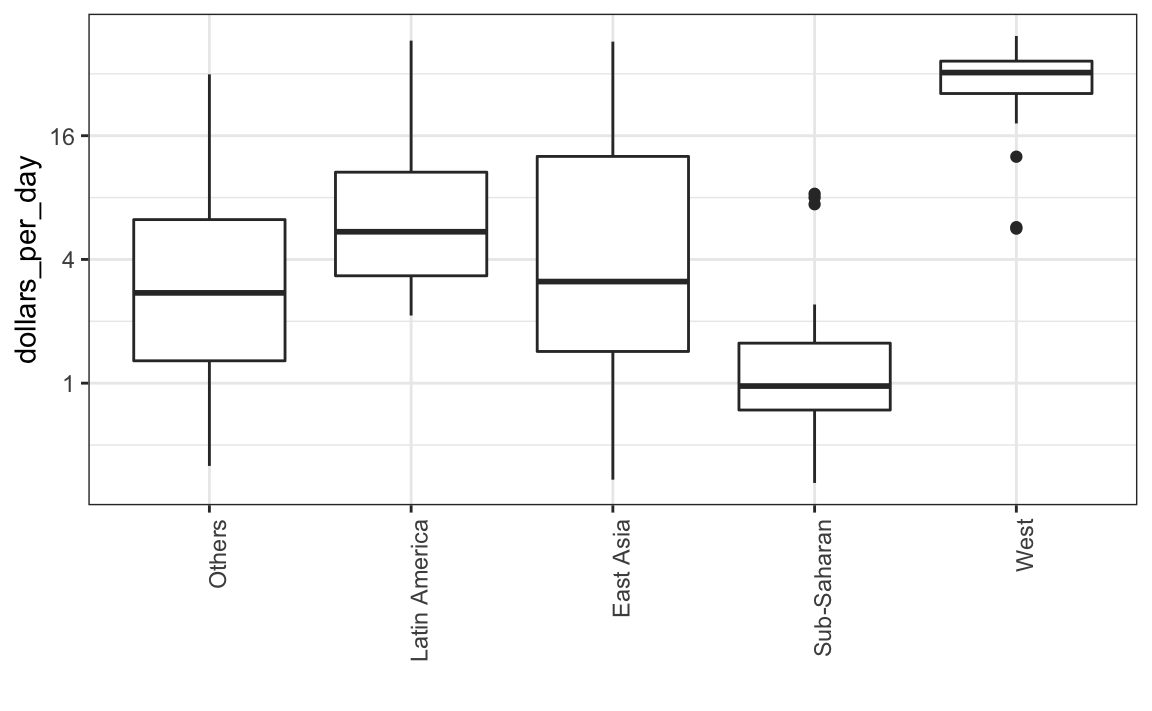
Os boxplots têm a limitação de que, resumindo os dados em cinco números, podemos perder importantes características dos dados. Uma maneira de evitar isso é exibindo os dados como pontos.
p + geom_point(alpha = 0.5)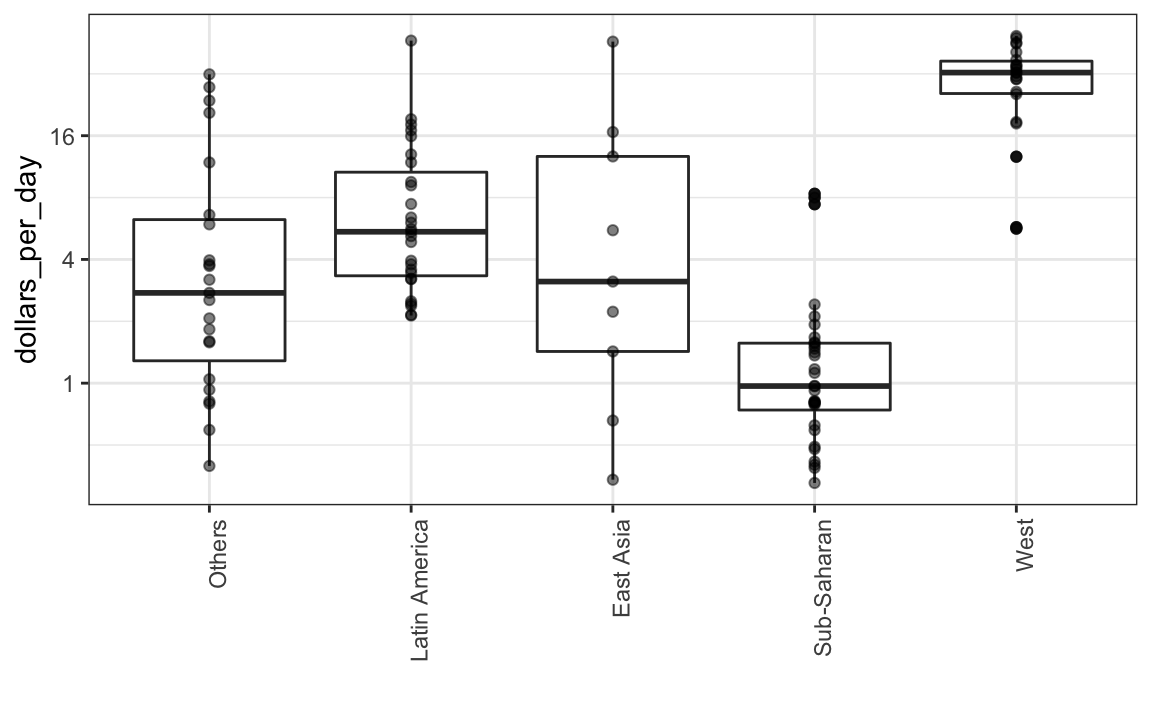
9.7.2 Gráficos ridge
Mostrar cada ponto individual nem sempre revela características importantes da distribuição. Embora esse não seja o caso aqui, quando o número de pontos representando dados é tão grande que há sobreposição, mostrar os dados pode ser contraproducente. Os boxplots ajudam nisso, fornecendo um resumo de cinco números, mas isso também tem suas limitações. Por exemplo, boxplots não revelam distribuições bimodais. Para ver isso, observe os dois gráficos abaixo que resumem o mesmo conjunto de dados:
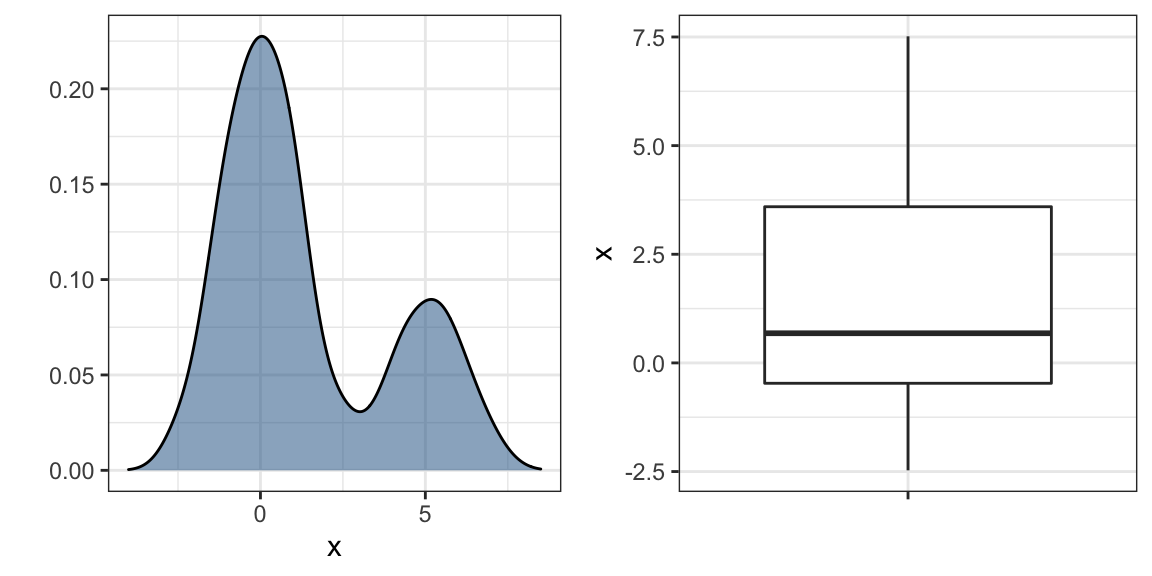
Nos casos em que estamos preocupados que o resumo do boxplot seja muito simplista, podemos exibir densidades suaves ou histogramas empilhados usando gráficos ridge. Como estamos acostumados a visualizar densidades com valores no eixo x, as empilhamos verticalmente. Além disso, como precisamos de mais espaço nessa abordagem, é conveniente permitir sobreposições. O pacote ggridges inclui uma função conveniente para fazer isso. Abaixo estão os dados da receita, mostrados acima com gráficos de caixa, mas agora exibidos com uma crista gráfica _.
library(ggridges)
p <- gapminder %>%
filter(year == past_year & !is.na(dollars_per_day)) %>%
ggplot(aes(dollars_per_day, group)) +
scale_x_continuous(trans = "log2")
p + geom_density_ridges()
Note de que precisamos inverter os valores de x e y que foram usados para o boxplot. Um parâmetro útil para geom_density_ridges é scale, que permite determinar quanto os gráficos irão se sobrepor. Por exemplo, scale = 1 significa que não há sobreposição. Valores maiores que 1 resultam em maior sobreposição.
Se o número de pontos de dados for pequeno o suficiente, podemos adicioná-los ao gráfico ridge usando o seguinte código:
p + geom_density_ridges(jittered_points = TRUE)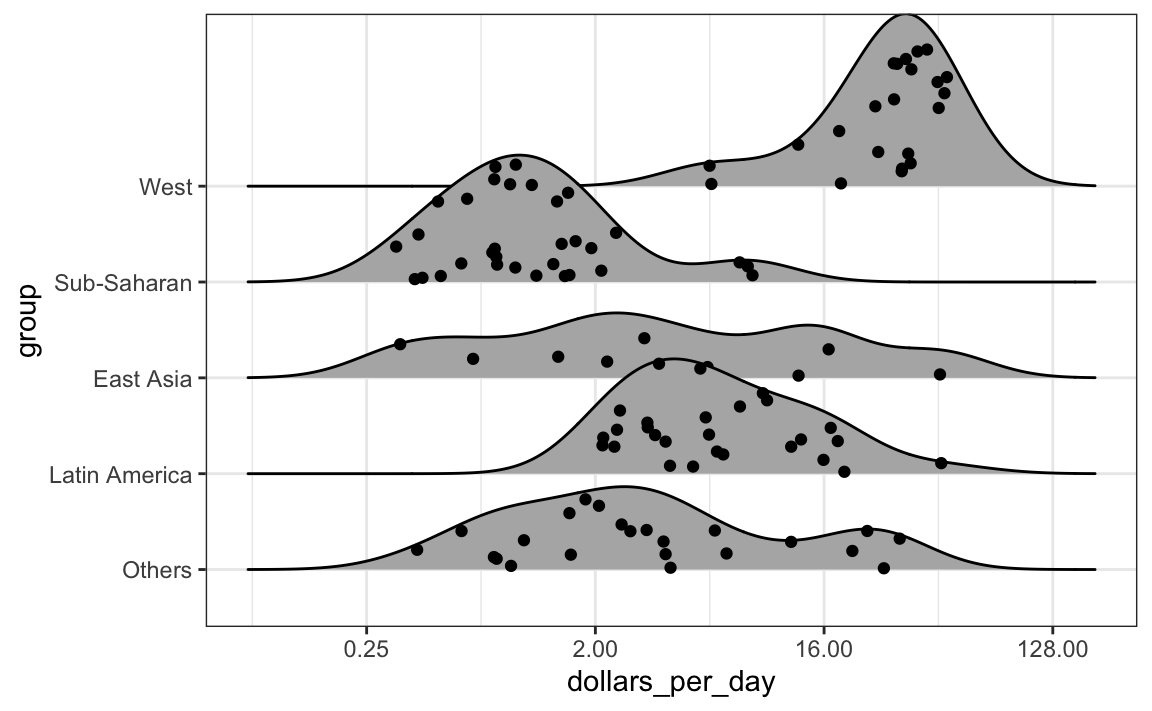
Por padrão, a altura dos pontos é instável (jittered) e não deve ser interpretada de forma alguma. Para exibir pontos de dados, mas sem usar jitter, podemos usar o código a seguir para adicionar o que é conhecido como uma representação rug dos dados.
p + geom_density_ridges(jittered_points = TRUE,
position = position_points_jitter(height = 0),
point_shape = '|', point_size = 3,
point_alpha = 1, alpha = 0.7)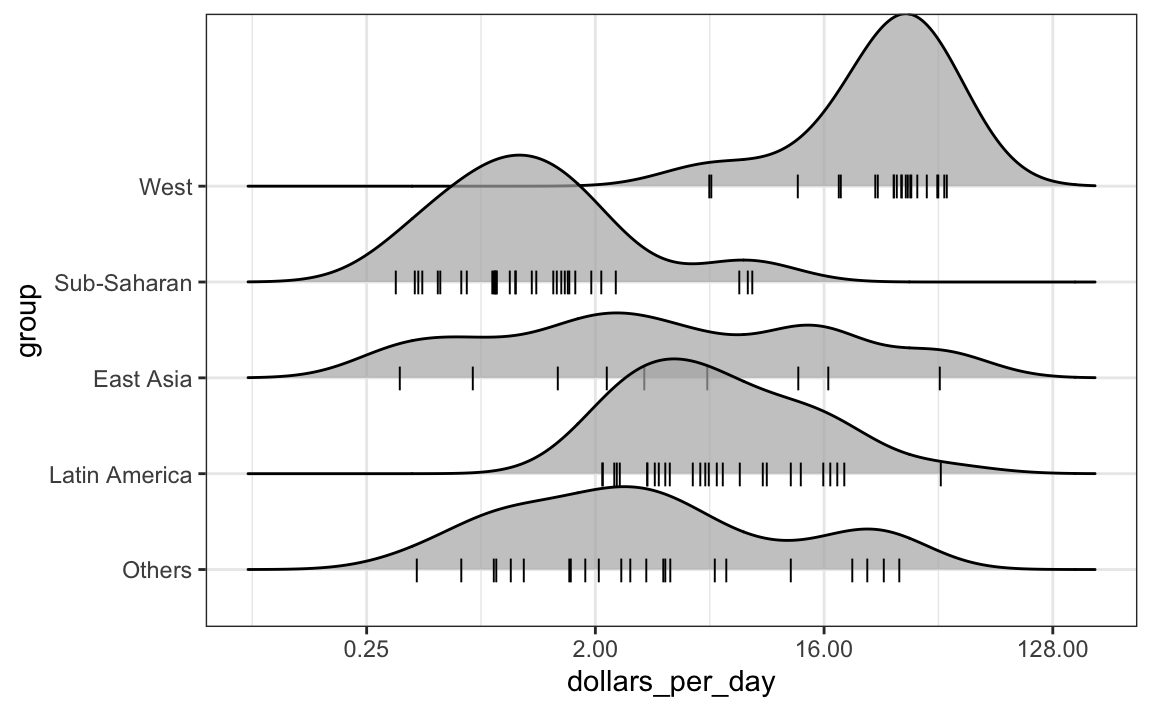
9.7.3 Exemplo: distribuições de renda 1970 versus 2010
A exploração dos dados mostra claramente que em 1970 havia uma dicotomia “ocidente versus o resto.” Mas essa dicotomia persiste? Vamos usar facet_grid para ver como as distribuições mudaram. Para começar, focamos em dois grupos: o ocidente e o resto. Vamos fazer quatro histogramas:
past_year <- 1970
present_year <- 2010
years <- c(past_year, present_year)
gapminder %>%
filter(year %in% years & !is.na(gdp)) %>%
mutate(west = ifelse(group == "West", "West", "Developing")) %>%
ggplot(aes(dollars_per_day)) +
geom_histogram(binwidth = 1, color = "black") +
scale_x_continuous(trans = "log2") +
facet_grid(year ~ west)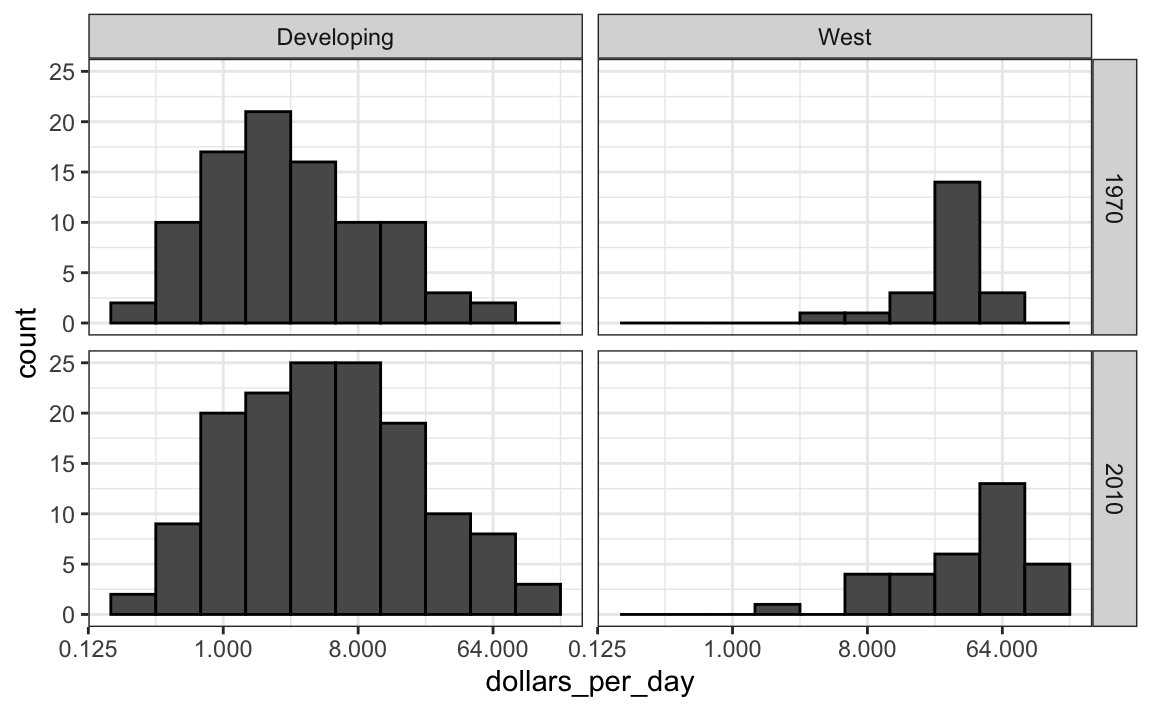
Antes de interpretar as conclusões deste gráfico, notamos que há mais países representados nos histogramas de 2010 do que em 1970: a contagem total é maior. Uma razão para isso é que vários países foram fundados após 1970. Por exemplo, a União Soviética foi dividida em diferentes países durante os anos 1990. Uma outra razão é que mais dados estão disponíveis para mais países em 2010.
Refizemos os gráficos usando apenas países com dados disponíveis para ambos os anos. Na seção data wrangling deste livro, aprenderemos a usar as ferramentas tidyverse que nos permitirão escrever códigos eficiente para isso. Entretanto, aqui iremos usar um simples código usando a função intersect:
country_list_1 <- gapminder %>%
filter(year == past_year & !is.na(dollars_per_day)) %>%
pull(country)
country_list_2 <- gapminder %>%
filter(year == present_year & !is.na(dollars_per_day)) %>%
pull(country)
country_list <- intersect(country_list_1, country_list_2)Estes 108 representam 86% da população mundial, portanto esse subconjunto deve ser representativo.
Vamos refazer o gráfico apenas para esse subconjunto, simplesmente adicionando country %in% country_list para a função filter:

Agora vemos que os países ricos ficaram um pouco mais ricos, mas em termos de porcentagem, os países pobres parecem ter melhorado mais. Em particular, vemos que a proporção de países em desenvolvimento que ganha mais de 16 dólares por dia aumentou substancialmente.
Para ver quais regiões específicas melhoraram mais, podemos refazer os boxplots construídos anteriormente, mas agora adicionamos o ano de 2010, e então, usamos facet para comparar os dois anos.
gapminder %>%
filter(year %in% years & country %in% country_list) %>%
ggplot(aes(group, dollars_per_day)) +
geom_boxplot() +
theme(axis.text.x = element_text(angle = 90, hjust = 1)) +
scale_y_continuous(trans = "log2") +
xlab("") +
facet_grid(. ~ year)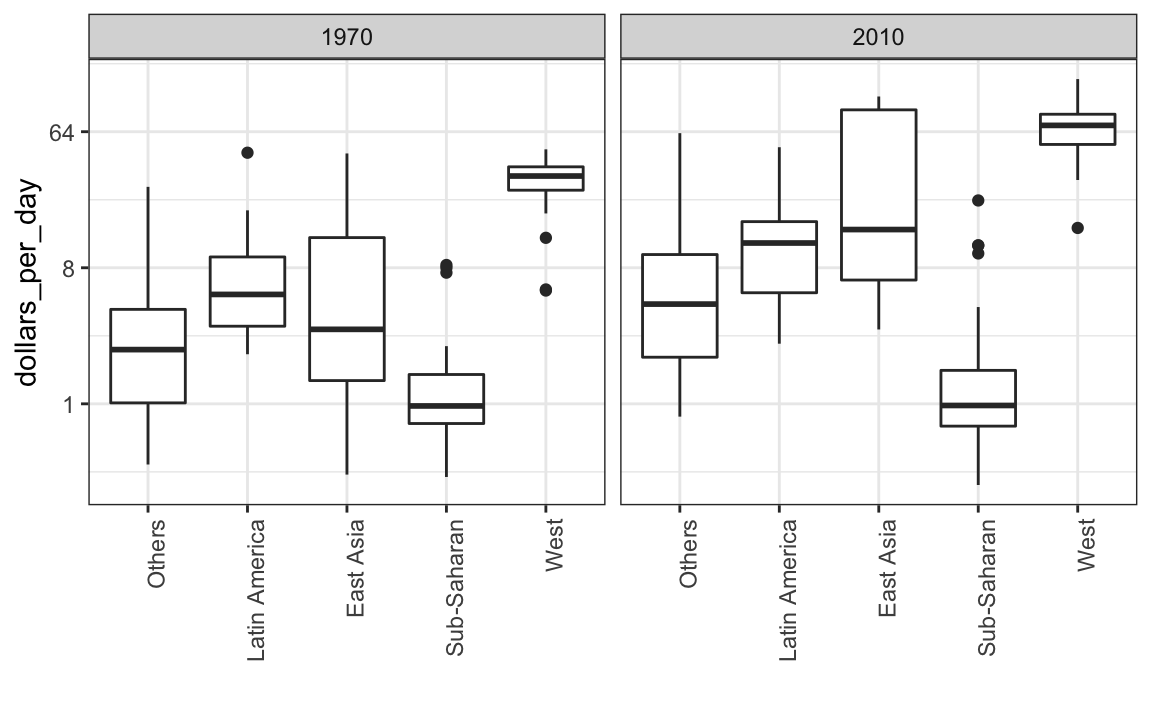
Agora faremos uma pausa para introduzir outro recurso importante do ggplot2. Como queremos comparar cada região antes e depois, seria conveniente ter o boxplot de 1970 próximo ao de 2010 para cada região. Em geral, as comparações são mais fáceis quando os dados são plotados um ao lado do outro.
Portanto, em vez de separarmos em facetas, manteremos os dados de cada ano juntos e iremos colori-los dependendo do ano. Observe que os grupos são separados automaticamente por ano e cada par de boxplot é desenhado lado a lado. Como o ano é um número, nós o converteremos em um factor, uma vez que ggplot2 atribui automaticamente uma cor a cada categoria de um factor. Lembre-se que temos que converter as colunas year de numeric para factor.
gapminder %>%
filter(year %in% years & country %in% country_list) %>%
mutate(year = factor(year)) %>%
ggplot(aes(group, dollars_per_day, fill = year)) +
geom_boxplot() +
theme(axis.text.x = element_text(angle = 90, hjust = 1)) +
scale_y_continuous(trans = "log2") +
xlab("")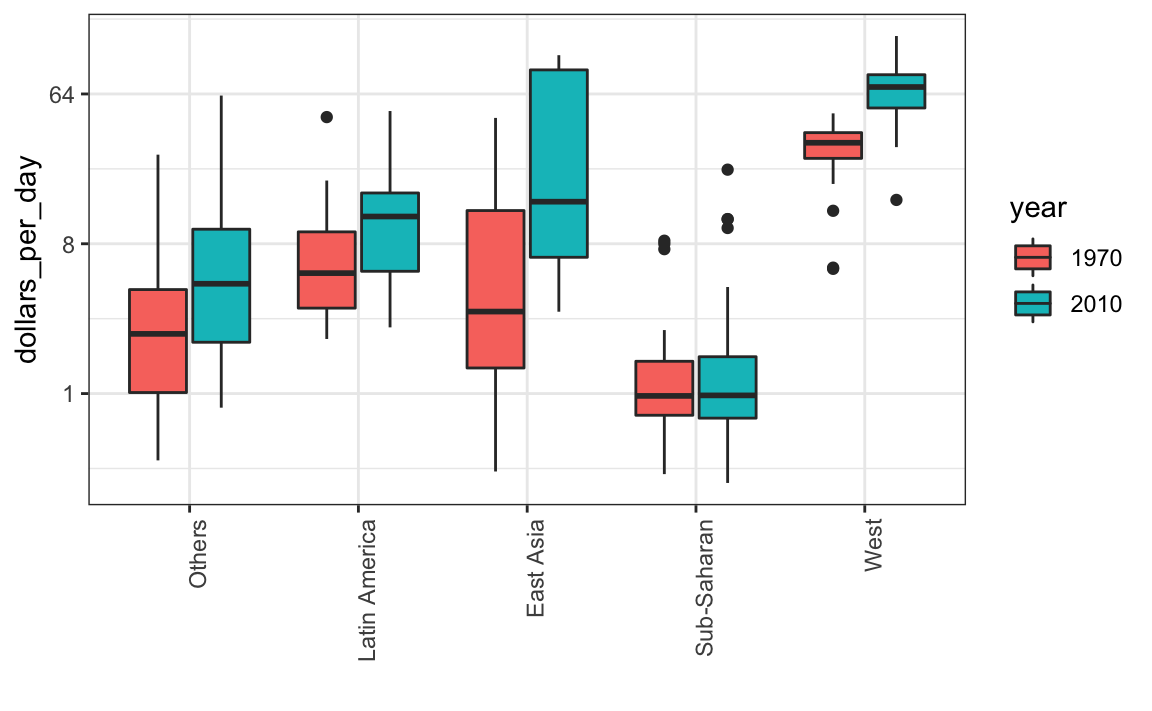
Finalmente, destacamos que, se estivermos mais interessados em comparar os valores antes e depois, pode fazer mais sentido traçar aumentos percentuais. Ainda não estamos prontos para aprender como codificar isso, mas é assim que o gráfico seria:
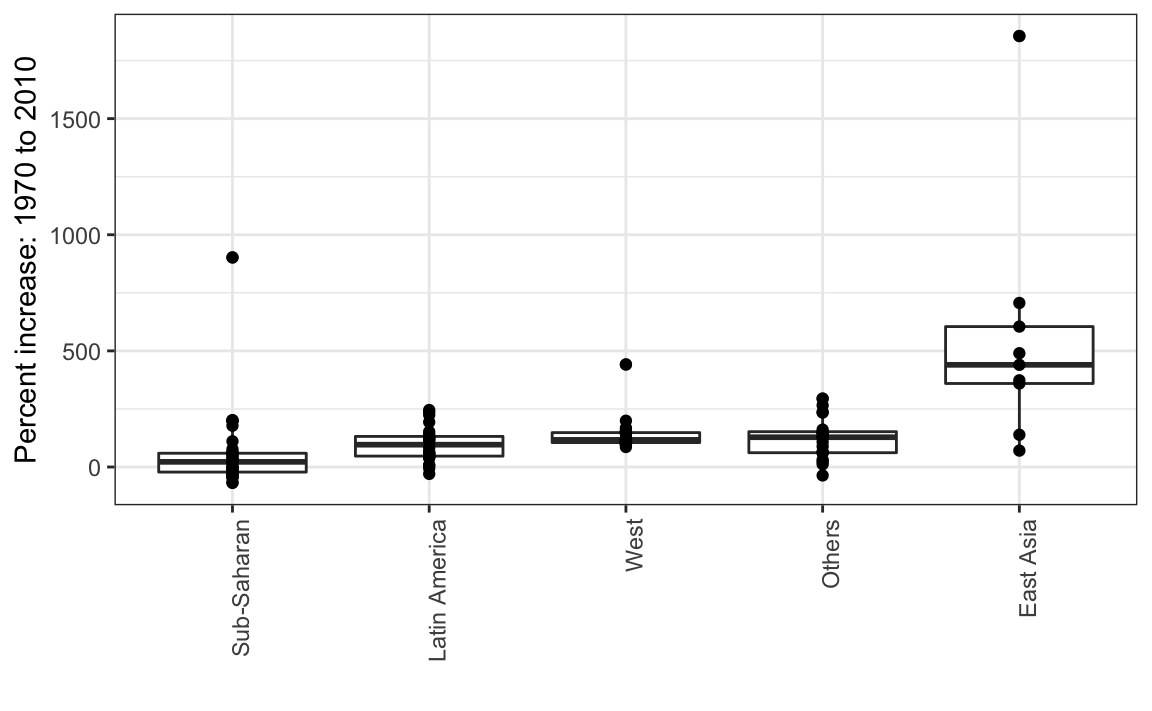
A exploração de dados anterior sugere que a diferença de renda entre países ricos e pobres diminuiu consideravelmente nos últimos 40 anos. Usamos uma série de histogramas e boxplots para ver isso. Sugerimos uma maneira sucinta de transmitir essa mensagem com apenas um gráfico.
Vamos começar observando que os gráficos de densidade para a distribuição de renda em 1970 e 2010 transmitem a mensagem de que a diferença está diminuindo:
gapminder %>%
filter(year %in% years & country %in% country_list) %>%
ggplot(aes(dollars_per_day)) +
geom_density(fill = "grey") +
scale_x_continuous(trans = "log2") +
facet_grid(. ~ year)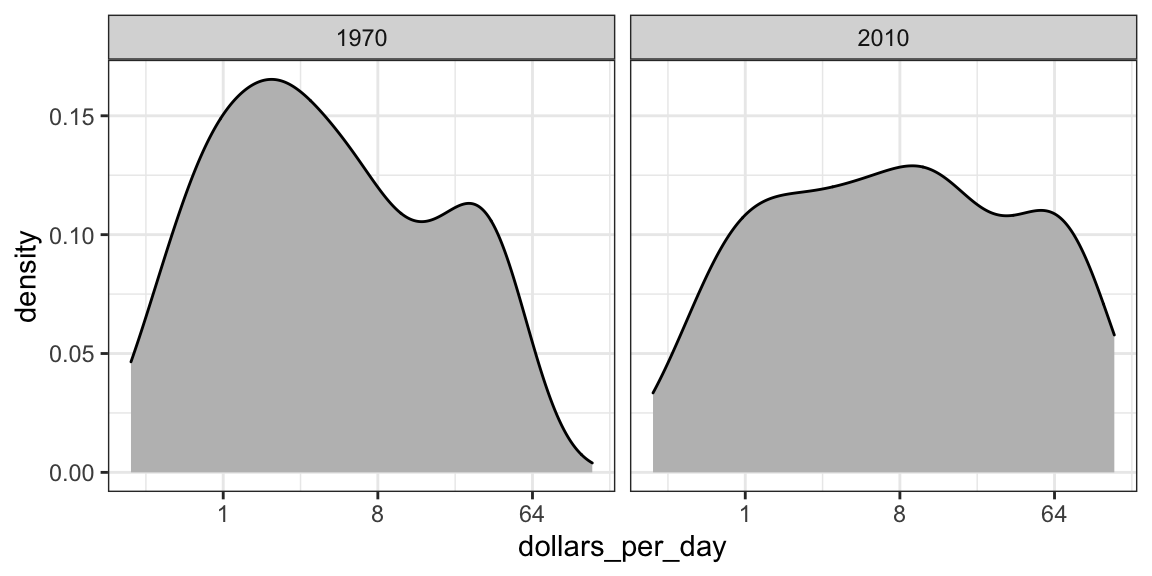
No gráfico de 1970 vemos duas tendências claras: países pobres e ricos. No 2010 alguns dos países pobres parecem ter mudado para a direita, diminuindo a diferença.
A próxima mensagem que devemos transmitir é que a razão para essa mudança na distribuição é que vários países pobres ficaram mais ricos do que alguns países ricos ficaram mais pobres. Para fazer isso, podemos atribuir uma cor aos grupos que identificamos durante a exploração de dados.
No entanto, precisamos primeiro aprender a suavizar essas densidades de maneira a preservar informações sobre o número de países em cada grupo. Para entender por que precisamos disso, lembre-se da discrepância no tamanho de cada grupo:
#> `summarise()` ungrouping output (override with `.groups` argument)| Developing | West |
|---|---|
| 87 | 21 |
Porém, quando sobrepomos duas densidades, o comportamento padrão é que a área representada por cada distribuição some 1, independentemente do tamanho de cada grupo:
gapminder %>%
filter(year %in% years & country %in% country_list) %>%
mutate(group = ifelse(group == "West", "West", "Developing")) %>%
ggplot(aes(dollars_per_day, fill = group)) +
scale_x_continuous(trans = "log2") +
geom_density(alpha = 0.2) +
facet_grid(year ~ .)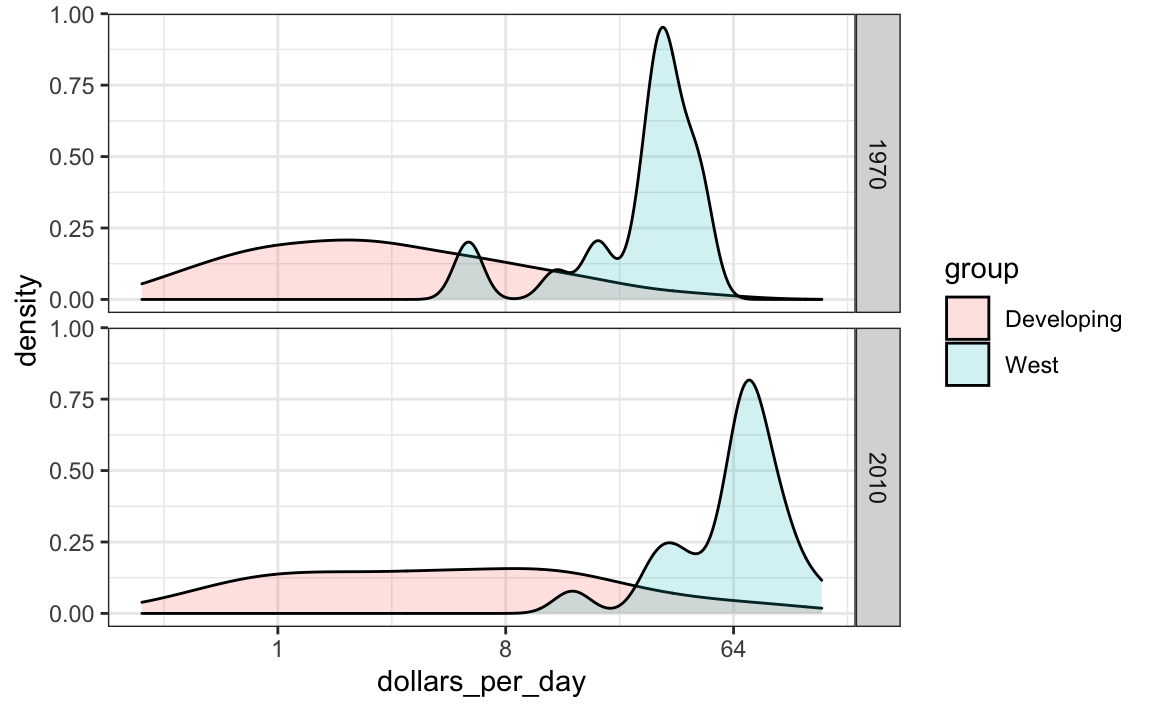
O gráfico acima mostra que há o mesmo número de países em cada grupo. Para mudar isso, precisaremos aprender como acessar as variáveis calculadas com a função geom_density.
9.7.4 Como acessar variáveis calculadas
Para tornar as áreas dessas densidades proporcionais ao tamanho do grupo, simplesmente multiplicamos os valores do eixo y pelo tamanho do grupo. No arquivo de ajuda de geom_density, vemos que as funções calculam uma variável chamada count que faz exatamente isso. Queremos que essa variável, e não a densidade, esteja no eixo y.
Em ggplot2, obtemos acesso a essas variáveis cercando o nome com dois pontos. Portanto, usaremos o seguinte mapeamento:
aes(x = dollars_per_day, y = ..count..)Agora podemos criar o gráfico desejado simplesmente alterando o mapeamento do código anterior. Também estenderemos os limites do eixo x.
p <- gapminder %>%
filter(year %in% years & country %in% country_list) %>%
mutate(group = ifelse(group == "West", "West", "Developing")) %>%
ggplot(aes(dollars_per_day, y = ..count.., fill = group)) +
scale_x_continuous(trans = "log2", limit = c(0.125, 300))
p + geom_density(alpha = 0.2) +
facet_grid(year ~ .)
Se queremos que as densidades sejam mais suaves, usamos o argumento bw para que o mesmo parâmetro de suavização seja usado para cada densidade. Selecionamos 0,75 após testar vários valores.
p + geom_density(alpha = 0.2, bw = 0.75) + facet_grid(year ~ .)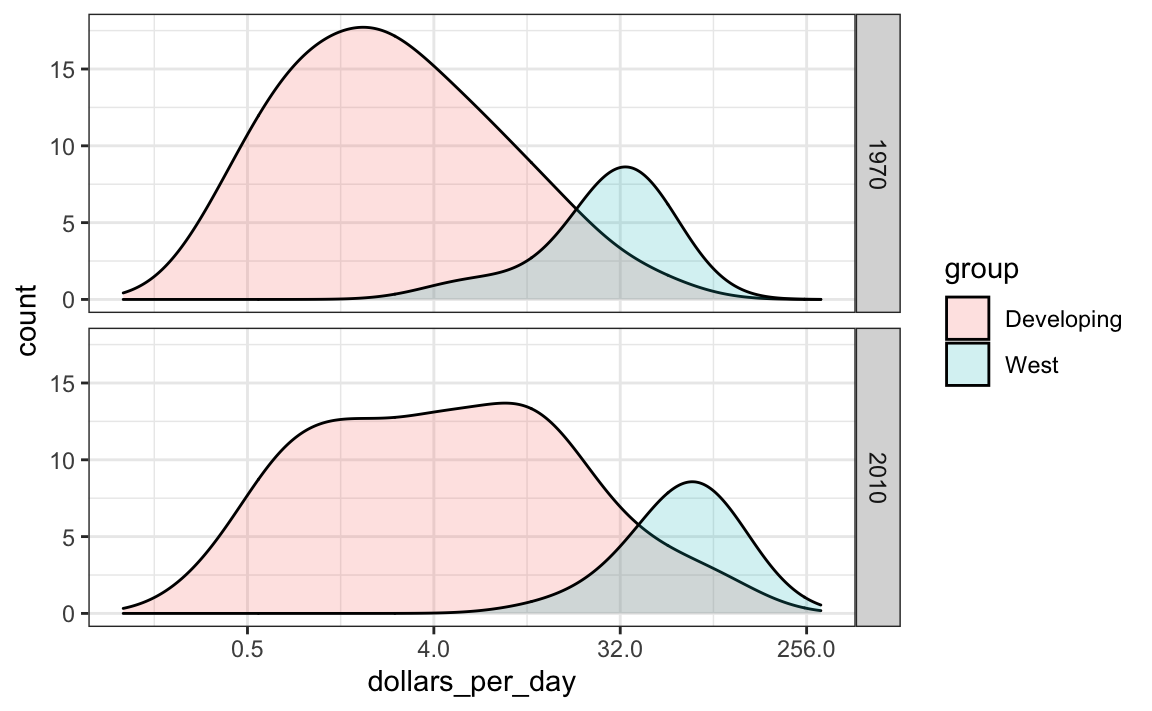
Esse gráfico agora mostra o que está acontecendo muito claramente. A distribuição do mundo em desenvolvimento está mudando. Uma terceira modalidade aparece, apresentando os países que mais diminuíram a diferença.
Para visualizar se algum dos grupos definidos acima é a principal causa dessas alterações, podemos criar rapidamente um gráfico ridge:
gapminder %>%
filter(year %in% years & !is.na(dollars_per_day)) %>%
ggplot(aes(dollars_per_day, group)) +
scale_x_continuous(trans = "log2") +
geom_density_ridges(adjust = 1.5) +
facet_grid(. ~ year)
Outra maneira de conseguir isso é empilhando as densidades umas sobre as outras:
gapminder %>%
filter(year %in% years & country %in% country_list) %>%
group_by(year) %>%
mutate(weight = population/sum(population)*2) %>%
ungroup() %>%
ggplot(aes(dollars_per_day, fill = group)) +
scale_x_continuous(trans = "log2", limit = c(0.125, 300)) +
geom_density(alpha = 0.2, bw = 0.75, position = "stack") +
facet_grid(year ~ .)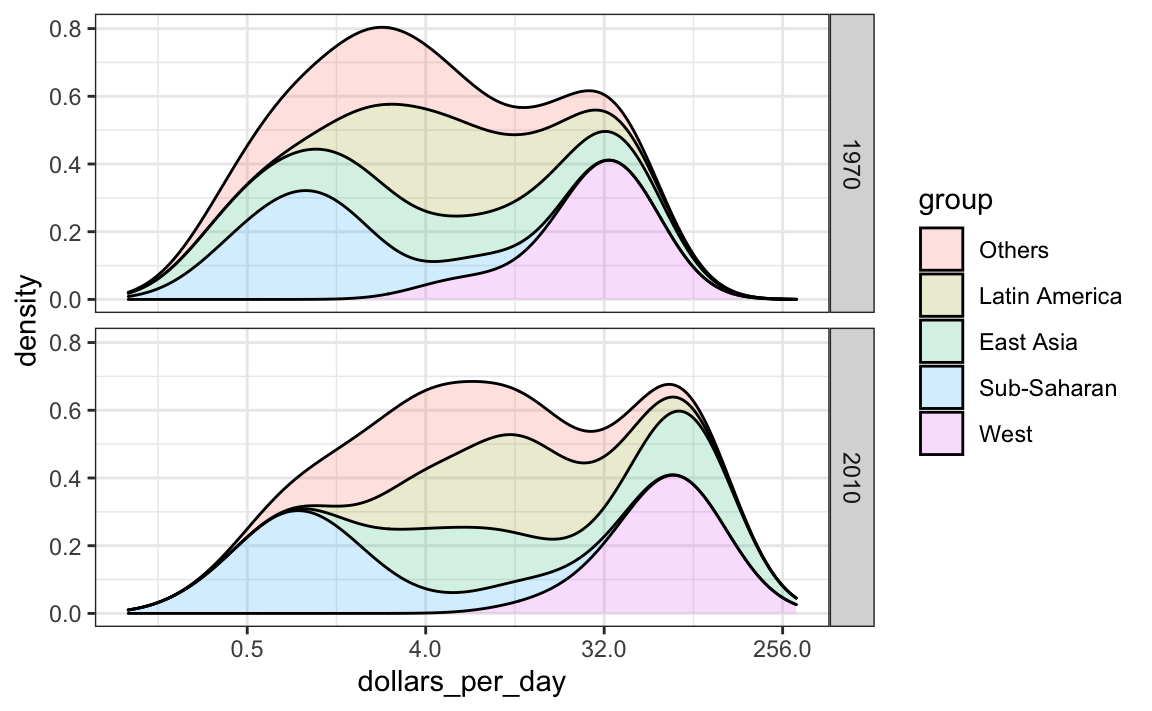
Aqui podemos ver claramente como as distribuições para o Leste da Ásia, América Latina e outros se deslocam visivelmente para a direita. Enquanto a África Subsaariana permanece estagnada.
Observe que ordenamos os níveis do grupo para que a densidade do Ocidente seja plotada primeiro, seguida pela África Subsaariana. Ter ambas as extremidades representadas graficamente primeiro nos permite ver melhor a bimodalidade restante.
9.7.5 Densidades ponderadas
Como ponto final, notamos que essas distribuições têm o mesmo peso para cada país. Portanto, se a maioria da população está melhorando, mas se tratando em um país muito grande, como a China, talvez não avaliemos isso. De fato, podemos ponderar as densidades suaves usando o argumento de mapeamento weight. O gráfico então ficaria assim:

Essa figura em particular mostra muito claramente como a diferença na distribuição de renda está diminuindo e que a maioria dos países ainda em situação de pobreza está na África Subsaariana.
9.8 A falácia ecológica e a importância de mostrar os dados
Ao longo desta seção, comparamos regiões do mundo. Vimos que, em média, algumas regiões têm melhor desempenho que outras. Nesta seção, vamos nos concentrar na descrição da importância da variabilidade dentro dos grupos, examinando a relação entre as taxas de mortalidade infantil de um país e a renda média.
Vamos definir mais algumas regiões e comparar as médias entre elas:
#> `summarise()` ungrouping output (override with `.groups` argument)
A relação entre essas duas variáveis é quase perfeitamente linear e o gráfico mostra uma diferença dramática. Enquanto menos de 0,5% dos bebês morrem no Ocidente, na África Subsaariana a taxa é superior a 6%!
Observe que o gráfico usa uma nova transformação, a transformação logística.
9.8.1 Transformação logística
Transformação logística ou logit para uma proporção ou taxa \(p\) é definida como:
\[f(p) = \log \left( \frac{p}{1-p} \right)\]
Quando \(p\) é uma proporção ou probabilidade, a quantidade que transformamos com o logaritmo, \(p/(1-p)\), é chamado de chance. Neste caso \(p\) é a proporção de bebês que sobreviveram. As chances nos dizem quantos bebês a mais devem sobreviver do que morrer. A transformação logarítmica torna isso simétrico. Se as taxas forem iguais, o log das chances será 0. Aumentos multiplicativos são convertidos em aumentos positivos ou negativos, respectivamente.
Essa escala é útil quando queremos destacar diferenças próximas de 0 ou 1. Para taxas de sobrevivência, isso é importante porque uma taxa de sobrevivência de 90% é inaceitável, enquanto uma sobrevivência de 99% é relativamente boa. Preferiríamos muito uma taxa de sobrevivência próxima de 99,9%. Queremos que nossa escala destaque essas diferenças e o logit o faz. Lembre-se de que 99,9/0,1 é aproximadamente 10 vezes maior que 99/1, que é aproximadamente 10 vezes maior que 90/10. Usando o logaritmo, esses incrementos multiplicativos são convertidos em aumentos constantes.
9.8.2 Mostre os dados
Agora, de volta ao nosso gráfico. Com base no gráfico acima, podemos concluir que um país de baixa renda está destinado a ter uma baixa taxa de sobrevivência? Além disso, podemos concluir que as taxas de sobrevivência na África Subsaariana são mais baixas do que no Sul da Ásia, que por sua vez, são mais baixas do que nas ilhas do Pacífico e assim por diante?
Ir direto para essa conclusão com base em um gráfico que mostra as médias é conhecido como falácia ecológica. A relação quase perfeita entre taxas de sobrevivência e renda é observada apenas para médias regionais. Depois de mostrar todos os dados, vemos uma história um pouco mais complicada:
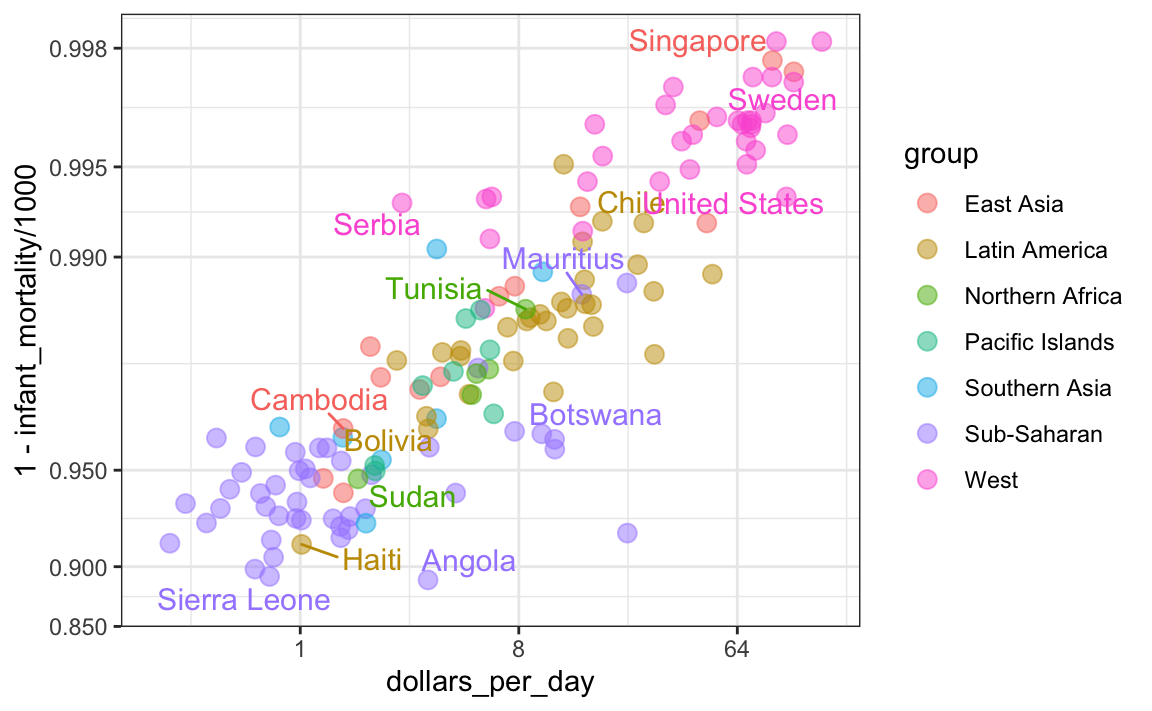
Especificamente, vemos que há muita variabilidade. Vemos que os países nas mesmas regiões podem ser bem diferentes e que os países com a mesma renda podem ter taxas de sobrevivência diferentes. Por exemplo, enquanto a África Subsaariana teve os piores resultados econômicos e de saúde em média, há uma grande variabilidade dentro desse grupo. Maurício e Botsuana são melhores que Angola e Serra Leoa, com Maurício comparável aos países ocidentais.