library(tidyverse)
library(dslabs)
falling_object <- rfalling_object()17 Measurement Error Models
Another major application of linear models occurs in measurement error models. In these situations, non-random covariates, such as time, are frequently encountered, with randomness often arising from measurement errors rather than from sampling or inherent natural variability.
17.1 Example: modeling a falling object
To understand these models, imagine you are Galileo in the 16th century trying to describe the velocity of a falling object. An assistant climbs the Tower of Pisa and drops a ball, while several other assistants record the position at different times. Let’s simulate some data using the equations we currently know and adding some measurement error. The dslabs function rfalling_object generates these simulations:
The assistants hand the data to Galileo, and this is what he sees:
falling_object |>
ggplot(aes(time, observed_distance)) +
geom_point() +
ylab("Distance in meters") +
xlab("Time in seconds")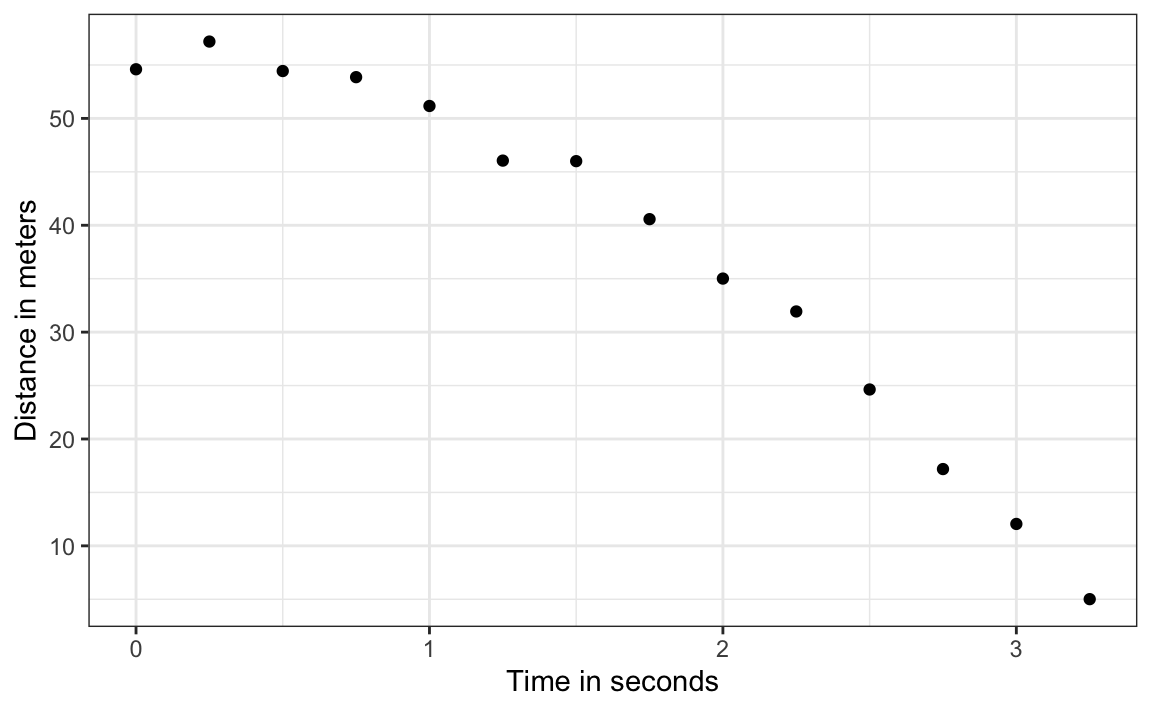
Galileo does not know the exact equation, but by looking at the plot above, he deduces that the position should follow a parabola, which we can write like this:
\[ f(x) = \beta_0 + \beta_1 x + \beta_2 x^2 \]
The data does not fall exactly on a parabola. Galileo knows this is due to measurement error. His helpers make mistakes when measuring the distance. To account for this, he models the data with:
\[ Y_i = \beta_0 + \beta_1 x_i + \beta_2 x_i^2 + \varepsilon_i, i=1,\dots,n \]
with \(Y_i\) representing distance in meters, \(x_i\) representing time in seconds, and \(\varepsilon_i\) accounting for measurement error. The measurement error is assumed to be random, independent from each other, and having the same distribution for each \(i\). We also assume that there is no bias, which means the expected value \(\mathrm{E}[\varepsilon] = 0\).
Note that this is a linear model because it is a linear combination of known quantities (\(x\) and \(x^2\) are known) and unknown parameters (the \(\beta\)s are unknown parameters to Galileo). Unlike our previous examples, here \(x\) is a fixed quantity; we are not conditioning.
Small discrepancies between a model’s predictions and observations are often attributed to measurement error, as in our example. In many cases, this is a useful and practical approximation. However, such differences can also reveal limitations in the model itself. Galileo’s experiments on gravity showed slight deviations from his predicted uniform acceleration, largely due to air resistance rather than flawed measurements. Similarly, Newton’s laws of gravity accurately described planetary motion, but small discrepancies in Mercury’s orbit, once considered observational errors, ultimately led to Einstein’s general theory of relativity. While assuming measurement error is often reasonable, it is crucial to recognize when discrepancies signal model limitations. The diagnostic plots discussed in Section 16.14 can help assess such limitations.
17.2 Estimating parameters with least squares
To pose a new physical theory and start making predictions about other falling objects, Galileo needs actual numbers, rather than unknown parameters. Using LSE seems like a reasonable approach. How do we find the LSE?
LSE calculations do not require the errors to be approximately normal. The lm function will find the \(\beta\)s that will minimize the residual sum of squares:
Let’s check if the estimated parabola fits the data. The broom function augment allows us to do this easily:
broom::augment(fit) |>
ggplot() +
geom_point(aes(time, observed_distance)) +
geom_line(aes(time, .fitted), col = "blue")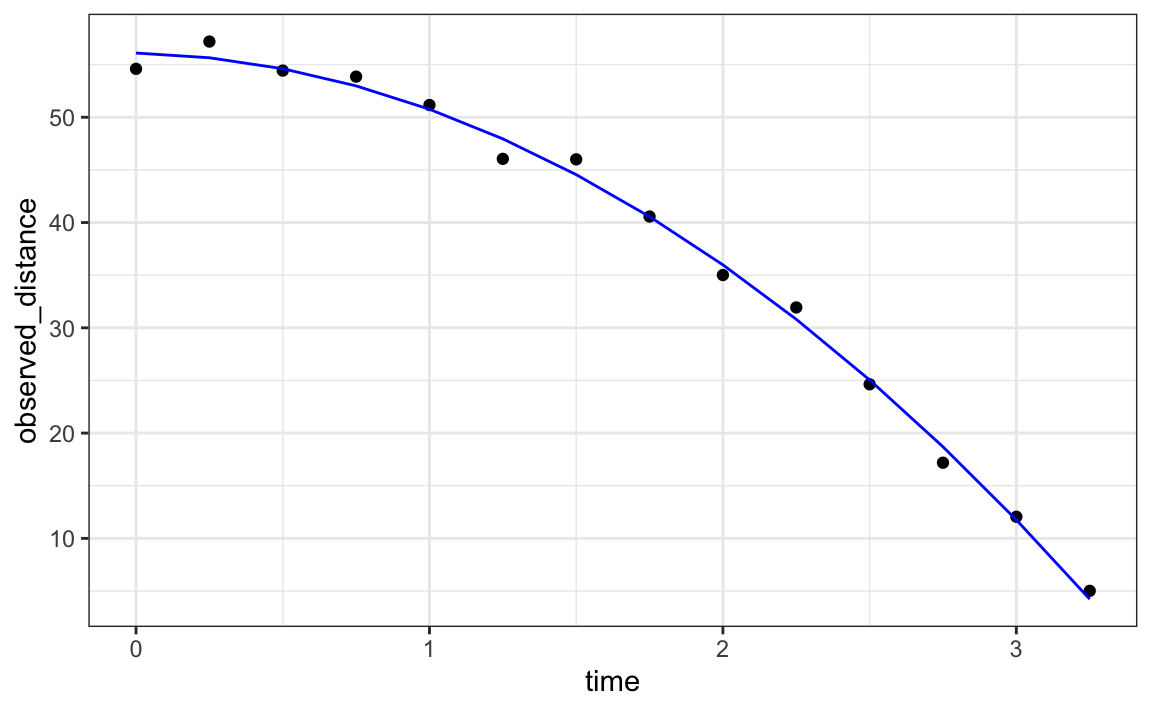
Thanks to my high school physics teacher, I know that the equation for the trajectory of a falling object is:
\[ d(t) = h_0 + v_0 t - 0.5 \times 9.8 \, t^2 \]
with \(h_0\) and \(v_0\) the starting height and velocity, respectively. The data we simulated above followed this equation, adding measurement error to simulate n observations for dropping the ball \((v_0=0)\) from the tower of Pisa \((h_0=55.86)\).
These are consistent with the parameter estimates:
confint(fit)
#> 2.5 % 97.5 %
#> (Intercept) 54.04 57.96
#> time -2.30 3.30
#> time_sq -5.88 -4.22The Tower of Pisa height is within the confidence interval for \(\beta_0\), the initial velocity 0 is in the confidence interval for \(\beta_1\) (note the p-value is larger than 0.05), and the acceleration constant is in a confidence interval for \(-2 \times \beta_2\).
17.3 Exercises
1. The co2 dataset is a time series object of 468 CO2 observations, monthly from 1959 to 1997. Plot CO2 levels for the first 12 months and notice it seems to follow a sine wave with a frequency of 1 cycle per year. This means that a measurement error model that might work is
\[ y_i = \mu + A \sin(2\pi \,t_i / 12 + \phi) + \varepsilon_i \] with \(t_i\) the month number for observation \(i\). Is this a linear model for the parameters \(mu\), \(A\) and \(\phi\)?
2. Using trigonometry, we can show that we can rewrite this model as:
\[ y_i = \beta_0 + \beta_1 \sin(2\pi t_i/12) + \beta_2 \cos(2\pi t_i/12) + \varepsilon_i \]
Is this a linear model?
3. Find least square estimates for the \(\beta\)s using lm. Show a plot of \(y_i\) versus \(t_i\) with a curve on the same plot showing \(\hat{Y}_i\) versus \(t_i\).
4. Now fit a measurement error model to the entire co2 dataset that includes a trend term that is a parabola as well as the sine wave model.
5. Run diagnostic plots for the fitted model and describe the results.