6 Continuous Probability
In Section 1.3, we discussed why it is not practical to assign a frequency to every possible continuous outcome, such as an exact height, since there are infinitely many possible values. The same idea extends to random outcomes that take values on a continuous scale: each individual value has probability zero. Instead, we describe their behavior through probability density functions, which let us compute probabilities for intervals of values rather than single points.
In this chapter, we introduce the mathematical framework for continuous probability distributions and present several useful approximations that frequently appear in data analysis.
6.1 Cumulative distribution functions
We return to our example using the heights of adult male students:
We previously defined the empirical cumulative distribution function (eCDF) as
F <- function(a) mean(x <= a)which, for any value a, gives the proportion of values in the list x that are less than or equal to a.
To connect the eCDF to probability, imagine randomly selecting one of the male students. What is the chance that he is taller than 70.5 inches? Because each student is equally likely to be chosen, this probability is simply the proportion of students taller than 70.5 inches. Using the eCDF, we can compute it as:
1 - F(70.5)
#> [1] 0.363The cumulative distribution function (CDF) is the theoretical counterpart of the eCDF. Rather than relying on observed data to compute proportions, it directly assigns probabilities to ranges of values for a random outcome \(X\). Specifically, the CDF gives, for any number \(a\), the probability that \(X\) is less than or equal to \(a\):
\[ F(a) = \Pr(X \leq a) \]
Once the CDF is defined, we can compute the probability that \(X\) falls within any interval. For example, the probability that a student’s height is between \(a\) and \(b\) is:
\[ \Pr(a < X \leq b) = F(b) - F(a) \]
Because we can determine the probability of any event from the CDF, it fully defines the probability distribution of a continuous outcome.
6.2 Probability density function
For most continuous distributions, we can describe the cumulative distribution function (CDF) in terms of another function, \(f(x)\), such that
\[ F(b) - F(a) = \int_a^b f(x)\,dx. \]
This function \(f(x)\) is called the probability density function (PDF).
The PDF plays a role similar to the relative frequency distribution for discrete data. The key difference is that for a continuous variable, individual values have probability zero, so instead of assigning probability to specific outcomes, the PDF shows how probability is spread across the range of possible values of \(x\). The probability that the variable falls within an interval, say \([a,b]\), is given by the area under the curve between \(a\) and \(b\). Thus, the shape of the PDF shows where values are more or less likely to occur, with wider or higher regions corresponding to ranges that contain more probability mass.
To build intuition for why we use a continuous function and an integral to describe probabilities, consider a situation where an outcome can be measured with very high precision. In this case, we can think of the relative frequency as being proportional to the height of the bars in the plot below:
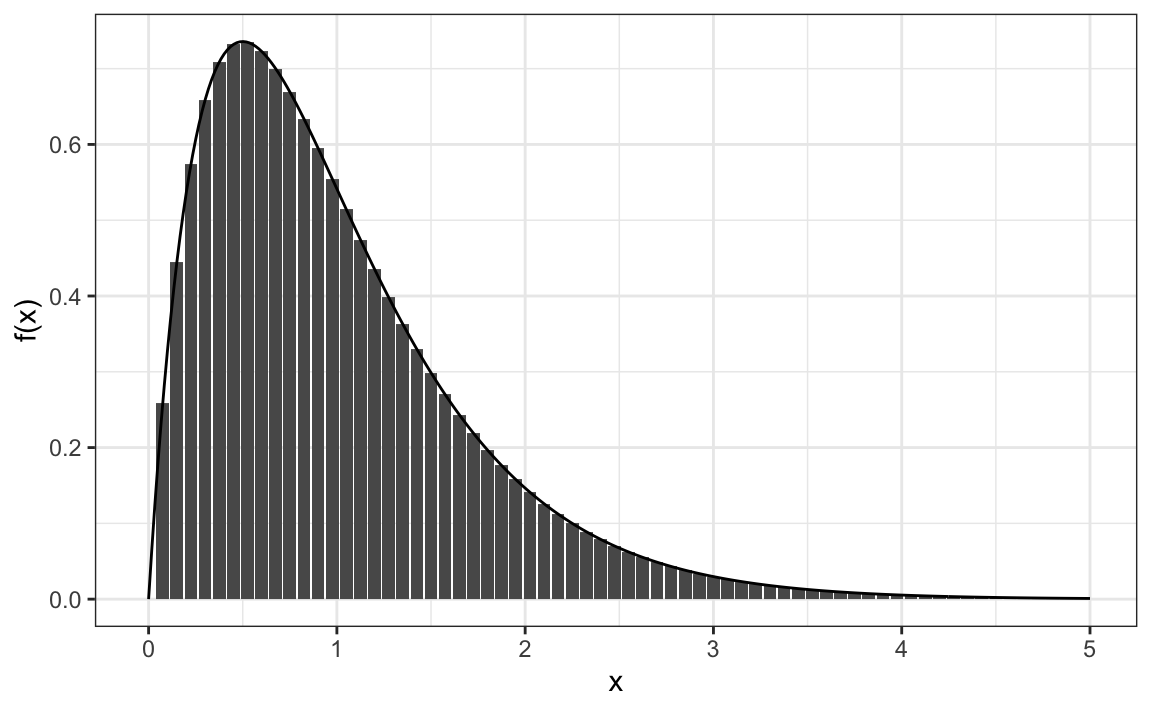
The probability of the outcome falling within an interval, such as the shaded range \(x \in [0.5, 1.5]\), can be approximated by adding the heights of the bars within that range and dividing by the total height of all bars. As the measurement becomes more precise and the bar widths become narrower, this sum approaches the area under the curve of the continuous function \(f(x)\).
In the limit where the bar widths shrink to zero, the sum and the integral are identical: the probability of \(x\) falling in an interval is exactly the area under \(f(x)\) over that interval. To make this work, we define \(f(x)\) so that the total area under the curve equals 1:
\[ \int_{-\infty}^{\infty} f(x) \, dx = 1 \]
This ensures that \(f(x)\) represents a valid PDF.
An important example of a PDF is the normal distribution, introduced in Section 2.1. Its probability density function is
\[ f(x) = \frac{1}{\sqrt{2\pi}\,\sigma} \exp\left(-\frac{1}{2}\left(\frac{x - \mu}{\sigma}\right)^2\right) \]
and, as we previously saw, has a bell shape centered at \(\mu\), with 95% of the area within \(2\sigma\) from \(\mu\)

In R, this PDF is given by dnorm and the corresponding CDF by pnorm.
A random outcome is said to be normally distributed with mean m and standard deviation s if its CDF is defined by
This is useful in many data applications. If we are willing to assume that a variable, such as height, follows a normal distribution, we can answer probability questions without needing the full dataset. For example, to find the probability that a randomly selected student is taller than 70.5 inches, we only need the sample mean and standard deviation:
6.3 Theoretical distributions as practical models
Theoretical distributions, such as the normal distribution, are defined mathematically rather than derived directly from data. In practice, we use them to approximate the behavior of real data that arise from complex or unknown processes. Almost all datasets we analyze consist of discrete observations, yet many of these quantities, such as height, weight, or blood pressure, are better understood as measurements of underlying continuous variables.
For example, our height data appear discrete because values are typically rounded to the nearest inch. A few individuals report more precise metric measurements, while most round to whole inches. Therefore, it is more realistic to think of height as a continuous variable whose apparent discreteness comes from rounding.
When using a continuous distribution such as the normal, we no longer assign probabilities to individual points—each exact value has probability zero—but rather to intervals. In Chapter 2, we showed how theoretical normal distributions can approximate the distribution of height data.
The key idea is that theoretical distributions serve as useful approximations. They provide smooth mathematical descriptions that let us compute probabilities and reason about uncertainty. Even though real measurements are discrete, the continuous approximations that apply, such as the normal distribution, allow us to work with data analytically and build models that generalize well beyond a specific dataset.
6.4 Monte Carlo simulations
Simulation is a powerful way to understand randomness, approximate probabilities, and explore how theoretical models behave in practice. Many of the probability models used in data analysis are continuous distributions, which describe outcomes that can take any value within a range. In R, all random-number–generating functions that produce simulated data from a distribution begin with the letter r. These functions form part of a consistent family that allows us to simulate from nearly any probability distribution. In this section, we illustrate Monte Carlo techniques using continuous distributions, starting with the normal distribution and extending to other commonly used models.
Normal distribution
R provides the rnorm function to generate normally distributed outcomes. It takes three arguments—sample size, mean (default 0), and standard deviation (default 1)—and produces random numbers that follow a normal distribution.
Here is an example of how we could generate data that resemble our reported heights:
Not surprisingly, the distribution of the simulated heights looks normal:

This is one of the most useful functions in R because it lets us generate data that mimic natural variation and explore what outcomes might occur by chance through Monte Carlo simulations.
Example: extreme values
How rare is it to find a seven-footer among 800 men? Suppose we repeatedly sample 800 male students at random and record the tallest in each group. What does the distribution of these tallest heights look like? The following Monte Carlo simulation helps us find out:
Having a seven-footer is quite rare:
mean(tallest >= 7*12)
#> [1] 0.0193Here is the resulting distribution of the tallest person’s height:
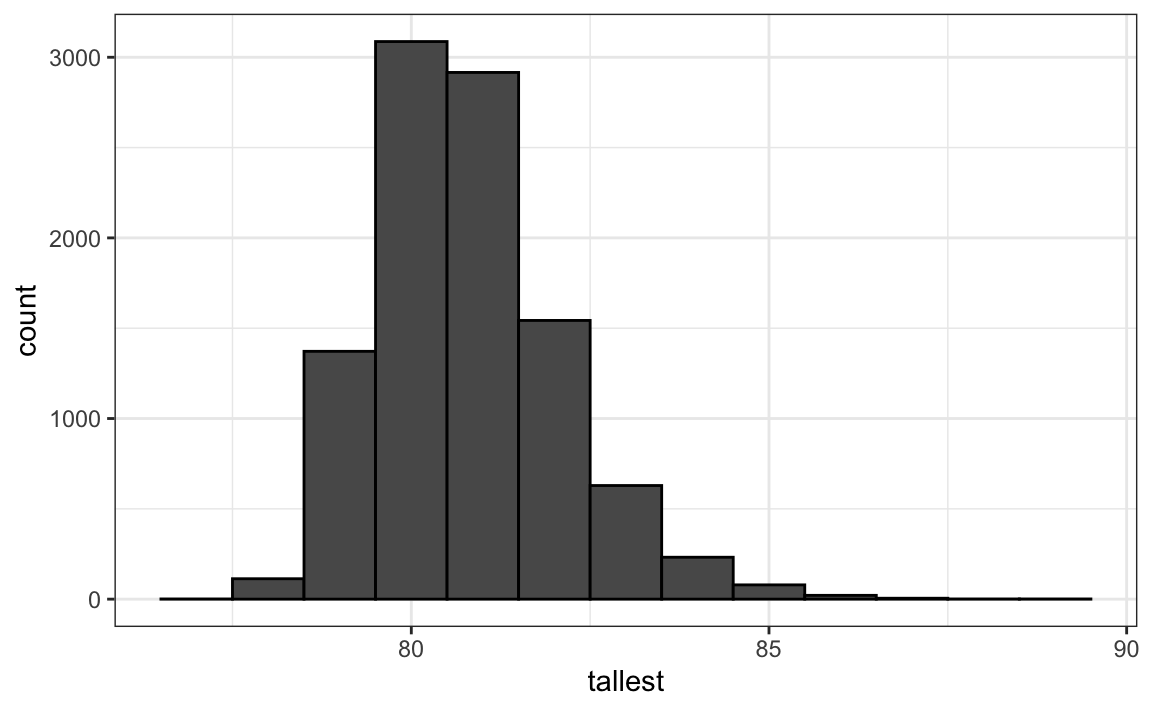
Although deriving this distribution analytically is possible, it is not straightforward. Once derived, it provides a faster way to evaluate probabilities than simulation. However, when analytic derivations are too complex or infeasible, Monte Carlo simulation offers a practical alternative. By repeatedly generating random samples, we can approximate the distribution of almost any statistic and obtain reliable estimates even when theoretical results are unavailable.
6.5 Calculating densities, probabilities, quantiles, and other continuous distributions
Beyond simulation, R provides companion functions to evaluate and summarize continuous distributions. Each distribution in base R follows a simple naming convention:
-
d- density function -
p- cumulative distribution function (CDF) -
q- quantile function -
r- random number generation
For example, the Student’s t distribution uses dt, pt, qt, and rt. Base R includes the most common continuous distributions, normal, t, chi-square, exponential, gamma, and beta (corresponding shorthand names in R are t, chisq, exp, gamma, and beta), but many additional distributions are available in specialized packages such as extraDistr and actuar. While there are dozens of continuous distributions in use, the ones provided by base R cover the majority of applications encountered in practice.
6.6 Beyond one variable
So far, we have focused on random variables representing just one outcome. In many applications, however, we are interested in several quantities at once. In these cases, we work with multivariate random variables, written as \((X_1, X_2, \ldots, X_k)\), where each \(X_i\) is a random variable.
Just as in the univariate case, we can describe the joint distribution of these variables using a probability density function. The joint probability density function \(f(x_1, x_2, \ldots, x_k)\) characterizes how probability is distributed across combinations of values. For continuous variables, probabilities are obtained by integrating this function over a region of the \(k\)-dimensional space.
Once a joint density is defined, we can recover familiar quantities such as marginal and conditional distributions. Intuitively, a marginal distribution describes the behavior of one variable on its own, ignoring the others. We obtain it by averaging out or integrating over the remaining variables. A conditional distribution, on the other hand, describes the behavior of one variable given that we know the value of another. This extends the idea of conditional probability introduced in Section 5.5 to the continuous setting.
These quantities can be derived from the joint density: marginals by integrating out variables, and conditionals by combining the joint density with the appropriate marginal. Carrying out these calculations requires tools from multivariate calculus, including integration over higher-dimensional regions.
These ideas extend naturally from the one-dimensional case and allow us to study relationships between variables, such as dependence and correlation. We will revisit these concepts later, in Section 15.3, particularly in the context of regression, where we use conditional distributions to describe how an outcome variable behaves given one or more predictors. We do not cover multivariate distributions in detail here, but we provide references for further reading in the recommended reading section.
6.7 Exercises
1. Assume the distribution of female heights is approximated by a normal distribution with a mean of 64 inches and a standard deviation of 3 inches. If we pick a female at random, what is the probability that she is 5 feet or shorter?
2. Assume the same distribution as the previous exercise. If we pick a female at random, what is the probability that she is 6 feet or taller?
3. Assume the same distribution as the previous exercise. If we pick a female at random, what is the probability that she is between 61 and 67 inches?
4. Repeat the exercise above, but convert everything to centimeters. That is, multiply every height, including the standard deviation, by 2.54. What is the answer now?
5. Notice that the answers to the previous two exercises are identical even when you change units. This makes sense since the standard deviations from the average for an entry in a list are not affected by what units we use. In fact, if you look closely, you notice that 61 and 67 are both 1 SD away from the average. Compute the probability that a randomly picked, normally distributed random outcome is within 1 SD of the average.
6. To understand the mathematical rationale that explains why the answers to exercises 3, 4, and 5 are the same, suppose we have a random outcome \(X\) with average \(\mu\) and standard deviation \(\sigma\) and that we ask what the probability of \(X\) being smaller than or equal to \(a\) is. The probability is:
\[ \mathrm{Pr}(X \leq a) \] Remember from Chapter 2’s discussion of standardized units that \(a\) is \((a - \mu)/\sigma\) standard deviations \(s\) away from the average \(\mu\). In our probability statement, we can subtract \(\mu\) from both sides and then divide both sides by \(\sigma\):
\[ \mathrm{Pr}\left(\frac{X-\mu}{\sigma} \leq \frac{a-\mu}{\sigma} \right) \]
The quantity on the left is a standard normal random outcome. It has an average of 0 and a standard deviation of 1. We will call it \(Z\):
\[ \mathrm{Pr}\left(Z \leq \frac{a-\mu}{\sigma} \right) \]
So, no matter the units of \(X\), the probability of \(X\leq a\) is the same as the probability of a standard normal variable being less than \((a - \mu)/s\).
If m is the average and s the standard deviation, which of the following R code would give us the right answer in every situation?
mean(X <= a)pnorm((a - m)/s)pnorm((a - m)/s, m, s)pnorm(a)
7. Imagine the distribution of male adults is approximately normal with a mean of 69 and a standard deviation of 3. How tall is the male in the 99th percentile? Hint: use qnorm.
8. IQ scores are approximately normally distributed, with a mean of 100 and a standard deviation of 15. Suppose we want to know what the distribution of the highest IQ would look like across all high school graduating classes if 10,000 people are born each year in a school district. Run a Monte Carlo simulation with B = 1000, where each iteration generates 10,000 IQ scores and records the highest value. Then, create a histogram to visualize the distribution of the maximum IQ in the district.