Capítulo 25 Cómo leer y procesar fechas y horas
25.1 Datos tipo fecha
Hemos descrito tres tipos principales de vectores: numéricos, de caracteres y lógicos. En proyectos de ciencia de datos, a menudo encontramos variables que son fechas. Aunque podemos representar una fecha con una cadena, por ejemplo November 2, 2017, una vez que elegimos un día de referencia, conocido como la época Unix (epoch en inglés), se pueden convertir en números calculando el número de días desde la época Unix. Los lenguajes de computadora usualmente usan el 1 de enero de 1970 como la época Unix. Entonces, por ejemplo, el 2 de enero de 2017 es el día 1, el 31 de diciembre de 1969 es el día -1 y el 2 de noviembre de 2017 es el día 17,204.
Ahora, ¿cómo debemos representar fechas y horas al analizar los datos en R? Podríamos usar días desde la época Unix, pero es casi imposible de interpretar. Si les digo que es el 2 de noviembre de 2017, saben lo que esto significa inmediatamente. Si les digo que es el día 17,204, estarán bastante confundidos. Problemas similares surgen con la hora e incluso pueden aparecer más complicaciones debido a las zonas horarias.
Por esta razón, R define un tipo de datos solo para fechas y horas. Vimos un ejemplo en los datos de las encuestas:
library(tidyverse)
library(dslabs)
data("polls_us_election_2016")
polls_us_election_2016$startdate |> head()
#> [1] "2016-11-03" "2016-11-01" "2016-11-02" "2016-11-04" "2016-11-03"
#> [6] "2016-11-03"Estas parecen cadenas, pero no lo son:
class(polls_us_election_2016$startdate)
#> [1] "Date"Miren lo que sucede cuando los convertimos en números:
as.numeric(polls_us_election_2016$startdate) |> head()
#> [1] 17108 17106 17107 17109 17108 17108Los convierte en días desde la época Unix. La función as.Date puede convertir un carácter en una fecha. Entonces, para ver que la época Unix es el día 0, podemos escribir:
as.Date("1970-01-01") |> as.numeric()
#> [1] 0Funciones que grafican, como las de ggplot2, conocen el formato de fecha. Esto significa que, por ejemplo, un diagrama de dispersión puede usar la representación numérica para decidir la posición del punto, pero incluir la cadena en las etiquetas:
polls_us_election_2016 |> filter(pollster == "Ipsos" & state == "U.S.") |>
ggplot(aes(startdate, rawpoll_trump)) +
geom_line()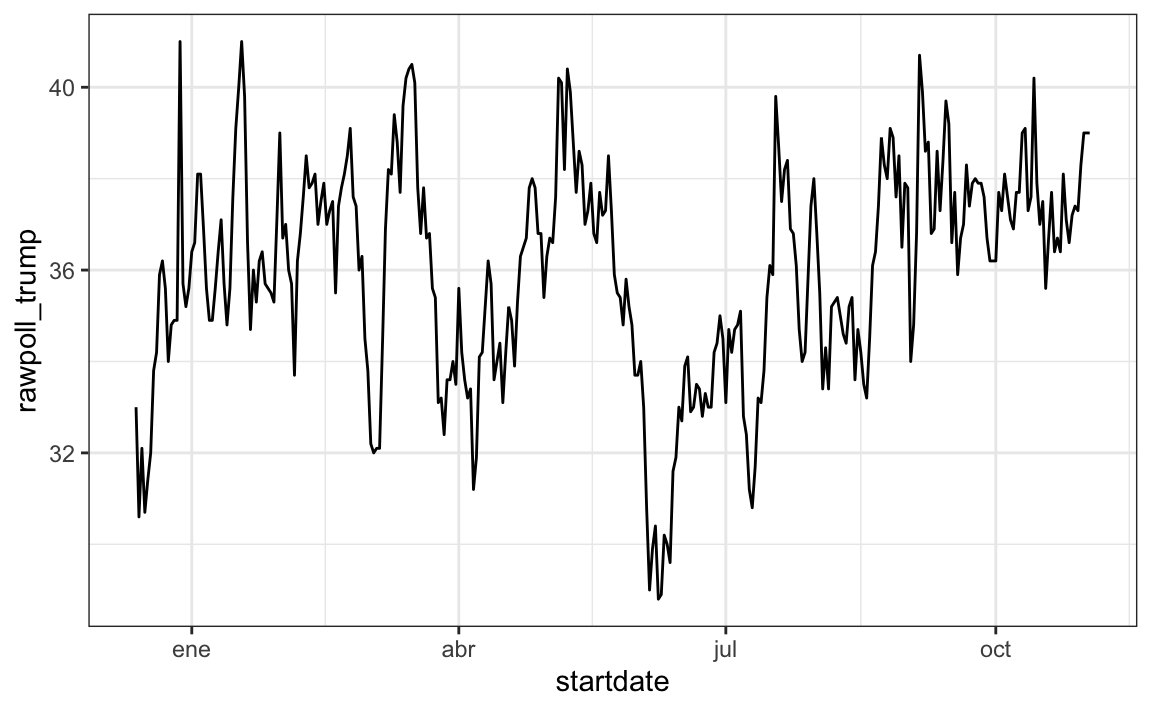
Noten que se muestran los nombres de los meses, una característica muy conveniente.
25.2 El paquete lubridate
El tidyverse incluye funcionalidad para manejar fechas a través del paquete lubridate.
library(lubridate)Tomaremos una muestra aleatoria de fechas para mostrar algunas de las cosas útiles que uno puede hacer:
set.seed(2002)
dates <- sample(polls_us_election_2016$startdate, 10) |> sort()
dates
#> [1] "2016-05-31" "2016-08-08" "2016-08-19" "2016-09-22" "2016-09-27"
#> [6] "2016-10-12" "2016-10-24" "2016-10-26" "2016-10-29" "2016-10-30"Las funciones year, month y day extraen esos valores:
tibble(date = dates,
month = month(dates),
day = day(dates),
year = year(dates))
#> # A tibble: 10 × 4
#> date month day year
#> <date> <dbl> <int> <dbl>
#> 1 2016-05-31 5 31 2016
#> 2 2016-08-08 8 8 2016
#> 3 2016-08-19 8 19 2016
#> 4 2016-09-22 9 22 2016
#> 5 2016-09-27 9 27 2016
#> # … with 5 more rowsTambién podemos extraer las etiquetas del mes:
month(dates, label = TRUE)
#> [1] may ago ago sep sep oct oct oct oct oct
#> 12 Levels: ene < feb < mar < abr < may < jun < jul < ago < ... < dicOtro conjunto útil de funciones son las que convierten cadenas en fechas. La función ymd supone que las fechas están en el formato AAAA-MM-DD e intenta leer y procesar (parse en inglés) lo mejor posible.
x <- c(20090101, "2009-01-02", "2009 01 03", "2009-1-4",
"2009-1, 5", "Created on 2009 1 6", "200901 !!! 07")
ymd(x)
#> [1] "2009-01-01" "2009-01-02" "2009-01-03" "2009-01-04" "2009-01-05"
#> [6] "2009-01-06" "2009-01-07"Otra complicación proviene del hecho de que las fechas a menudo vienen en diferentes formatos donde el orden de año, mes y día son diferentes. El formato preferido es mostrar año (con los cuatro dígitos), mes (dos dígitos) y luego día (dos dígitos), o lo que se llama ISO 8601. Específicamente, usamos AAAA-MM-DD para que si ordenamos la cadena, estará ordenado por fecha. Pueden ver que la función ymd las devuelve en este formato.
Pero, ¿qué pasa si encuentran fechas como “01/09/02”? Esto podría ser el 1 de septiembre de 2002 o el 2 de enero de 2009 o el 9 de enero de 2002. En estos casos, examinar todo el vector de fechas los ayudará a determinar qué formato es por proceso de eliminación. Una vez que sepan, pueden usar las muchas funciones ofrecidas por lubridate.
Por ejemplo, si la cadena es:
x <- "09/01/02"La función ymd supone que la primera entrada es el año, la segunda es el mes y la tercera es el día, por lo que la convierte a:
ymd(x)
#> [1] "2009-01-02"La función mdy supone que la primera entrada es el mes, luego el día y entonces el año:
mdy(x)
#> [1] "2002-09-01"El paquete lubridate ofrece una función para cada posibilidad:
ydm(x)
#> [1] "2009-02-01"
myd(x)
#> [1] "2001-09-02"
dmy(x)
#> [1] "2002-01-09"
dym(x)
#> [1] "2001-02-09"El paquete lubridate también es útil para lidiar con los tiempos. En base R, pueden obtener la hora actual escribiendo Sys.time(). El paquete lubridate ofrece una función un poco más avanzada, now, que les permite definir la zona horaria:
now()
#> [1] "2022-10-30 13:21:02 EDT"
now("GMT")
#> [1] "2022-10-30 17:21:02 GMT"Pueden ver todas las zonas horarias disponibles con la función OlsonNames().
También podemos extraer horas, minutos y segundos:
now() |> hour()
#> [1] 13
now() |> minute()
#> [1] 21
now() |> second()
#> [1] 2.37El paquete también incluye una función para convertir cadenas en horas del día, así como funciones que convierten objetos que representan horas del día, que además incluyen las fechas:
x <- c("12:34:56")
hms(x)
#> [1] "12H 34M 56S"
x <- "Nov/2/2012 12:34:56"
mdy_hms(x)
#> [1] "2012-11-02 12:34:56 UTC"Este paquete tiene muchas otras funciones útiles. Aquí describimos dos que consideramos particularmente útiles.
La función make_date se puede utilizar para rápidamente crear un objeto de fecha. Por ejemplo, para crear un objeto de fecha que represente el 6 de julio de 2019, escribimos:
make_date(2019, 7, 6)
#> [1] "2019-07-06"Para hacer un vector del 1 de enero para los años 80 escribimos:
make_date(1980:1989)
#> [1] "1980-01-01" "1981-01-01" "1982-01-01" "1983-01-01" "1984-01-01"
#> [6] "1985-01-01" "1986-01-01" "1987-01-01" "1988-01-01" "1989-01-01"Otra función muy útil es round_date. Se puede utilizar para redondear las fechas al año, trimestre, mes, semana, día, hora, minutos o segundos más cercanos. Entonces, si queremos agrupar todas las encuestas por semana del año, podemos hacer lo siguiente:
polls_us_election_2016 |>
mutate(week = round_date(startdate, "week")) |>
group_by(week) |>
summarize(margin = mean(rawpoll_clinton - rawpoll_trump)) |>
qplot(week, margin, data = _)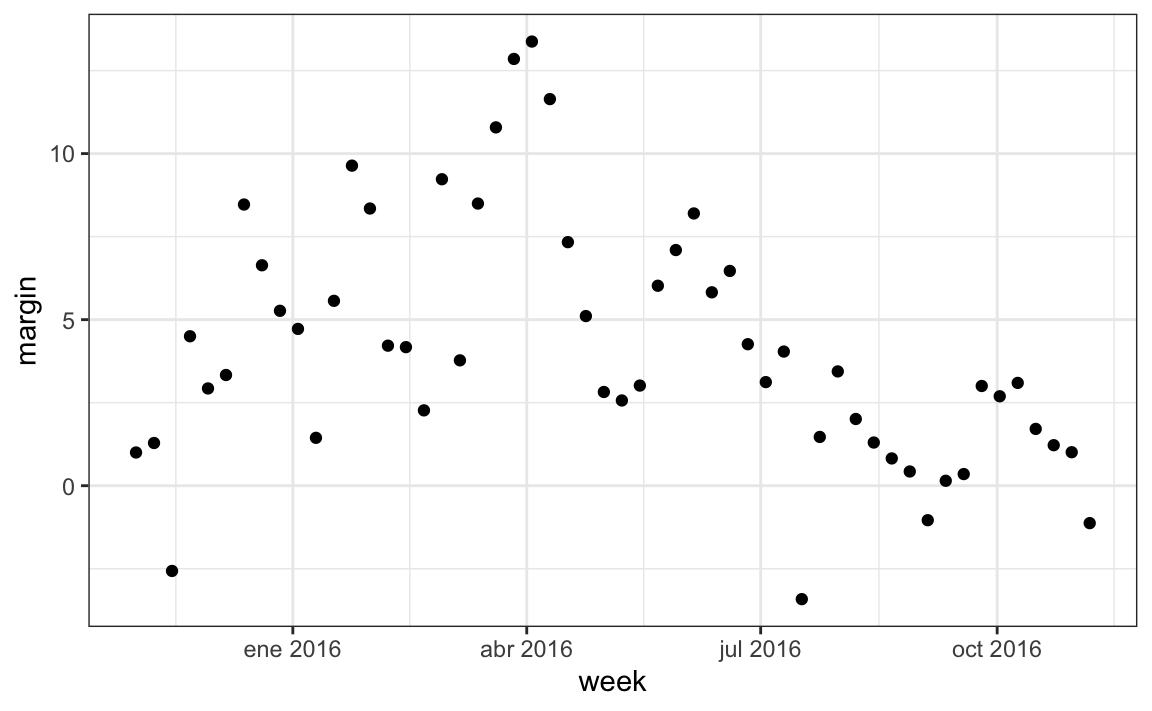
25.3 Ejercicios
En la sección de ejercicios anterior, depuramos datos de un archivo PDF que contiene estadísticas vitales de Puerto Rico. Hicimos esto para el mes de septiembre. A continuación incluimos un código que lo hace durante los 12 meses.
library(tidyverse)
library(lubridate)
library(purrr)
library(pdftools)
library(dslabs)
fn <- system.file("extdata", "RD-Mortality-Report_2015-18-180531.pdf",
package="dslabs")
dat <- map_df(str_split(pdf_text(fn), "\n"), function(s){
s <- str_trim(s)
header_index <- str_which(s, "2015")[1]
tmp <- str_split(s[header_index], "\\s+", simplify = TRUE)
month <- tmp[1]
header <- tmp[-1]
tail_index <- str_which(s, "Total")
n <- str_count(s, "\\d+")
out <- c(1:header_index, which(n == 1),
which(n >= 28), tail_index:length(s))
s[-out] |> str_remove_all("[^\\d\\s]") |> str_trim() |>
str_split_fixed("\\s+", n = 6) |> .[,1:5] |> as_tibble() |>
setNames(c("day", header)) |>
mutate(month = month, day = as.numeric(day)) |>
pivot_longer(-c(day, month), names_to = "year", values_to = "deaths") |>
mutate(deaths = as.numeric(deaths))
}) |>
mutate(month = recode(month,
"JAN" = 1, "FEB" = 2, "MAR" = 3,
"APR" = 4, "MAY" = 5, "JUN" = 6,
"JUL" = 7, "AGO" = 8, "SEP" = 9,
"OCT" = 10, "NOV" = 11, "DEC" = 12)) |>
mutate(date = make_date(year, month, day)) |>
filter(date <= "2018-05-01")1. Queremos hacer un gráfico de recuentos de muertes versus fecha. Un primer paso es convertir la variable del mes de caracteres a números. Tenga en cuenta que las abreviaturas de los meses están en espanglés. Utilice la función recode para convertir meses en números y redefinir tab.
2. Cree una nueva columna date con la fecha de cada observación. Sugerencia: use la función make_date.
3. Grafique muertes versus fecha.
4. Noten que después del 31 de mayo de 2018, las muertes son todas 0. Los datos probablemente aún no se han ingresado. También vemos una caída a partir del 1 de mayo. Redefina tab para excluir observaciones tomadas a partir del 1 de mayo de 2018. Luego, rehaga el gráfico.
5. Vuelva a hacer el gráfico anterior, pero esta vez grafique las muertes versus el día del año; por ejemplo, 12 de enero de 2016 y 12 de enero de 2017, son ambos el día 12. Use el color para indicar los diferentes años. Sugerencia: use la función yday de lubridate .
6. Vuelva a hacer el gráfico anterior pero, esta vez, use dos colores diferentes para antes y después del 20 de septiembre de 2017.
7. Avanzado: rehaga el gráfico anterior, pero esta vez muestre el mes en el eje-x. Sugerencia: cree una variable con la fecha de un año determinado. Luego, use la función scale_x_date para mostrar solo los meses.
8. Rehaga las muertes versus el día pero con promedios semanales. Sugerencia: use la función round_date.
9. Rehaga el gráfico pero con promedios mensuales. Sugerencia: use la función round_date de nuevo.