Capítulo 24 Procesamiento de cadenas
Uno de los desafíos más comunes del wrangling de datos consiste en extraer datos numéricos contenidos en cadenas de caracteres y convertirlos en las representaciones numéricas requeridas para hacer gráficos, calcular resúmenes o ajustar modelos en R. También, es común tener que procesar texto no organizado y convertirlo en nombres de variables entendibles o variables categóricas. Muchos de los desafíos de procesamiento de cadenas que enfrentan los científicos de datos son únicos y a menudo inesperados. Por lo tanto, es bastante ambicioso escribir una sección completa sobre este tema. Aquí usamos una serie de estudios de casos que nos ayudan a demostrar cómo el procesamiento de cadenas es un paso necesario para muchos desafíos de disputas de datos. Específicamente, para los ejemplos murders, heights y research_funding_rates, describimos el proceso de convertir los datos sin procesar originales, que aún no hemos mostrados, en los data frames que hemos estudiado en este libro.
Al repasar estos estudios de caso, cubriremos algunas de las tareas más comunes en el procesamiento de cadenas, incluyendo cómo extraer números de cadenas, eliminar caracteres no deseados del texto, encontrar y reemplazar caracteres, extraer partes específicas de cadenas, convertir texto de forma libre a formatos más uniformes y dividir cadenas en múltiples valores.
Base R incluye funciones para realizar todas estas tareas. Sin embargo, no siguen una convención unificadora, lo que las hace un poco difíciles de memorizar y usar. El paquete stringr reempaqueta esta funcionalidad, pero utiliza un enfoque más consistente de nombrar funciones y ordenar sus argumentos. Por ejemplo, en stringr, todas las funciones de procesamiento de cadenas comienzan con str_. Esto significa que si escriben str_ y presionan tab, R se completará automáticamente y mostrará todas las funciones disponibles. Como resultado, no tenemos que memorizar todos los nombres de las funciones. Otra ventaja es que en las funciones de este paquete, la cadena que se procesa siempre es el primer argumento, que significa que podemos usar el pipe más fácilmente. Por lo tanto, comenzaremos describiendo cómo usar las funciones en el paquete stringr.
La mayoría de los ejemplos provendrán del segundo estudio de caso que trata sobre las alturas autoreportadas por los estudiantes y la mayor parte del capítulo se dedica al aprendizaje de expresiones regulares (regular expressions o regex en inglés) y funciones en el paquete stringr.
24.1 El paquete stringr
library(tidyverse)
library(stringr)En general, las tareas de procesamiento de cadenas se pueden dividir en detectar, localizar, extraer o reemplazar patrones en cadenas. Veremos varios ejemplos. La siguiente tabla incluye las funciones disponibles en el paquete stringr. Las dividimos por tarea. También incluimos el equivalente de base R cuando está disponible.
Todas estas funciones toman un vector de caracteres como primer argumento. Además, para cada función, las operaciones se vectorizan: la operación se aplica a cada cadena en el vector.
Finalmente, tengan en cuenta que en esta tabla mencionamos groups. Estos se explicarán en la Sección 24.5.9.
| stringr | Tarea | Descripción | Base R |
|---|---|---|---|
str_detect |
Detectar | ¿El patrón está en la cadena? | grepl |
str_which |
Detectar | Devuelve el índice de entradas que contienen el patrón. | grep |
str_subset |
Detectar | Devuelve el subconjunto de cadenas que contienen el patrón. | grep con value = TRUE |
str_locate |
Localizar | Devuelve las posiciones de la primera aparición del patrón en una cadena. | regexpr |
str_locate_all |
Localizar | Devuelve la posición de todas las apariciones del patrón en una cadena. | gregexpr |
str_view |
Localizar | Muestra la primera parte de la cadena que corresponde con el patrón. | |
str_view_all |
Localizar | Muestra todas las partes de la cadena que corresponden con el patrón. | |
str_extract |
Extraer | Extrae la primera parte de la cadena que corresponde con el patrón. | |
str_extract_all |
Extraer | Extrae todas las partes de la cadena que corresponden con el patrón. | |
str_match |
Extraer | Extrae la primera parte de la cadena que corresponde con los grupos y los patrones definidos por los grupos. | |
str_match_all |
Extraer | Extrae todas las partes de la cadena que corresponden con los grupos y los patrones definidos por los grupos. | |
str_sub |
Extraer | Extrae una subcadena. | substring |
str_split |
Extraer | Divide una cadena en una lista con partes separadas por patrón. | strsplit |
str_split_fixed |
Extraer | Divide una cadena en una matriz con partes separadas por patrón. | strsplit con fixed = TRUE |
str_count |
Describir | Cuenta el número de veces que aparece un patrón en una cadena. | |
str_length |
Describir | Número de caracteres en la cadena. | nchar |
str_replace |
Reemplazar | Reemplaza la primera parte de una cadena que corresponde con un patrón con otro patrón. | |
str_replace_all |
Reemplazar | Reemplaza todas las partes de una cadena que corresponden con un patrón con otro patrón. | gsub |
str_to_upper |
Reemplazar | Cambia todos los caracteres a mayúsculas. | toupper |
str_to_lower |
Reemplazar | Cambia todos los caracteres a minúsculas. | tolower |
str_to_title |
Reemplazar | Cambia el primer carácter a mayúscula y el resto a minúscula. | |
str_replace_na |
Reemplazar | Reemplaza todo los NAs con un nuevo valor. |
|
str_trim |
Reemplazar | Elimina el espacio en blanco del inicio y del final de la cadena. | |
str_c |
Manipular | Une múltiples cadenas. | paste0 |
str_conv |
Manipular | Cambia la codificación de la cadena. | |
str_sort |
Manipular | Pone el vector en orden alfabético. | sort |
str_order |
Manipular | Índice necesario para ordenar el vector alfabéticamente. | order |
str_trunc |
Manipular | Trunca una cadena a un tamaño fijo. | |
str_pad |
Manipular | Agrega espacio en blanco a la cadena para que tenga un tamaño fijo. | |
str_dup |
Manipular | Repite una cadena. | rep luego paste |
str_wrap |
Manipular | Pone la cadena en párrafos formateados. | |
str_interp |
Manipular | Interpolación de cadenas. | sprintf |
24.2 Estudio de caso 1: datos de asesinatos en EE. UU.
En esta sección presentamos algunos de los desafíos más sencillos de procesamiento de cadenas, con los siguientes sets de datos como ejemplo:
library(rvest)
url <- paste0("https://en.wikipedia.org/w/index.php?title=",
"Gun_violence_in_the_United_States_by_state",
"&direction=prev&oldid=810166167")
murders_raw <- read_html(url) |>
html_node("table") |>
html_table() |>
setNames(c("state", "population", "total", "murder_rate"))El código anterior muestra el primer paso para construir el set de datos,
library(dslabs)
data(murders)de los datos sin procesar, que se extrajeron de una página de Wikipedia.
En general, el procesamiento de cadenas implica una cadena y un patrón. En R, generalmente almacenamos cadenas en un vector de caracteres como murders$population. Las primeras tres cadenas en este vector definidas por la variable de población son:
murders_raw$population[1:3]
#> [1] "4,853,875" "737,709" "6,817,565"Forzar una conversión usando as.numeric no funciona aquí:
as.numeric(murders_raw$population[1:3])
#> Warning: NAs introducidos por coerción
#> [1] NA NA NAEsto se debe a las comas ,. El procesamiento de cadenas que queremos hacer aquí es eliminar el patrón ” ,” de las cadenas en murders_raw$population y luego forzar una conversión de los números.
Podemos usar la función str_detect para ver que dos de las tres columnas tienen comas en las entradas:
commas <- function(x) any(str_detect(x, ","))
murders_raw |> summarize_all(commas)
#> # A tibble: 1 × 4
#> state population total murder_rate
#> <lgl> <lgl> <lgl> <lgl>
#> 1 FALSE TRUE TRUE FALSEEntonces podemos usar la función str_replace_all para eliminarlas:
test_1 <- str_replace_all(murders_raw$population, ",", "")
test_1 <- as.numeric(test_1)De ahí podemos usar mutate_all para aplicar esta operación a cada columna, ya que no afectará a las columnas sin comas.
Resulta que esta operación es tan común que readr incluye la función parse_number específicamente para eliminar caracteres no numéricos antes de forzar una conversión:
test_2 <- parse_number(murders_raw$population)
identical(test_1, test_2)
#> [1] TRUEEntonces podemos obtener nuestra tabla deseada usando:
murders_new <- murders_raw |> mutate_at(2:3, parse_number)
head(murders_new)
#> # A tibble: 6 × 4
#> state population total murder_rate
#> <chr> <dbl> <dbl> <dbl>
#> 1 Alabama 4853875 348 7.2
#> 2 Alaska 737709 59 8
#> 3 Arizona 6817565 309 4.5
#> 4 Arkansas 2977853 181 6.1
#> 5 California 38993940 1861 4.8
#> # … with 1 more rowEste caso es relativamente sencillo en comparación con los desafíos de procesamiento de cadenas que normalmente enfrentamos en la ciencia de datos. El siguiente ejemplo es bastante complejo y ofrece varios retos que nos permitirán aprender muchas técnicas de procesamiento de cadenas.
24.3 Estudio de caso 2: alturas autoreportadas
El paquete dslabs incluye el set de datos sin procesar del cual se obtuvo el set de datos de alturas. Pueden cargarlo así:
data(reported_heights)Estas alturas se obtuvieron mediante un formulario web en el que se les pidió a estudiantes que ingresaran sus alturas. Podían ingresar cualquier cosa, pero las instrucciones pedían altura en pulgadas, un número. Recopilamos 1,095 respuestas, pero desafortunadamente el vector de columna con las alturas reportadas tenía varias entradas no numéricas y como resultado se convirtió en un vector de caracteres:
class(reported_heights$height)
#> [1] "character"Si intentamos analizarlo en números, recibimos una advertencia:
x <- as.numeric(reported_heights$height)
#> Warning: NAs introducidos por coerciónAunque la mayoría de los valores parecen ser la altura en pulgadas según lo solicitado:
head(x)
#> [1] 75 70 68 74 61 65terminamos con muchos NAs:
sum(is.na(x))
#> [1] 81Podemos ver algunas de las entradas que no se convierten correctamente utilizando filter para mantener solo las entradas que resultan en NAs:
reported_heights |>
mutate(new_height = as.numeric(height)) |>
filter(is.na(new_height)) |>
head(n=10)
#> time_stamp sex height new_height
#> 1 2014-09-02 15:16:28 Male 5' 4" NA
#> 2 2014-09-02 15:16:37 Female 165cm NA
#> 3 2014-09-02 15:16:52 Male 5'7 NA
#> 4 2014-09-02 15:16:56 Male >9000 NA
#> 5 2014-09-02 15:16:56 Male 5'7" NA
#> 6 2014-09-02 15:17:09 Female 5'3" NA
#> 7 2014-09-02 15:18:00 Male 5 feet and 8.11 inches NA
#> 8 2014-09-02 15:19:48 Male 5'11 NA
#> 9 2014-09-04 00:46:45 Male 5'9'' NA
#> 10 2014-09-04 10:29:44 Male 5'10'' NAInmediatamente vemos lo que está sucediendo. Algunos de los estudiantes no reportaron sus alturas en pulgadas según lo solicitado. Podríamos descartar estos datos y continuar. Sin embargo, muchas de las entradas siguen patrones que, en principio, podemos convertir fácilmente a pulgadas. Por ejemplo, en el resultado anterior, vemos varios casos que usan el formato x'y'' con x e y representando pies y pulgadas, respectivamente. Cada uno de estos casos puede ser leído y convertido a pulgadas por un humano, por ejemplo 5'4'' es 5*12 + 4 = 64. Entonces podríamos arreglar todas las entradas problemáticas a mano. Sin embargo, los humanos son propensos a cometer errores, por lo que es preferible un enfoque automatizado. Además, debido a que planeamos continuar recolectando datos, será conveniente escribir código que lo haga automáticamente.
Un primer paso en este tipo de tarea es examinar las entradas problemáticas e intentar definir patrones específicos seguidos por un gran grupo de entradas. Cuanto más grandes sean estos grupos, más entradas podremos arreglar con un solo enfoque programático. Queremos encontrar patrones que puedan describirse con precisión con una regla, como “un dígito, seguido por un símbolo de pie, seguido por uno o dos dígitos, seguido por un símbolo de pulgadas”.
Para buscar dichos patrones, es útil eliminar las entradas que son consistentes con estar en pulgadas y ver solo las entradas problemáticas. Por lo tanto, escribimos una función para hacer esto automáticamente. Mantenemos entradas que resultan en NAs al aplicar as.numeric o que están fuera de un rango de alturas plausibles. Permitimos un rango que cubre aproximadamente el 99.9999% de la población adulta. También usamos suppressWarnings para evitar el mensaje de advertencia que sabemos que as.numeric nos da.
not_inches <- function(x, smallest = 50, tallest = 84){
inches <- suppressWarnings(as.numeric(x))
ind <- is.na(inches) | inches < smallest | inches > tallest
ind
}Aplicamos esta función y encontramos el número de entradas problemáticas:
problems <- reported_heights |>
filter(not_inches(height)) |>
pull(height)
length(problems)
#> [1] 292Ahora podemos ver todos los casos simplemente imprimiéndolos. No hacemos eso aquí porque hay length(problems), pero después de examinarlos cuidadosamente, vemos que podemos usar tres patrones para definir tres grandes grupos dentro de estas excepciones.
1. Un patrón de la forma x'y o x' y'' o x'y" con x e y representando pies y pulgadas, respectivamente. Aquí hay diez ejemplos:
#> 5' 4" 5'7 5'7" 5'3" 5'11 5'9'' 5'10'' 5' 10 5'5" 5'2"2. Un patrón de la forma x.y o x,y con x pies y y pulgadas. Aquí hay diez ejemplos:
#> 5.3 5.5 6.5 5.8 5.6 5,3 5.9 6,8 5.5 6.23. Entradas en centímetros en vez de pulgadas. Aquí hay diez ejemplos:
#> 150 175 177 178 163 175 178 165 165 180Una vez que veamos que estos grupos grandes siguen patrones específicos, podemos desarrollar un plan de ataque. Recuerden que raras veces hay una sola forma de realizar estas tareas. Aquí elegimos una que nos ayuda a enseñar varias técnicas útiles, aunque seguramente hay una forma más eficiente de realizar la tarea.
Plan de ataque: convertiremos las entradas que siguen a los dos primeros patrones en una estandarizada. Luego, aprovecharemos la estandarización para extraer los pies y pulgadas y convertirlos a pulgadas. Entonces, definiremos un procedimiento para identificar entradas que están en centímetros y convertirlas a pulgadas. Después de aplicar estos pasos, verificaremos nuevamente para ver qué entradas no se corrigieron y ver si podemos ajustar nuestro enfoque para que sea más completo.
Al final, esperamos tener un script que haga que los métodos de recolección de datos basados en la web sean robustos para los errores más comunes de los usuarios.
Para lograr nuestro objetivo, utilizaremos una técnica que nos permite detectar con precisión patrones y extraer las partes que queremos: expresiones regulares. Pero primero, describimos rápidamente cómo escaparse (“escapar” viene de la tecla esc o escape) de la función de ciertos caracteres para que se puedan incluir en cadenas.
24.4 Cómo escapar al definir cadenas
Para definir cadenas en R, podemos usar comillas dobles:
s <- "Hello!"o comillas simples:
s <- 'Hello!'Asegúrense de elegir la comilla simple correcta, ya que usar la comilla inversa le dará un error:
s <- `Hello`Error: object 'Hello' not foundAhora, ¿qué sucede si la cadena que queremos definir incluye comillas dobles? Por ejemplo, si queremos escribir 10 pulgadas así: 10"?
En este caso no pueden usar:
s <- "10""porque esto es solo la cadena 10 seguido por una comilla doble. Si escriben esto en R, obtendrán un error porque tiene comillas doble sin cerrar. Para evitar esto, podemos usar las comillas simples:
s <- '10"'Si imprimimos s, vemos que escapamos las comillas dobles con la barra diagonal inversa \.
s
#> [1] "10\""De hecho, escapar con la barra diagonal inversa ofrece una forma de definir la cadena y a la vez seguir utilizando las comillas dobles para definir cadenas:
s <- "10\""En R, la función cat nos permite ver como se ve la cadena:
cat(s)
#> 10"Ahora, ¿qué pasa si queremos que nuestra cadena sea de 5 pies escrita así: 5'? En ese caso, podemos usar las comillas dobles:
s <- "5'"
cat(s)
#> 5'Así que hemos aprendido a escribir 5 pies y 10 pulgadas por separado, pero ¿qué pasa si queremos escribirlos juntos para representar 5 pies y 10 pulgadas así: 5'10"? En este caso, ni las comillas simples ni las dobles funcionarán. Esto:
s <- '5'10"'cierra la cadena después de 5 y esto:
s <- "5'10""cierra la cadena después de 10. Tengan en cuenta que si escribimos uno de los fragmentos de código anteriores en R, se atascará esperando que cierren la comilla abierta y tendrán que salir de la ejecución con la tecla esc.
En esta situación, necesitamos escapar de la función de las comillas con la barra diagonal inversa \. Pueden escapar cualquiera de los dos de la siguiente manera:
s <- '5\'10"'
cat(s)
#> 5'10"o así:
s <- "5'10\""
cat(s)
#> 5'10"Los caracteres de escape son algo que a menudo tenemos que usar al procesar cadenas.
24.5 Expresiones regulares
Las expresiones regulares (regex) son una forma de describir patrones específicos de caracteres de texto. Se pueden usar para determinar si una cadena dada corresponde con el patrón. Se ha definido un conjunto de reglas para hacer esto de manera eficiente y precisa y aquí mostramos algunos ejemplos. Podemos aprender más sobre estas reglas leyendo tutoriales detallados96 97. La hoja de referencia de RStudio también es muy útil98.
Los patrones suministrados a las funciones stringr pueden ser una expresión regular en lugar de una cadena estándar. Aprenderemos cómo funciona esto a través de una serie de ejemplos.
A lo largo de esta sección, verán que creamos cadenas para probar nuestra expresión regular. Para hacer esto, definimos patrones que sabemos deben corresponder y también patrones que sabemos no deben corresponder. Los llamaremos yes y no, respectivamente. Esto nos permite verificar los dos tipos de errores: no corresponder o corresponder incorrectamente.
24.5.1 Las cadenas son expresiones regulares
Técnicamente, cualquier cadena es una expresión regular, quizás el ejemplo más simple es un solo carácter. Entonces la coma , usada en el siguiente ejemplo de código, es un ejemplo sencillo de una búsqueda con expresiones regulares.
pattern <- ","
str_detect(murders_raw$total, pattern)Suprimimos el output que es un vector lógico que nos dice qué entradas tienen comas.
Arriba, notamos que una entrada incluía un cm. Este es también un ejemplo simple de una expresión regular. Podemos mostrar todas las entradas que usaron cm así:
str_subset(reported_heights$height, "cm")
#> [1] "165cm" "170 cm"24.5.2 Caracteres especiales
Ahora consideremos un ejemplo un poco más complicado. ¿Cuál de las siguientes cadenas contiene el patrón cm o inches?
yes <- c("180 cm", "70 inches")
no <- c("180", "70''")
s <- c(yes, no)str_detect(s, "cm") | str_detect(s, "inches")
#> [1] TRUE TRUE FALSE FALSESin embargo, no necesitamos hacer esto. La característica principal que distingue el lenguaje de las expresiones regulares de cadenas es que podemos usar caracteres especiales. Estos son caracteres con un significado. Comenzamos presentando | que significa o. Entonces, si queremos saber si cm o inches aparece en las cadenas, podemos usar la expresión regular cm|inches:
str_detect(s, "cm|inches")
#> [1] TRUE TRUE FALSE FALSEy obtener la respuesta correcta.
Otro carácter especial que será útil para identificar valores de pies y pulgadas es \d que significa cualquier dígito: 0, 1, 2, 3, 4, 5, 6, 7, 8, 9. La barra inversa se utiliza para distinguirlo del carácter d. En R, tenemos que escapar de la barra inversa \ así que tenemos que usar \\d para representar dígitos. Aquí hay un ejemplo:
yes <- c("5", "6", "5'10", "5 feet", "4'11")
no <- c("", ".", "Five", "six")
s <- c(yes, no)
pattern <- "\\d"
str_detect(s, pattern)
#> [1] TRUE TRUE TRUE TRUE TRUE FALSE FALSE FALSE FALSEAprovechamos esta oportunidad para presentar la función str_view, que es útil para la solución de problemas ya que nos muestra la primera ocurrencia que corresponde exactamente para cada cadena:
str_view(s, pattern)
y str_view_all nos muestra todos los patrones que corresponden. Entonces, 3'2 tiene dos equivalencias y 5'10 tiene tres.
str_view_all(s, pattern)
Hay muchos otros caracteres especiales. Aprenderemos algunos mas a continuación, pero pueden ver la mayoría o todos en la hoja de referencia mencionada anteriormente99.
24.5.3 Clases de caracteres
Las clases de caracteres se utilizan para definir una serie de caracteres que pueden corresponder. Definimos clases de caracteres entre corchetes [ ]. Entonces, por ejemplo, si queremos que el patrón corresponda solo si tenemos un 5 o un 6, usamos la expresión regular [56]:
str_view(s, "[56]")
Supongan que queremos unir valores entre 4 y 7. Una forma común de definir clases de caracteres es con rangos. Así por ejemplo, [0-9] es equivalente a \\d. El patrón que queremos entonces es [4-7].
yes <- as.character(4:7)
no <- as.character(1:3)
s <- c(yes, no)
str_detect(s, "[4-7]")
#> [1] TRUE TRUE TRUE TRUE FALSE FALSE FALSESin embargo, es importante saber que en regex todo es un carácter; no hay números. Por eso 4 es el carácter 4 y no el número cuatro. Noten, por ejemplo, que [1-20] no significa 1 a 20, significa los caracteres 1 a 2 o el carácter 0. Entonces [1-20] simplemente significa la clase de caracteres compuesta por 0, 1 y 2.
Tengan en cuenta que los caracteres tienen un orden y los dígitos siguen el orden numérico. Entonces 0 viene antes de 1 que viene antes de 2 y así. Por la misma razón, podemos definir letras minúsculas como [a-z], letras mayúsculas como [A-Z] y [a-zA-z] como ambas.
24.5.4 Anclas
¿Y si queremos una correspondencia cuando tenemos exactamente 1 dígito? Esto será útil en nuestro estudio de caso, ya que los pies nunca tienen más de 1 dígito, por lo que esta restricción nos ayudará. Una forma de hacer esto con regex es usando anclas (anchors en inglés), que nos permiten definir patrones que deben comenzar o terminar en un lugar específico. Las dos anclas más comunes son
^ y $ que representan el comienzo y el final de una cadena, respectivamente. Entonces el patrón ^\\d$ se lee como “inicio de la cadena seguido por un dígito seguido por el final de la cadena”.
Este patrón ahora solo detecta las cadenas con exactamente un dígito:
pattern <- "^\\d$"
yes <- c("1", "5", "9")
no <- c("12", "123", " 1", "a4", "b")
s <- c(yes, no)
str_view_all(s, pattern)
El 1 no corresponde porque no comienza con el dígito sino con un espacio, que no es fácil de ver.
24.5.5 Cuantificadores
Para la parte de pulgadas, podemos tener uno o dos dígitos. Esto se puede especificar en regex con cuantificadores (quantifiers en inglés). Esto se hace siguiendo el patrón con la cantidad de veces que se puede repetir cerrada por llaves. Usemos un ejemplo para ilustrar. El patrón para uno o dos dígitos es:
pattern <- "^\\d{1,2}$"
yes <- c("1", "5", "9", "12")
no <- c("123", "a4", "b")
str_view(c(yes, no), pattern)
En este caso, 123 no corresponde, pero 12 sí. Entonces, para buscar nuestro patrón de pies y pulgadas, podemos agregar los símbolos para pies ' y pulgadas " después de los dígitos.
Con lo que hemos aprendido, ahora podemos construir un ejemplo para el patrón x'y\" con x pies y y pulgadas.
pattern <- "^[4-7]'\\d{1,2}\"$"El patrón ahora se está volviendo complejo, pero pueden mirarlo cuidadosamente y desglosarlo:
^= inicio de la cadena[4-7]= un dígito, ya sea 4, 5, 6 o 7'= símbolo de pies\\d{1,2}= uno o dos dígitos\"= símbolo de pulgadas$= final de la cadena
Probémoslo:
yes <- c("5'7\"", "6'2\"", "5'12\"")
no <- c("6,2\"", "6.2\"","I am 5'11\"", "3'2\"", "64")
str_detect(yes, pattern)
#> [1] TRUE TRUE TRUE
str_detect(no, pattern)
#> [1] FALSE FALSE FALSE FALSE FALSEPor ahora, estamos permitiendo que las pulgadas sean 12 o más grandes. Agregaremos una restricción más tarde ya que la expresión regular para esto es un poco más compleja de lo que estamos preparados para mostrar.
24.5.6 Espacio en blanco \s
Otro problema que tenemos son los espacios. Por ejemplo, nuestro patrón no corresponde con 5' 4" porque hay un espacio entre ' y 4, que nuestro patrón no permite. Los espacios son caracteres y R no los ignora:
identical("Hi", "Hi ")
#> [1] FALSEEn regex, \s representa el espacio en blanco. Para encontrar patrones como 5' 4, podemos cambiar nuestro patrón a:
pattern_2 <- "^[4-7]'\\s\\d{1,2}\"$"
str_subset(problems, pattern_2)
#> [1] "5' 4\"" "5' 11\"" "5' 7\""Sin embargo, esto no encontrará equivalencia con los patrones sin espacio. Entonces, ¿necesitamos más de un patrón regex? Resulta que también podemos usar un cuantificador para esto.
24.5.7 Cuantificadores: *, ?, +
Queremos que el patrón permita espacios pero que no los requiera. Incluso si hay varios espacios, como en este ejemplo 5' 4, todavía queremos que corresponda. Hay un cuantificador para exactamente este propósito. En regex, el carácter * significa cero o más instancias del carácter anterior. Aquí hay un ejemplo:
yes <- c("AB", "A1B", "A11B", "A111B", "A1111B")
no <- c("A2B", "A21B")
str_detect(yes, "A1*B")
#> [1] TRUE TRUE TRUE TRUE TRUE
str_detect(no, "A1*B")
#> [1] FALSE FALSEEl patrón anterior encuentra correspondencia con la primera cadena, que tiene cero 1s, y todas las cadenas con un o más 1. Entonces podemos mejorar nuestro patrón agregando el * después del carácter espacial \s.
Hay otros dos cuantificadores similares. Para ninguno o una vez, podemos usar ?, y para uno o más, podemos usar +. Pueden ver cómo difieren con este ejemplo:
data.frame(string = c("AB", "A1B", "A11B", "A111B", "A1111B"),
none_or_more = str_detect(yes, "A1*B"),
nore_or_once = str_detect(yes, "A1?B"),
once_or_more = str_detect(yes, "A1+B"))
#> string none_or_more nore_or_once once_or_more
#> 1 AB TRUE TRUE FALSE
#> 2 A1B TRUE TRUE TRUE
#> 3 A11B TRUE FALSE TRUE
#> 4 A111B TRUE FALSE TRUE
#> 5 A1111B TRUE FALSE TRUEUsaremos los tres en nuestro ejemplo de alturas reportadas, pero los veremos en una sección posterior.
24.5.8 Todo excepto
Para especificar patrones que no queremos detectar, podemos usar el símbolo ^ pero solo dentro de corchetes. Recuerden que fuera del corchete ^ significa el inicio de la cadena. Entonces, por ejemplo, si queremos detectar dígitos precedidos por algo que no sea una letra, podemos hacer lo siguiente:
pattern <- "[^a-zA-Z]\\d"
yes <- c(".3", "+2", "-0","*4")
no <- c("A3", "B2", "C0", "E4")
str_detect(yes, pattern)
#> [1] TRUE TRUE TRUE TRUE
str_detect(no, pattern)
#> [1] FALSE FALSE FALSE FALSEOtra forma de generar un patrón que busca todo excepto es usar la mayúscula del carácter especial. Por ejemplo \\D significa cualquier cosa que no sea un dígito, \\S significa cualquier cosa excepto un espacio y así sucesivamente.
24.5.9 Grupos
Los grupos son un elemento muy útil de la expresiones regulares que permiten la extracción de valores. Los grupos se definen usando paréntesis. No afectan las equivalencias de patrones. En cambio, permiten que las herramientas identifiquen partes específicas del patrón para que podamos extraerlas.
Queremos cambiar las alturas escritas como 5.6 a 5'6.
Para evitar cambiar patrones como 70.2, requeriremos que el primer dígito esté entre 4 y 7 [4-7] y que el segundo sea ninguno o uno o más dígitos \\d*. Comencemos definiendo un patrón sencillo que corresponda con lo siguiente:
pattern_without_groups <- "^[4-7],\\d*$"Queremos extraer los dígitos para poder formar la nueva versión usando un punto. Estos son nuestros dos grupos, por lo que los encapsulamos con paréntesis:
pattern_with_groups <- "^([4-7]),(\\d*)$"Encapsulamos la parte del patrón que corresponde con las partes que queremos conservar para su uso posterior. Agregar grupos no afecta la detección, ya que solo indica que queremos guardar lo que capturan los grupos. Tengan en cuenta que ambos patrones devuelven el mismo resultado cuando se usa str_detect:
yes <- c("5,9", "5,11", "6,", "6,1")
no <- c("5'9", ",", "2,8", "6.1.1")
s <- c(yes, no)
str_detect(s, pattern_without_groups)
#> [1] TRUE TRUE TRUE TRUE FALSE FALSE FALSE FALSE
str_detect(s, pattern_with_groups)
#> [1] TRUE TRUE TRUE TRUE FALSE FALSE FALSE FALSEUna vez que hayamos definido los grupos, podemos usar la función str_match para extraer los valores que definen estos grupos:
str_match(s, pattern_with_groups)
#> [,1] [,2] [,3]
#> [1,] "5,9" "5" "9"
#> [2,] "5,11" "5" "11"
#> [3,] "6," "6" ""
#> [4,] "6,1" "6" "1"
#> [5,] NA NA NA
#> [6,] NA NA NA
#> [7,] NA NA NA
#> [8,] NA NA NAObserven que las segunda y tercera columnas contienen pies y pulgadas, respectivamente. La primera columna es la parte de la cadena que corresponde con el patrón. Si no se encuentra una equivalencia, vemos un NA.
Ahora podemos entender la diferencia entre las funciones str_extract y str_match. str_extract extrae solo cadenas que corresponden con un patrón, no los valores definidos por grupos:
str_extract(s, pattern_with_groups)
#> [1] "5,9" "5,11" "6," "6,1" NA NA NA NA24.6 Buscar y reemplazar con expresiones regulares
Anteriormente definimos el objeto problems que contiene las cadenas que no parecen estar en pulgadas. Podemos ver que pocas de nuestras cadenas problemáticas corresponden con el patrón:
pattern <- "^[4-7]'\\d{1,2}\"$"
sum(str_detect(problems, pattern))
#> [1] 14Para ver por qué esto es así, mostramos algunos ejemplos que ilustran por qué no tenemos más equivalencias:
problems[c(2, 10, 11, 12, 15)] |> str_view(pattern) Un problema inicial que vemos de inmediato es que algunos estudiantes escribieron las palabras “feet” e “inches”. Podemos ver las entradas que hicieron esto con la función
Un problema inicial que vemos de inmediato es que algunos estudiantes escribieron las palabras “feet” e “inches”. Podemos ver las entradas que hicieron esto con la función str_subset:
str_subset(problems, "inches")
#> [1] "5 feet and 8.11 inches" "Five foot eight inches"
#> [3] "5 feet 7inches" "5ft 9 inches"
#> [5] "5 ft 9 inches" "5 feet 6 inches"También vemos que algunas entradas usan dos comillas simples '' en lugar de una comilla doble ".
str_subset(problems, "''")
#> [1] "5'9''" "5'10''" "5'10''" "5'3''" "5'7''" "5'6''"
#> [7] "5'7.5''" "5'7.5''" "5'10''" "5'11''" "5'10''" "5'5''"pattern <- "^[4-7]'\\d{1,2}$"Si hacemos este reemplazo antes de buscar equivalencias, obtendremos muchas más equivalencias:
problems |>
str_replace("feet|ft|foot", "'") |> # replace feet, ft, foot with '
str_replace("inches|in|''|\"", "") |> # remove all inches symbols
str_detect(pattern) |>
sum()
#> [1] 48Sin embargo, todavía nos faltan muchos casos.
Noten que en el código anterior, aprovechamos la consistencia de stringr y usamos el pipe.
Por ahora, mejoramos nuestro patrón agregando \\s* delante y después del símbolo de los pies ' para permitir espacio entre el símbolo de los pies y los números. Ahora encontraremos más equivalencias:
pattern <- "^[4-7]\\s*'\\s*\\d{1,2}$"
problems |>
str_replace("feet|ft|foot", "'") |> # replace feet, ft, foot with '
str_replace("inches|in|''|\"", "") |> # remove all inches symbols
str_detect(pattern) |>
sum()
#> [1] 53Podríamos estar tentados a evitar esto eliminando todos los espacios con str_replace_all. Sin embargo, al hacer una operación de este tipo, debemos asegurarnos de evitar efectos indeseados. En nuestros ejemplos de alturas autoreportadas, esto será un problema porque algunas entradas tienen la forma x y con espacio separando los pies de las pulgadas. Si eliminamos todos los espacios, cambiaríamos incorrectamente x y a xy lo que implica que un 6 1 se convertiría en 61 pulgadas en vez de 73 pulgadas.
El segundo grupo grande de entradas problemáticas tienen las formas x.y, x,y o x y. Queremos cambiar todo esto a nuestro formato común x'y. Pero no podemos simplemente buscar y reemplazar porque cambiaríamos valores como 70.5 a 70'5. Por lo tanto, nuestra estrategia será buscar un patrón muy específico que nos asegure que se devuelvan pies y pulgadas y luego, para aquellos que correspondan, se reemplazcan adecuadamente.
24.6.1 Buscar y reemplazar usando grupos
Otro aspecto útil de los grupos es que uno puede hacer referencia a los valores extraídos en una expresión regular cuando busca y reemplaza.
El carácter especial regex para el grupo en el lugar i es \\i. Entonces \\1 es el valor extraído del primer grupo, \\2 el valor del segundo y así sucesivamente. Como un ejemplo sencillo, noten que el siguiente código reemplazará una coma con un punto, pero solo si está entre dos dígitos:
pattern_with_groups <- "^([4-7]),(\\d*)$"
yes <- c("5,9", "5,11", "6,", "6,1")
no <- c("5'9", ",", "2,8", "6.1.1")
s <- c(yes, no)
str_replace(s, pattern_with_groups, "\\1'\\2")
#> [1] "5'9" "5'11" "6'" "6'1" "5'9" "," "2,8" "6.1.1"Podemos usar esto para convertir casos en nuestras alturas reportadas.
Ahora estamos listos para definir un patrón que nos ayudará a convertir todos los x.y, x,y y x y a nuestro formato preferido. Necesitamos adaptar pattern_with_groups para que sea un poco más flexible y capture todos los casos.
pattern_with_groups <-"^([4-7])\\s*[,\\.\\s+]\\s*(\\d*)$"Examinemos este patrón regex:
^= inicio de la cadena[4-7]= un dígito, ya sea 4, 5, 6 o 7\\s*= ninguno o más espacios en blanco[,\\.\\s+]= el símbolo de pies es,,.o al menos un espacio\\s*= ninguno o más espacios en blanco\\d*= ninguno o más dígitos$= final de la cadena
Podemos ver que parece estar funcionando:
str_subset(problems, pattern_with_groups) |> head()
#> [1] "5.3" "5.25" "5.5" "6.5" "5.8" "5.6"Ahora usamos esto para buscar y reemplazar:
str_subset(problems, pattern_with_groups) |>
str_replace(pattern_with_groups, "\\1'\\2") |> head()
#> [1] "5'3" "5'25" "5'5" "6'5" "5'8" "5'6"Lidiaremos con el desafío de “pulgadas más grandes que doce” más tarde.
24.7 Probar y mejorar
Desarrollar expresiones regulares correctas en el primer intento a menudo es difícil. Probar y mejorar es un enfoque común para encontrar el patrón de expresiones regulares que satisface todas las condiciones deseadas. En las secciones anteriores, hemos desarrollado una potente técnica de procesamiento de cadenas que puede ayudarnos a detectar muchas de las entradas problemáticas. Aquí probaremos nuestro enfoque, buscaremos más problemas y modificaremos nuestro enfoque para posibles mejoras. Escribamos una función que identifique todas las entradas que no se pueden convertir en números, recordando que algunas están en centímetros (nos encargaremos de arreglar esas más adelante):
not_inches_or_cm <- function(x, smallest = 50, tallest = 84){
inches <- suppressWarnings(as.numeric(x))
ind <- !is.na(inches) &
((inches >= smallest & inches <= tallest) |
(inches/2.54 >= smallest & inches/2.54 <= tallest))
!ind
}
problems <- reported_heights |>
filter(not_inches_or_cm(height)) |>
pull(height)
length(problems)
#> [1] 200Veamos qué proporción de estas se ajusta a nuestro patrón después de los pasos de procesamiento que desarrollamos anteriormente:
converted <- problems |>
str_replace("feet|foot|ft", "'") |> # convert feet symbols to '
str_replace("inches|in|''|\"", "") |> # remove inches symbols
str_replace("^([4-7])\\s*[,\\.\\s+]\\s*(\\d*)$", "\\1'\\2")# change format
pattern <- "^[4-7]\\s*'\\s*\\d{1,2}$"
index <- str_detect(converted, pattern)
mean(index)
#> [1] 0.615Observen cómo aprovechamos el pipe, una de las ventajas de usar stringr. Este último fragmento de código muestra que encontramos equivalencias en más de la mitad de las cadenas. Examinemos los casos restantes:
converted[!index]
#> [1] "6" "165cm" "511" "6"
#> [5] "2" ">9000" "5 ' and 8.11 " "11111"
#> [9] "6" "103.2" "19" "5"
#> [13] "300" "6'" "6" "Five ' eight "
#> [17] "7" "214" "6" "0.7"
#> [21] "6" "2'33" "612" "1,70"
#> [25] "87" "5'7.5" "5'7.5" "111"
#> [29] "5' 7.78" "12" "6" "yyy"
#> [33] "89" "34" "25" "6"
#> [37] "6" "22" "684" "6"
#> [41] "1" "1" "6*12" "87"
#> [45] "6" "1.6" "120" "120"
#> [49] "23" "1.7" "6" "5"
#> [53] "69" "5' 9 " "5 ' 9 " "6"
#> [57] "6" "86" "708,661" "5 ' 6 "
#> [61] "6" "649,606" "10000" "1"
#> [65] "728,346" "0" "6" "6"
#> [69] "6" "100" "88" "6"
#> [73] "170 cm" "7,283,465" "5" "5"
#> [77] "34"Surgen cuatro patrones claros:
- Muchos estudiantes que miden exactamente 5 o 6 pies no ingresaron ninguna pulgada, por ejemplo
6', y nuestro patrón requiere que se incluyan pulgadas. - Algunos estudiantes que miden exactamente 5 o 6 pies ingresaron solo ese número.
- Algunas de las pulgadas se ingresaron con puntos decimales. Por ejemplo
5'7.5''. Nuestro patrón solo busca dos dígitos. - Algunas entradas tienen espacios al final, por ejemplo
5 ' 9.
Aunque no es tan común, también vemos los siguientes problemas:
- Algunas entradas están en metros y algunas usan formatos europeos:
1.6,1,70. - Dos estudiantes añadieron
cm. - Un estudiante deletreó los números:
Five foot eight inches.
No está claro que valga la pena escribir código para manejar estos últimos tres casos, ya que son bastante raros. Sin embargo, algunos de ellos nos brindan la oportunidad de aprender algunas técnicas más de expresiones regulares, por lo que crearemos una solución.
Para el caso 1, si agregamos un '0 después del primer dígito, por ejemplo, convertir todo 6 a 6'0, entonces nuestro patrón previamente definido correspondará. Esto se puede hacer usando grupos:
yes <- c("5", "6", "5")
no <- c("5'", "5''", "5'4")
s <- c(yes, no)
str_replace(s, "^([4-7])$", "\\1'0")
#> [1] "5'0" "6'0" "5'0" "5'" "5''" "5'4"El patrón dice que tiene que comenzar (^) con un dígito entre 4 y 7 y terminar ahí ($). El paréntesis define el grupo que pasamos como \\1 para generar la cadena regex que usamos para el reemplazo.
Podemos adaptar este código ligeramente para manejar también el caso 2, que cubre la entrada 5'. Noten que 5' se deja intacto. Esto es porque el extra ' hace que el patrón no corresponda ya que tenemos que terminar con un 5 o 6. Queremos permitir que el 5 o 6 sea seguido por un signo de 0 o 1 pie. Entonces podemos simplemente agregar '{0,1} después de la ' para hacer esto. Sin embargo, podemos usar el carácter especial, ?, que significa ninguna o una vez. Como vimos anteriormente, esto es diferente a *, que significa ninguna o más. Ahora vemos que el cuarto caso también se convierte:
str_replace(s, "^([56])'?$", "\\1'0")
#> [1] "5'0" "6'0" "5'0" "5'0" "5''" "5'4"Aquí solo permitimos 5 y 6, pero no 4 y 7. Esto se debe a que medir 5 y 6 pies de altura es bastante común, por lo que suponemos que aquellos que escribieron 5 o 6 realmente querían decir 60 o 72 pulgadas. Sin embargo, medir 4 y 7 pies de altura es tan raro que, aunque aceptamos 84 como una entrada válida, suponemos que 7 fue ingresado por error.
Podemos usar cuantificadores para tratar el caso 3. Estas entradas no corresponden porque las pulgadas incluyen decimales y nuestro patrón no lo permite. Necesitamos permitir que el segundo grupo incluya decimales, no solo dígitos. Esto significa que debemos permitir cero o un punto ., entonces cero o más dígitos. Por eso, usaremos ambos ? y *. También recuerden que, para este caso particular, el punto debe escaparse ya que es un carácter especial (significa cualquier carácter excepto el salto de línea). Aquí hay un ejemplo sencillo de cómo podemos usar *.
Entonces podemos adaptar nuestro patrón, que actualmente es ^[4-7]\\s*'\\s*\\d{1,2}$ para permitir un decimal al final:
pattern <- "^[4-7]\\s*'\\s*(\\d+\\.?\\d*)$"Podemos tratar el caso 4, metros usando comas, de manera similar a cómo convertimos el x.y a x'y. Una diferencia es que requerimos que el primer dígito sea 1 o 2:
yes <- c("1,7", "1, 8", "2, " )
no <- c("5,8", "5,3,2", "1.7")
s <- c(yes, no)
str_replace(s, "^([12])\\s*,\\s*(\\d*)$", "\\1\\.\\2")
#> [1] "1.7" "1.8" "2." "5,8" "5,3,2" "1.7"Luego verificaremos si las entradas son metros utilizando sus valores numéricos. Regresaremos al estudio de caso después de presentar dos funciones ampliamente utilizadas en el procesamiento de cadenas que serán útiles al desarrollar nuestra solución final para las alturas autoreportadas.
24.8 Podar
En general, los espacios al principio o al final de la cadena no son informativos. Estos pueden ser particularmente engañosos porque a veces pueden ser difíciles de ver:
s <- "Hi "
cat(s)
#> Hi
identical(s, "Hi")
#> [1] FALSEEste es un problema lo suficientemente general como para que haya una función dedicada a eliminarlos: str_trim. El nombre viene de trim o podar en inglés.
str_trim("5 ' 9 ")
#> [1] "5 ' 9"24.9 Cómo cambiar de mayúsculas o minúsculas
Tengan en cuenta que regex distingue entre mayúsculas y minúsculas. A menudo queremos encontrar una equivalencia de palabra independientemente de si es mayúscula o minúscula. Un acercamiento para hacer esto es primero cambiar todo a minúsculas y luego continuar ignorando mayúsculas y minúsculas. Como ejemplo, noten que una de las entradas escribe números como palabras Five foot eight inches. Aunque no es eficiente, podríamos agregar 13 llamadas adicionales a str_replace para convertir zero a 0, one a 1, y así. Para no tener que escribir dos operaciones separadas para Zero y zero, One y one, etc., podemos usar la función str_to_lower para convertir todas las letras a minúsculas:
s <- c("Five feet eight inches")
str_to_lower(s)
#> [1] "five feet eight inches"Otras funciones relacionadas son str_to_upper y str_to_title. Ahora estamos listos para definir un procedimiento que convierta todos los casos problemáticos a pulgadas.
24.10 Estudio de caso 2: alturas autoreportadas (continuación)
Ahora ponemos todo lo que hemos aprendido en una función que toma un vector de cadena e intenta convertir todas las cadenas posibles a un formato. Escribimos una función que reúne lo que hemos hecho anteriormente:
convert_format <- function(s){
s |>
str_replace("feet|foot|ft", "'") |>
str_replace_all("inches|in|''|\"|cm|and", "") |>
str_replace("^([4-7])\\s*[,\\.\\s+]\\s*(\\d*)$", "\\1'\\2") |>
str_replace("^([56])'?$", "\\1'0") |>
str_replace("^([12])\\s*,\\s*(\\d*)$", "\\1\\.\\2") |>
str_trim()
}También podemos escribir una función que convierta palabras en números:
library(english)
words_to_numbers <- function(s){
s <- str_to_lower(s)
for(i in 0:11)
s <- str_replace_all(s, words(i), as.character(i))
s
}Tengan en cuenta que podemos realizar la operación anterior de manera más eficiente con la función recode, que estudiaremos en la Sección 24.13.
Ahora podemos ver qué entradas problemáticas permanecen:
converted <- problems |> words_to_numbers() |> convert_format()
remaining_problems <- converted[not_inches_or_cm(converted)]
pattern <- "^[4-7]\\s*'\\s*\\d+\\.?\\d*$"
index <- str_detect(remaining_problems, pattern)
remaining_problems[!index]
#> [1] "511" "2" ">9000" "11111" "103.2"
#> [6] "19" "300" "7" "214" "0.7"
#> [11] "2'33" "612" "1.70" "87" "111"
#> [16] "12" "yyy" "89" "34" "25"
#> [21] "22" "684" "1" "1" "6*12"
#> [26] "87" "1.6" "120" "120" "23"
#> [31] "1.7" "86" "708,661" "649,606" "10000"
#> [36] "1" "728,346" "0" "100" "88"
#> [41] "7,283,465" "34"Además de los casos ingresados como metros, que solucionaremos a continuación, todos parecen ser casos imposibles de resolver.
24.10.1 La función extract
La función extract de tidyverse es util para el procesamiento de cadenas que usaremos en nuestra solución final y, por ende, la presentamos aquí. En una sección anterior, construimos una expresión regular que nos permite identificar qué elementos de un vector de caracteres corresponden con el patrón de pies y pulgadas. Sin embargo, queremos hacer más. Queremos extraer y guardar los pies y los valores numéricos para poder convertirlos en pulgadas cuando sea apropiado.
Consideremos este ejemplo sencillo:
s <- c("5'10", "6'1")
tab <- data.frame(x = s)En la Sección 21.3, aprendimos sobre la función separate, que se puede utilizar para lograr nuestro objetivo actual:
tab |> separate(x, c("feet", "inches"), sep = "'")
#> feet inches
#> 1 5 10
#> 2 6 1La función extract del paquete tidyr nos permite usar grupos regex para extraer los valores deseados. Aquí está el equivalente al código anterior que usa separate, pero ahora usando extract:
library(tidyr)
tab |> extract(x, c("feet", "inches"), regex = "(\\d)'(\\d{1,2})")
#> feet inches
#> 1 5 10
#> 2 6 1Entonces, ¿por qué necesitamos la nueva función extract? Hemos visto cómo pequeños cambios pueden conducir a no tener equivalencias exactas. Los grupos en regex nos dan más flexibilidad. Por ejemplo, si definimos:
s <- c("5'10", "6'1\"","5'8inches")
tab <- data.frame(x = s)y solo queremos los números, separate no lo logra:
tab |> separate(x, c("feet","inches"), sep = "'", fill = "right")
#> feet inches
#> 1 5 10
#> 2 6 1"
#> 3 5 8inchesSin embargo, podemos usar extract. La regex aquí es un poco más complicada ya que tenemos que permitir ' con espacios y feet. Tampoco queremos el " incluido en el valor, por lo que no lo incluimos en el grupo:
tab |> extract(x, c("feet", "inches"), regex = "(\\d)'(\\d{1,2})")
#> feet inches
#> 1 5 10
#> 2 6 1
#> 3 5 824.10.2 Juntando todas la piezas
Ahora estamos listos para juntar todas las piezas y discutir nuestros datos de alturas reportados para tratar de recuperar todas las alturas posibles. El código es complejo, pero lo dividiremos en partes.
Comenzamos limpiando la columna height para que las alturas estén más cerca de un formato de pulgadas y pies. Agregamos una columna con las alturas originales para luego poder comparar.
Ahora estamos listos para wrangle nuestro set de datos de alturas reportadas:
pattern <- "^([4-7])\\s*'\\s*(\\d+\\.?\\d*)$"
smallest <- 50
tallest <- 84
new_heights <- reported_heights |>
mutate(original = height,
height = words_to_numbers(height) |> convert_format()) |>
extract(height, c("feet", "inches"), regex = pattern, remove = FALSE) |>
mutate_at(c("height", "feet", "inches"), as.numeric) |>
mutate(guess = 12 * feet + inches) |>
mutate(height = case_when(
is.na(height) ~ as.numeric(NA),
between(height, smallest, tallest) ~ height, #inches
between(height/2.54, smallest, tallest) ~ height/2.54, #cm
between(height*100/2.54, smallest, tallest) ~ height*100/2.54, #meters
TRUE ~ as.numeric(NA))) |>
mutate(height = ifelse(is.na(height) &
inches < 12 & between(guess, smallest, tallest),
guess, height)) |>
select(-guess)Podemos verificar todas las entradas que convertimos al escribir:
new_heights |>
filter(not_inches(original)) |>
select(original, height) |>
arrange(height) |>
View()Una observación final es que si miramos a los estudiantes más bajos de nuestro curso:
new_heights |> arrange(height) |> head(n=7)
#> time_stamp sex height feet inches original
#> 1 2017-07-04 01:30:25 Male 50.0 NA NA 50
#> 2 2017-09-07 10:40:35 Male 50.0 NA NA 50
#> 3 2014-09-02 15:18:30 Female 51.0 NA NA 51
#> 4 2016-06-05 14:07:20 Female 52.0 NA NA 52
#> 5 2016-06-05 14:07:38 Female 52.0 NA NA 52
#> 6 2014-09-23 03:39:56 Female 53.0 NA NA 53
#> 7 2015-01-07 08:57:29 Male 53.8 NA NA 53.77Vemos alturas de 51, 52 y 53. Estas alturas tan bajas son raras y es probable que los estudiantes realmente querían escribir 5'1, 5'2 y 5'3. Debido a que no estamos completamente seguros, los dejaremos como se reportaron. El objeto new_heights contiene nuestra solución final para este caso de estudio.
24.11 División de cadenas
Otra operación de wrangling de datos muy común es la división de cadenas. Para ilustrar cómo surge esto, comenzaremos con un ejemplo ilustrativo. Supongan que no tenemos la función read_csv o read.csv disponible. En cambio, tenemos que leer un archivo csv usando la función de base R readLines así:
filename <- system.file("extdata/murders.csv", package = "dslabs")
lines <- readLines(filename)Esta función lee los datos línea por línea para crear un vector de cadenas. En este caso, una cadena para cada fila en la hoja de cálculo. Las primeras seis líneas son:
lines |> head()
#> [1] "state,abb,region,population,total"
#> [2] "Alabama,AL,South,4779736,135"
#> [3] "Alaska,AK,West,710231,19"
#> [4] "Arizona,AZ,West,6392017,232"
#> [5] "Arkansas,AR,South,2915918,93"
#> [6] "California,CA,West,37253956,1257"Queremos extraer los valores que están separados por una coma para cada cadena en el vector. El comando str_split hace exactamente esto:
x <- str_split(lines, ",")
x |> head(2)
#> [[1]]
#> [1] "state" "abb" "region" "population" "total"
#>
#> [[2]]
#> [1] "Alabama" "AL" "South" "4779736" "135"Tengan en cuenta que la primera entrada representa el nombre de las columnas, por lo que podemos separarlas:
col_names <- x[[1]]
x <- x[-1]Para convertir nuestra lista en un data frame, podemos usar un atajo ofrecido por la función map en el paquete purrr. La función map aplica la misma función a cada elemento en una lista. Entonces, si queremos extraer la primera entrada de cada elemento en x, podemos escribir:
library(purrr)
map(x, function(y) y[1]) |> head(2)
#> [[1]]
#> [1] "Alabama"
#>
#> [[2]]
#> [1] "Alaska"Sin embargo, debido a que esta es una tarea tan común, purrr provee un atajo. Si el segundo argumento recibe un número entero en lugar de una función, supondrá que queremos esa entrada. Entonces, el código anterior se puede escribir de manera más eficiente así:
map(x, 1)Para forzar map a devolver un vector de caracteres en lugar de una lista, podemos usar map_chr. Asimismo, map_int devuelve enteros. Entonces, para crear nuestro data frame, podemos usar:
dat <- tibble(map_chr(x, 1),
map_chr(x, 2),
map_chr(x, 3),
map_chr(x, 4),
map_chr(x, 5)) |>
mutate_all(parse_guess) |>
setNames(col_names)
dat |> head()
#> # A tibble: 6 × 5
#> state abb region population total
#> <chr> <chr> <chr> <dbl> <dbl>
#> 1 Alabama AL South 4779736 135
#> 2 Alaska AK West 710231 19
#> 3 Arizona AZ West 6392017 232
#> 4 Arkansas AR South 2915918 93
#> 5 California CA West 37253956 1257
#> # … with 1 more rowSi exploran el paquete purrr, aprenderán que es posible realizar lo anterior con el siguiente código, que es más eficiente:
dat <- x |>
transpose() |>
map( ~ parse_guess(unlist(.))) |>
setNames(col_names) |>
as_tibble()Resulta que podemos evitar todo el trabajo que mostramos arriba después de la llamada a str_split. Específicamente, si sabemos que los datos que estamos extrayendo se pueden representar como una tabla, podemos usar el argumento simplify=TRUE y str_split devuelve una matriz en lugar de una lista:
x <- str_split(lines, ",", simplify = TRUE)
col_names <- x[1,]
x <- x[-1,]
colnames(x) <- col_names
x |> as_tibble() |>
mutate_all(parse_guess) |>
head(5)
#> # A tibble: 5 × 5
#> state abb region population total
#> <chr> <chr> <chr> <dbl> <dbl>
#> 1 Alabama AL South 4779736 135
#> 2 Alaska AK West 710231 19
#> 3 Arizona AZ West 6392017 232
#> 4 Arkansas AR South 2915918 93
#> 5 California CA West 37253956 125724.12 Estudio de caso 3: extracción de tablas de un PDF
Uno de los sets de datos de dslabs muestra las tasas de financiación científica por género en los Países Bajos:
library(dslabs)
data("research_funding_rates")
research_funding_rates |>
select("discipline", "success_rates_men", "success_rates_women")
#> discipline success_rates_men success_rates_women
#> 1 Chemical sciences 26.5 25.6
#> 2 Physical sciences 19.3 23.1
#> 3 Physics 26.9 22.2
#> 4 Humanities 14.3 19.3
#> 5 Technical sciences 15.9 21.0
#> 6 Interdisciplinary 11.4 21.8
#> 7 Earth/life sciences 24.4 14.3
#> 8 Social sciences 15.3 11.5
#> 9 Medical sciences 18.8 11.2Los datos provienen de un artículo publicado en Proceedings of the National Academy of Science (PNAS)100, una revista científica ampliamente leída. Sin embargo, los datos no se proveen en una hoja de cálculo, sino en una tabla en un documento PDF. Aquí hay una captura de pantalla de la tabla:
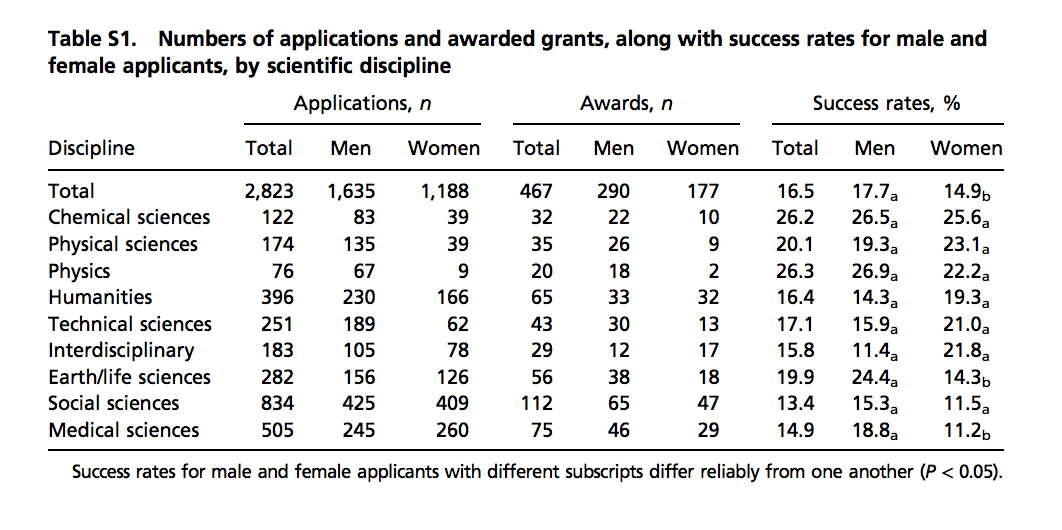
(Fuente: Romy van der Lee y Naomi Ellemers, PNAS 2015 112 (40) 12349-12353101.)
Podríamos extraer los números a mano, pero esto podría conducir a errores humanos. En cambio, podemos intentar cambiar los datos con R. Comenzamos descargando el documento PDF y luego importándolo a R:
library("pdftools")
temp_file <- tempfile()
url <- paste0("https://www.pnas.org/content/suppl/2015/09/16/",
"1510159112.DCSupplemental/pnas.201510159SI.pdf")
download.file(url, temp_file)
txt <- pdf_text(temp_file)
file.remove(temp_file)Si examinamos el objeto txt, notamos que es un vector de caracteres con una entrada para cada página. Entonces mantenemos la página que queremos:
raw_data_research_funding_rates <- txt[2]Los pasos anteriores se pueden omitir porque también incluimos estos datos sin procesar en el paquete dslabs:
data("raw_data_research_funding_rates")Al examinar el objeto raw_data_research_funding_rates, vemos que es una cadena larga y cada línea de la página, incluyendo las filas de la tabla, están separadas por el símbolo de nueva línea: \n. Por lo tanto, podemos crear una lista con las líneas del texto como elementos así:
tab <- str_split(raw_data_research_funding_rates, "\n")Debido a que comenzamos con solo un elemento en la cadena, terminamos con una lista con solo una entrada:
tab <- tab[[1]]Al examinar tab, vemos que la información para los nombres de columna son la tercera y cuarta entrada:
the_names_1 <- tab[3]
the_names_2 <- tab[4]La primera de estas filas se ve así:
#> Applications, n
#> Awards, n Success rates, %Queremos crear un vector con un nombre para cada columna. Podemos hacerlo usando algunas de las funciones que acabamos de aprender. Empecemos con the_names_1, que mostramos arriba. Queremos eliminar el espacio inicial y todo lo que sigue a la coma. Utilizamos regex para este último. Entonces podemos obtener los elementos dividiendo cadenas separadas por espacio. Queremos dividir solo cuando hay 2 o más espacios para no dividir Success rates. Para esto usamos la expresión regular \\s{2,}:
the_names_1 <- the_names_1 |>
str_trim() |>
str_replace_all(",\\s.", "") |>
str_split("\\s{2,}", simplify = TRUE)
the_names_1
#> [,1] [,2] [,3]
#> [1,] "Applications" "Awards" "Success rates"Ahora examinaremos the_names_2:
#> Discipline Total Men Women
#> n Total Men Women Total Men WomenAquí queremos podar el espacio inicial y buscar usar espacios para dividir las cadenas como lo hicimos para la primera línea:
the_names_2 <- the_names_2 |>
str_trim() |>
str_split("\\s+", simplify = TRUE)
the_names_2
#> [,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8]
#> [1,] "Discipline" "Total" "Men" "Women" "Total" "Men" "Women" "Total"
#> [,9] [,10]
#> [1,] "Men" "Women"Entonces podemos unirlos para generar un nombre para cada columna:
tmp_names <- str_c(rep(the_names_1, each = 3), the_names_2[-1], sep = "_")
the_names <- c(the_names_2[1], tmp_names) |>
str_to_lower() |>
str_replace_all("\\s", "_")
the_names
#> [1] "discipline" "applications_total" "applications_men"
#> [4] "applications_women" "awards_total" "awards_men"
#> [7] "awards_women" "success_rates_total" "success_rates_men"
#> [10] "success_rates_women"Ahora estamos listos para obtener los datos reales. Al examinar el objeto tab, notamos que la información está en las líneas 6 a 14. Podemos usar str_split de nuevo para lograr nuestro objetivo:
new_research_funding_rates <- tab[6:14] |>
str_trim() |>
str_split("\\s{2,}", simplify = TRUE) |>
data.frame() |>
setNames(the_names) |>
mutate_at(-1, parse_number)
new_research_funding_rates |> as_tibble()
#> # A tibble: 9 × 10
#> discipline applications_tot… applications_men applications_wo…
#> <chr> <dbl> <dbl> <dbl>
#> 1 Chemical sciences 122 83 39
#> 2 Physical sciences 174 135 39
#> 3 Physics 76 67 9
#> 4 Humanities 396 230 166
#> 5 Technical sciences 251 189 62
#> # … with 4 more rows, and 6 more variables: awards_total <dbl>,
#> # awards_men <dbl>, awards_women <dbl>, success_rates_total <dbl>,
#> # success_rates_men <dbl>, success_rates_women <dbl>Podemos ver que los objetos son idénticos:
identical(research_funding_rates, new_research_funding_rates)
#> [1] TRUE24.13 Recodificación
Otra operación común que involucra cadenas es recodificar los nombres de variables categóricas. Supongan que tienen nombres largos para sus niveles y los mostrarán en gráficos. Es posible que quieran utilizar versiones más cortas de estos nombres. Por ejemplo, en los vectores de caracteres con nombres de países, es posible que quieran cambiar “Estados Unidos de América” a “Estados Unidos”, “Reino Unido” a “RU” y así sucesivamente. Podemos hacer esto con case_when, aunque tidyverse ofrece una opción específicamente diseñada para esta tarea: la función recode.
Aquí hay un ejemplo que muestra cómo cambiar el nombre de los países con nombres largos:
library(dslabs)
data("gapminder")Imaginen que queremos mostrar series temporales de esperanza de vida por país para el Caribe:
gapminder |>
filter(region == "Caribbean") |>
ggplot(aes(year, life_expectancy, color = country)) +
geom_line()
El gráfico es lo que queremos, pero gran parte del espacio se desperdicia para acomodar algunos de los nombres largos de los países.
Tenemos cuatro países con nombres de más de 12 caracteres. Estos nombres aparecen una vez por cada año en el set de datos Gapminder. Una vez que elegimos los apodos, debemos cambiarlos todos de manera consistente. La función recode se puede utilizar para hacer esto:
gapminder |> filter(region=="Caribbean") |>
mutate(country = recode(country,
`Antigua and Barbuda` = "Barbuda",
`Dominican Republic` = "DR",
`St. Vincent and the Grenadines` = "St. Vincent",
`Trinidad and Tobago` = "Trinidad")) |>
ggplot(aes(year, life_expectancy, color = country)) +
geom_line()
Hay otras funciones similares en otros paquetes de R, como recode_factor y fct_recoder en el paquete forcats.
24.14 Ejercicios
1. Complete todas las lecciones y ejercicios en el tutorial interactivo en línea https://regexone.com/.
2. En el directorio extdata del paquete dslabs, encontrará un archivo PDF que contiene datos de mortalidad diaria para Puerto Rico del 1 de enero de 2015 al 31 de mayo de 2018. Puede encontrar el archivo así:
fn <- system.file("extdata", "RD-Mortality-Report_2015-18-180531.pdf",
package="dslabs")system2("open", args = fn)y en Windows, puede escribir:
system("cmd.exe", input = paste("start", fn))¿Cuál de las siguientes opciones describe mejor este archivo?
- Es una tabla. Extraer los datos será fácil.
- Es un informe escrito en prosa. Extraer los datos será imposible.
- Es un informe que combina gráficos y tablas. Extraer los datos parece posible.
- Muestra gráficos de los datos. Extraer los datos será difícil.
3. Vamos a crear un set de datos ordenado con cada fila representando una observación. Las variables en este set de datos serán año, mes, día y muertes. Comience instalando y cargando el paquete pdftools:
install.packages("pdftools")
library(pdftools)Ahora lean fn utilizando la función pdf_text y almacene los resultados en un objeto llamado txt. ¿Cuál de las siguientes opciones describe mejor lo que ve en txt?
- Una tabla con los datos de mortalidad.
- Una cadena de caracteres de longitud 12. Cada entrada representa el texto en cada página. Los datos de mortalidad están ahí en alguna parte.
- Una cadena de caracteres con una entrada que contiene toda la información en el archivo PDF.
- Un documento HTML.
4. Extraiga la novena página del archivo PDF del objeto txt. Luego, use str_split del paquete stringr para que cada línea esté en una entrada diferente. Llame a este vector de cadena s. Entonces mire el resultado y elija el que mejor describa lo que ve.
- Es una cadena vacía.
- Puedo ver la figura que se muestra en la página 1.
- Es una tabla tidy.
- ¡Puedo ver la tabla! Pero hay muchas otras cosas de las que debemos deshacernos.
5. ¿Qué tipo de objeto es s y cuántas entradas tiene?
6. Vemos que el output es una lista con un componente. Redefina s para que sea la primera entrada de la lista. ¿Qué tipo de objeto es s y cuántas entradas tiene?
7. Al inspeccionar la cadena que obtuvimos anteriormente, vemos un problema común: espacios en blanco antes y después de los otros caracteres. Podar es un primer paso común en el procesamiento de cadenas. Estos espacios adicionales eventualmente complicarán dividir las cadenas, por lo que comenzamos por eliminarlos. Aprendimos sobre el comando str_trim que elimina espacios al principio o al final de las cadenas. Use esta función para podar s.
8. Queremos extraer los números de las cadenas almacenadas en s. Sin embargo, hay muchos caracteres no numéricos que se interpondrán en el camino. Podemos eliminarlos, pero antes de hacerlo queremos preservar la cadena con el encabezado de la columna, que incluye la abreviatura del mes.
Utilice la función str_which para encontrar las filas con un encabezado. Guarde estos resultados en header_index. Sugerencia: encuentre la primera cadena que corresponda con el patrón 2015 utilizando la función str_which.
9. Ahora vamos a definir dos objetos: month almacenará el mes y header almacenará los nombres de columna. Identifique qué fila contiene el encabezado de la tabla. Guarde el contenido de la fila en un objeto llamado header. Luego, use str_split para ayudar a definir los dos objetos que necesitamos. Sugerencias: el separador aquí es uno o más espacios. Además, considere usar el argumento simplify.
10. Observe que hacia el final de la página verá una fila totals seguida de filas con otras estadísticas de resumen. Cree un objeto llamado tail_index con el índice de la entrada totals.
11. Debido a que nuestra página PDF incluye gráficos con números, algunas de nuestras filas tienen solo un número (desde el eje-y del gráfico). Utilice la función str_count para crear un objeto n con el número de números en cada fila. Sugerencia: escriba una expresión regular para un número como este \\d+.
12. Ahora estamos listos para eliminar entradas de filas que sabemos que no necesitamos. La entrada header_index y todo lo que viene antes se debe eliminar. Entradas para las cuales n es 1 también deben eliminarse. Finalmente, se debe eliminar la entrada tail_index y todo lo que viene después.
13. Ahora estamos listos para eliminar todas las entradas no numéricas. Haga esto usando regex y la función str_remove_all. Sugerencia: recuerde que en regex, usar la versión en mayúscula de un carácter especial generalmente significa lo contrario. Entonces \\D significa “no un dígito”. Recuerde que también quiere mantener espacios.
14. Para convertir las cadenas en una tabla, use la función str_split_fixed. Convierta s en una matriz de datos con solo la fecha y los datos con los números de muertes. Sugerencias: recuerde que el patrón que separa los valores es “uno o más espacios”. Utilice el argumento n de la función str_split_fixed para asegurarse de que la matriz de datos tenga las columnas necesarias para contener la información que queremos conservar y una columna más para capturar todo lo que no queremos. Finalmente, conserve sólo las columnas que necesita.
15. Ahora ya casi ha terminado. Agregue nombres de columna a la matriz, incluyendo uno llamado day. Además, agregue una columna con el mes. Llame al objeto resultante dat. Finalmente, asegúrese de que el día es un número entero, no un carácter. Sugerencia: use solo las primeras cinco columnas.
16. Ahora termine convirtiendo tab a formato tidy con la función pivot_longer.
17. Haga un diagrama de muertes versus día con color para indicar el año. Excluya 2018 ya que no tenemos datos para todo el año.
18. Ahora que hemos wrangled estos datos paso a paso, póngalos todos juntos en un programa de R, usando el pipe lo mas posible. Sugerencia: primero defina los índices, luego escriba una línea de código que realice todo el procesamiento de la cadena.
19. Avanzado: volvamos al ejemplo de la nómina MLB de la sección “Extracción de la web”. Use lo que aprendió en los capítulos de extracción de la web y procesamiento de cadenas para extraer la nómina de los Yankees de Nueva York, las Medias Rojas de Boston y los Atléticos de Oakland y grafíquelos como una función del tiempo.