Capítulo 26 Minería de textos
Con la excepción de las etiquetas utilizadas para representar datos categóricos, nos hemos enfocado en los datos numéricos. Pero en muchas aplicaciones, los datos comienzan como texto. Ejemplos bien conocidos son el filtrado de spam, la prevención del delito cibernético, la lucha contra el terrorismo y el análisis de sentimiento (también conocido como minería de opinión). En todos estos casos, los datos sin procesar se componen de texto de forma libre. Nuestra tarea es extraer información de estos datos. En esta sección, aprendemos cómo generar resúmenes numéricos útiles a partir de datos de texto a los que podemos aplicar algunas de las poderosas técnicas de visualización y análisis de datos que hemos aprendido.
26.1 Estudio de caso: tuits de Trump
Durante las elecciones presidenciales estadounidenses de 2016, el candidato Donald J. Trump usó su cuenta de Twitter como una manera de comunicarse con los posibles votantes. El 6 de agosto de 2016, Todd Vaziri tuiteó sobre Trump y declaró que “Cada tweet no hiperbólico es de iPhone (su personal). Cada tweet hiperbólico es de Android (de él)”102. El científico de datos David Robinson realizó un análisis para determinar si los datos respaldan esta afirmación103. Aquí, revisamos el análisis de David para aprender algunos de los conceptos básicos de la minería de textos. Para obtener más información sobre la minería de textos en R, recomendamos el libro Text Mining with R de Julia Silge y David Robinson104.
Utilizaremos los siguientes paquetes:
library(tidyverse)
library(lubridate)
library(scales)En general, podemos extraer datos directamente de Twitter usando el paquete rtweet. Sin embargo, en este caso, un grupo ya ha compilado datos para nosotros y los ha puesto a disposición en: https://www.thetrumparchive.com. Podemos obtener los datos de su API JSON usando un script como este:
url <- 'http://www.trumptwitterarchive.com/data/realdonaldtrump/%s.json'
trump_tweets <- map(2009:2017, ~sprintf(url, .x)) |>
map_df(jsonlite::fromJSON, simplifyDataFrame = TRUE) |>
filter(!is_retweet & !str_detect(text, '^"')) |>
mutate(created_at = parse_date_time(created_at,
orders = "a b! d! H!:M!:S! z!* Y!",
tz="EST"))Para facilitar el análisis, incluimos el resultado del código anterior en el paquete dslabs:
library(dslabs)
data("trump_tweets")Pueden ver el data frame con información sobre los tuits al escribir:
head(trump_tweets)con las siguientes variables incluidas:
names(trump_tweets)
#> [1] "source" "id_str"
#> [3] "text" "created_at"
#> [5] "retweet_count" "in_reply_to_user_id_str"
#> [7] "favorite_count" "is_retweet"El archivo de ayuda ?trump_tweets provee detalles sobre lo que representa cada variable. Los tuits están representados por el variable text:
trump_tweets$text[16413] |> str_wrap(width = options()$width) |> cat()
#> Great to be back in Iowa! #TBT with @JerryJrFalwell joining me in
#> Davenport- this past winter. #MAGA https://t.co/A5IF0QHnicy la variable source nos dice qué dispositivo se usó para componer y cargar cada tuit:
trump_tweets |> count(source) |> arrange(desc(n)) |> head(5)
#> source n
#> 1 Twitter Web Client 10718
#> 2 Twitter for Android 4652
#> 3 Twitter for iPhone 3962
#> 4 TweetDeck 468
#> 5 TwitLonger Beta 288Estamos interesados en lo que sucedió durante la campaña, por lo que para este análisis nos enfocaremos en lo que se tuiteó entre el día en que Trump anunció su campaña y el día de las elecciones. Definimos la siguiente tabla que contiene solo los tuits de ese período de tiempo. Tengan en cuenta que usamos extract para eliminar la parte Twitter for de source y filtrar los retweets.
campaign_tweets <- trump_tweets |>
extract(source, "source", "Twitter for (.*)") |>
filter(source %in% c("Android", "iPhone") &
created_at >= ymd("2015-06-17") &
created_at < ymd("2016-11-08")) |>
filter(!is_retweet) |>
arrange(created_at) |>
as_tibble()Ahora podemos usar la visualización de datos para explorar la posibilidad de que dos grupos diferentes hayan escrito los mensajes desde estos dispositivos. Para cada tuit, extraeremos la hora en que se publicó (hora de la costa este de EE.UU. o EST por sus siglas en inglés), y luego calcularemos la proporción de tuits tuiteada a cada hora para cada dispositivo:
campaign_tweets |>
mutate(hour = hour(with_tz(created_at, "EST"))) |>
count(source, hour) |>
group_by(source) |>
mutate(percent = n/ sum(n)) |>
ungroup() |>
ggplot(aes(hour, percent, color = source)) +
geom_line() +
geom_point() +
scale_y_continuous(labels = percent_format()) +
labs(x = "Hour of day (EST)", y = "% of tweets", color = "")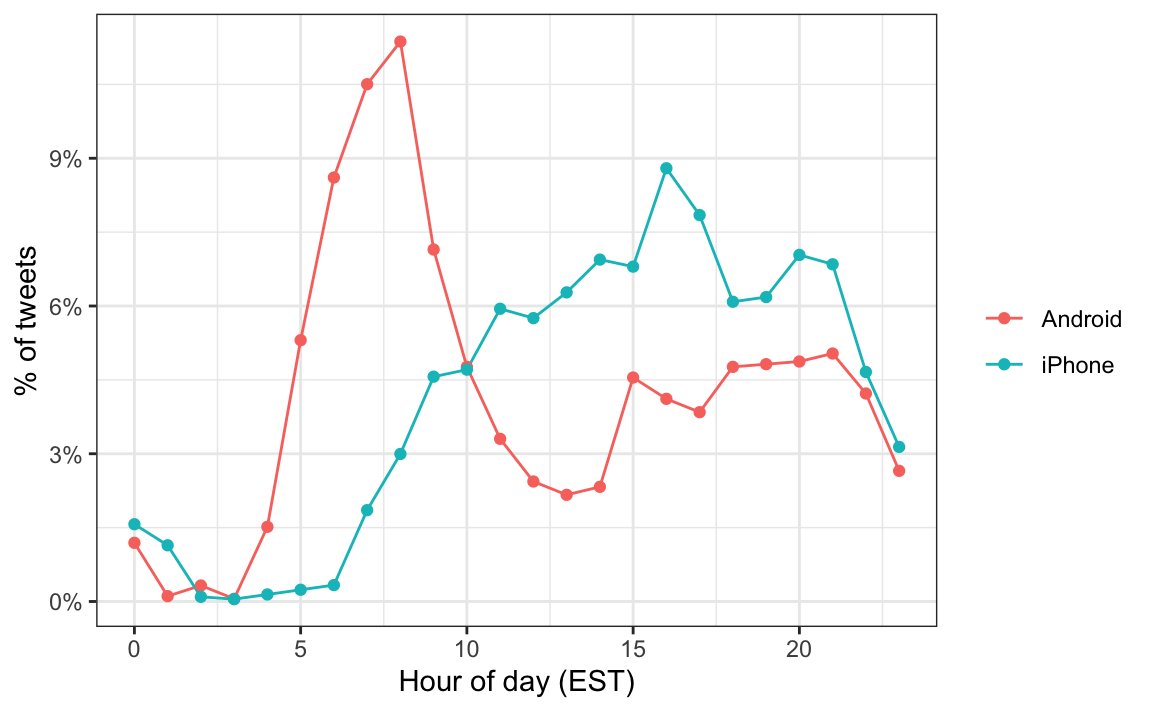
Notamos un gran pico para Android en las primeras horas de la mañana, entre las 6 y las 8 de la mañana. Parece haber una clara diferencia en estos patrones. Por lo tanto, suponemos que dos entidades diferentes están utilizando estos dos dispositivos.
Ahora estudiaremos cómo difieren los tuits cuando comparamos Android con iPhone. Para hacer esto, utilizaremos el paquete tidytext.
26.2 Texto como datos
El paquete tidytext nos ayuda a convertir texto de forma libre en una tabla ordenada. Tener los datos en este formato facilita enormemente la visualización de datos y el uso de técnicas estadísticas.
library(tidytext)La función principal necesaria para lograr esto es unnest_tokens. Un token se refiere a una unidad que consideramos como un punto de datos. Los tokens más comunes son las palabras, pero también pueden ser caracteres individuales, ngrams, oraciones, líneas o un patrón definido por una expresión regular. Las funciones tomarán un vector de cadenas y extraerán los tokens para que cada uno obtenga una fila en la nueva tabla. Aquí hay un ejemplo sencillo:
poem <- c("Roses are red,", "Violets are blue,",
"Sugar is sweet,", "And so are you.")
example <- tibble(line = c(1, 2, 3, 4),
text = poem)
example
#> # A tibble: 4 × 2
#> line text
#> <dbl> <chr>
#> 1 1 Roses are red,
#> 2 2 Violets are blue,
#> 3 3 Sugar is sweet,
#> 4 4 And so are you.
example |> unnest_tokens(word, text)
#> # A tibble: 13 × 2
#> line word
#> <dbl> <chr>
#> 1 1 roses
#> 2 1 are
#> 3 1 red
#> 4 2 violets
#> 5 2 are
#> # … with 8 more rowsAhora consideremos un ejemplo de los tuits. Miren el tuit número 3008 porque luego nos permitirá ilustrar un par de puntos:
i <- 3008
campaign_tweets$text[i] |> str_wrap(width = 65) |> cat()
#> Great to be back in Iowa! #TBT with @JerryJrFalwell joining me in
#> Davenport- this past winter. #MAGA https://t.co/A5IF0QHnic
campaign_tweets[i,] |>
unnest_tokens(word, text) |>
pull(word)
#> [1] "great" "to" "be" "back"
#> [5] "in" "iowa" "tbt" "with"
#> [9] "jerryjrfalwell" "joining" "me" "in"
#> [13] "davenport" "this" "past" "winter"
#> [17] "maga" "https" "t.co" "a5if0qhnic"Noten que la función intenta convertir tokens en palabras. Para hacer esto, sin embargo, elimina los caracteres que son importantes en el contexto de Twitter. Específicamente, la función elimina todos los # y @. Un token en el contexto de Twitter no es lo mismo que en el contexto del inglés hablado o escrito. Por esta razón, en lugar de usar el valor predeterminado, words, usamos el token tweets que incluye patrones que comienzan con @ y #:
campaign_tweets[i,] |>
unnest_tokens(word, text, token = "tweets") |>
pull(word)
#> [1] "great" "to"
#> [3] "be" "back"
#> [5] "in" "iowa"
#> [7] "#tbt" "with"
#> [9] "@jerryjrfalwell" "joining"
#> [11] "me" "in"
#> [13] "davenport" "this"
#> [15] "past" "winter"
#> [17] "#maga" "https://t.co/a5if0qhnic"Otro ajuste menor que queremos hacer es eliminar los enlaces a las imágenes:
links <- "https://t.co/[A-Za-z\\d]+|&"
campaign_tweets[i,] |>
mutate(text = str_replace_all(text, links, "")) |>
unnest_tokens(word, text, token = "tweets") |>
pull(word)
#> [1] "great" "to" "be"
#> [4] "back" "in" "iowa"
#> [7] "#tbt" "with" "@jerryjrfalwell"
#> [10] "joining" "me" "in"
#> [13] "davenport" "this" "past"
#> [16] "winter" "#maga"Ya estamos listos para extraer las palabras de todos nuestros tuits.
tweet_words <- campaign_tweets |>
mutate(text = str_replace_all(text, links, "")) |>
unnest_tokens(word, text, token = "tweets")Y ahora podemos responder a preguntas como “¿cuáles son las palabras más utilizadas?”:
tweet_words |>
count(word) |>
arrange(desc(n)) |>
slice(1:10)
#> # A tibble: 10 × 2
#> word n
#> <chr> <int>
#> 1 the 2329
#> 2 to 1410
#> 3 and 1239
#> 4 in 1185
#> 5 i 1143
#> # … with 5 more rowsNo es sorprendente que estas sean las palabras principales. Las palabras principales no son informativas. El paquete tidytext tiene una base de datos de estas palabras de uso común, denominadas palabras stop, en la minería de textos:
stop_words
#> # A tibble: 1,149 × 2
#> word lexicon
#> <chr> <chr>
#> 1 a SMART
#> 2 a's SMART
#> 3 able SMART
#> 4 about SMART
#> 5 above SMART
#> # … with 1,144 more rowsSi filtramos las filas que representan las palabras stop con filter(!word %in% stop_words$word):
tweet_words <- campaign_tweets |>
mutate(text = str_replace_all(text, links, "")) |>
unnest_tokens(word, text, token = "tweets") |>
filter(!word %in% stop_words$word )terminamos con un conjunto mucho más informativo de las 10 palabras más tuiteadas:
tweet_words |>
count(word) |>
top_n(10, n) |>
mutate(word = reorder(word, n)) |>
arrange(desc(n))
#> # A tibble: 10 × 2
#> word n
#> <fct> <int>
#> 1 #trump2016 414
#> 2 hillary 405
#> 3 people 303
#> 4 #makeamericagreatagain 294
#> 5 america 254
#> # … with 5 more rowsUna exploración de las palabras resultantes (que no se muestran aquí) revela un par de características no deseadas en nuestros tokens. Primero, algunos de nuestros tokens son solo números (años, por ejemplo). Queremos eliminarlos y podemos encontrarlos usando la expresión regular ^\d+$. Segundo, algunos de nuestros tokens provienen de una cita y comienzan con '. Queremos eliminar el ' cuando está al comienzo de una palabra, así que simplemente usamos str_replace. Agregamos estas dos líneas al código anterior para generar nuestra tabla final:
tweet_words <- campaign_tweets |>
mutate(text = str_replace_all(text, links, "")) |>
unnest_tokens(word, text, token = "tweets") |>
filter(!word %in% stop_words$word &
!str_detect(word, "^\\d+$")) |>
mutate(word = str_replace(word, "^'", ""))Ahora que tenemos las palabras en una tabla e información sobre qué dispositivo se usó para componer el tuit, podemos comenzar a explorar qué palabras son más comunes al comparar Android con iPhone.
Para cada palabra, queremos saber si es más probable que provenga de un tuit de Android o un tuit de iPhone. En la Sección 15.10, discutimos el riesgo relativo (odds ratio en inglés) como un resumen estadístico útil para cuantificar estas diferencias. Para cada dispositivo y una palabra dada, llamémosla y, calculamos el riesgo relativo. Aquí tendremos muchas proporciones que son 0, así que usamos la corrección 0.5 descrita en la Sección 15.10.
android_iphone_or <- tweet_words |>
count(word, source) |>
pivot_wider(names_from = "source", values_from = "n", values_fill = 0) |>
mutate(or = (Android + 0.5) / (sum(Android) - Android + 0.5) /
( (iPhone + 0.5) / (sum(iPhone) - iPhone + 0.5)))Aquí están los riesgos relativos más altos para Android:
android_iphone_or |> arrange(desc(or))
#> # A tibble: 5,914 × 4
#> word Android iPhone or
#> <chr> <int> <int> <dbl>
#> 1 poor 13 0 23.1
#> 2 poorly 12 0 21.4
#> 3 turnberry 11 0 19.7
#> 4 @cbsnews 10 0 18.0
#> 5 angry 10 0 18.0
#> # … with 5,909 more rowsy los más altos para iPhone:
android_iphone_or |> arrange(or)
#> # A tibble: 5,914 × 4
#> word Android iPhone or
#> <chr> <int> <int> <dbl>
#> 1 #makeamericagreatagain 0 294 0.00142
#> 2 #americafirst 0 71 0.00595
#> 3 #draintheswamp 0 63 0.00670
#> 4 #trump2016 3 411 0.00706
#> 5 #votetrump 0 56 0.00753
#> # … with 5,909 more rowsDado que varias de estas palabras son palabras generales de baja frecuencia, podemos imponer un filtro basado en la frecuencia total así:
android_iphone_or |> filter(Android+iPhone > 100) |>
arrange(desc(or))
#> # A tibble: 30 × 4
#> word Android iPhone or
#> <chr> <int> <int> <dbl>
#> 1 @cnn 90 17 4.44
#> 2 bad 104 26 3.39
#> 3 crooked 156 49 2.72
#> 4 interviewed 76 25 2.57
#> 5 media 76 25 2.57
#> # … with 25 more rows
android_iphone_or |> filter(Android+iPhone > 100) |>
arrange(or)
#> # A tibble: 30 × 4
#> word Android iPhone or
#> <chr> <int> <int> <dbl>
#> 1 #makeamericagreatagain 0 294 0.00142
#> 2 #trump2016 3 411 0.00706
#> 3 join 1 157 0.00805
#> 4 tomorrow 24 99 0.209
#> 5 vote 46 67 0.588
#> # … with 25 more rowsYa vemos un patrón en los tipos de palabras que se tuitean más desde un dispositivo que desde otro. Sin embargo, no estamos interesados en palabras específicas sino en el tono. La afirmación de Vaziri es que los tuits de Android son más hiperbólicos. Entonces, ¿cómo podemos verificar esto con datos? Hipérbole es un sentimiento difícil de extraer de las palabras, ya que se basa en la interpretación de frases. No obstante, las palabras pueden asociarse con sentimientos más básicos como la ira, el miedo, la alegría y la sorpresa. En la siguiente sección, demostramos el análisis básico de sentimientos.
26.3 Análisis de sentimiento
En el análisis de sentimiento, asignamos una palabra a uno o más “sentimientos”. Aunque este enfoque no siempre indentificará sentimientos que dependen del contexto, como el sarcasmo, cuando se realiza en grandes cantidades de palabras, los resúmenes pueden ofrecer información.
El primer paso en el análisis de sentimiento es asignar un sentimiento a cada palabra. Como demostramos, el paquete tidytext incluye varios mapas o léxicos. También usaremos el paquete textdata.
library(tidytext)
library(textdata)El léxico bing divide las palabras en sentimientos positive y negative. Podemos ver esto usando la función get_sentiments de tidytext:
get_sentiments("bing")El léxico AFINN asigna una puntuación entre -5 y 5, con -5 el más negativo y 5 el más positivo. Tengan en cuenta que este léxico debe descargarse la primera vez que llamen a la función get_sentiment:
get_sentiments("afinn")Los léxicos loughran y nrc ofrecen varios sentimientos diferentes. Noten que estos también deben descargarse la primera vez que los usen.
get_sentiments("loughran") |> count(sentiment)
#> # A tibble: 6 × 2
#> sentiment n
#> <chr> <int>
#> 1 constraining 184
#> 2 litigious 904
#> 3 negative 2355
#> 4 positive 354
#> 5 superfluous 56
#> # … with 1 more rowget_sentiments("nrc") |> count(sentiment)
#> # A tibble: 10 × 2
#> sentiment n
#> <chr> <int>
#> 1 anger 1247
#> 2 anticipation 839
#> 3 disgust 1058
#> 4 fear 1476
#> 5 joy 689
#> # … with 5 more rowsPara nuestro análisis, estamos interesados en explorar los diferentes sentimientos de cada tuit, por lo que utilizaremos el léxico nrc:
nrc <- get_sentiments("nrc") |>
select(word, sentiment)Podemos combinar las palabras y los sentimientos usando inner_join, que solo mantendrá palabras asociadas con un sentimiento. Aquí tenemos 10 palabras aleatorias extraídas de los tuits:
tweet_words |> inner_join(nrc, by = "word") |>
select(source, word, sentiment) |>
sample_n(5)
#> # A tibble: 5 × 3
#> source word sentiment
#> <chr> <chr> <chr>
#> 1 iPhone failing fear
#> 2 Android proud trust
#> 3 Android time anticipation
#> 4 iPhone horrible disgust
#> 5 Android failing angerAhora estamos listos para realizar un análisis cuantitativo comparando los sentimientos de los tuits publicados desde cada dispositivo. Podríamos realizar un análisis tuit por tuit, asignando un sentimiento a cada tuit. Sin embargo, esto sería un desafío ya que cada tuit tendrá varios sentimientos adjuntos, uno para cada palabra que aparezca en el léxico. Con fines ilustrativos, realizaremos un análisis mucho más sencillo: contaremos y compararemos las frecuencias de cada sentimiento que aparece en cada dispositivo.
sentiment_counts <- tweet_words |>
left_join(nrc, by = "word") |>
count(source, sentiment) |>
pivot_wider(names_from = "source", values_from = "n") |>
mutate(sentiment = replace_na(sentiment, replace = "none"))
sentiment_counts
#> # A tibble: 11 × 3
#> sentiment Android iPhone
#> <chr> <int> <int>
#> 1 anger 958 528
#> 2 anticipation 910 715
#> 3 disgust 638 322
#> 4 fear 795 486
#> 5 joy 688 535
#> # … with 6 more rowsPara cada sentimiento, podemos calcular las probabilidades de estar en el dispositivo: proporción de palabras con sentimiento versus proporción de palabras sin. Entonces calculamos el riesgo relativo comparando los dos dispositivos.
sentiment_counts |>
mutate(Android = Android/ (sum(Android) - Android) ,
iPhone = iPhone/ (sum(iPhone) - iPhone),
or = Android/iPhone) |>
arrange(desc(or))
#> # A tibble: 11 × 4
#> sentiment Android iPhone or
#> <chr> <dbl> <dbl> <dbl>
#> 1 disgust 0.0299 0.0186 1.61
#> 2 anger 0.0456 0.0309 1.47
#> 3 negative 0.0807 0.0556 1.45
#> 4 sadness 0.0424 0.0301 1.41
#> 5 fear 0.0375 0.0284 1.32
#> # … with 6 more rowsSí vemos algunas diferencias y el orden es particularmente interesante: ¡los tres sentimientos más grandes son el asco, la ira y lo negativo! ¿Pero estas diferencias son solo por casualidad? ¿Cómo se compara esto si solo estamos asignando sentimientos al azar? A fin de responder a esta pregunta, para cada sentimiento podemos calcular un riesgo relativo y un intervalo de confianza, como se definen en la Sección 15.10. Agregaremos los dos valores que necesitamos para formar una tabla de dos por dos y el riesgo relativo:
library(broom)
log_or <- sentiment_counts |>
mutate(log_or = log((Android/ (sum(Android) - Android))/
(iPhone/ (sum(iPhone) - iPhone))),
se = sqrt(1/Android + 1/(sum(Android) - Android) +
1/iPhone + 1/(sum(iPhone) - iPhone)),
conf.low = log_or - qnorm(0.975)*se,
conf.high = log_or + qnorm(0.975)*se) |>
arrange(desc(log_or))
log_or
#> # A tibble: 11 × 7
#> sentiment Android iPhone log_or se conf.low conf.high
#> <chr> <int> <int> <dbl> <dbl> <dbl> <dbl>
#> 1 disgust 638 322 0.474 0.0691 0.338 0.609
#> 2 anger 958 528 0.389 0.0552 0.281 0.497
#> 3 negative 1641 929 0.371 0.0424 0.288 0.454
#> 4 sadness 894 515 0.342 0.0563 0.232 0.452
#> 5 fear 795 486 0.280 0.0585 0.165 0.394
#> # … with 6 more rowsUna visualización gráfica muestra algunos sentimientos que están claramente sobrerrepresentados:
log_or |>
mutate(sentiment = reorder(sentiment, log_or)) |>
ggplot(aes(x = sentiment, ymin = conf.low, ymax = conf.high)) +
geom_errorbar() +
geom_point(aes(sentiment, log_or)) +
ylab("Log odds ratio for association between Android and sentiment") +
coord_flip()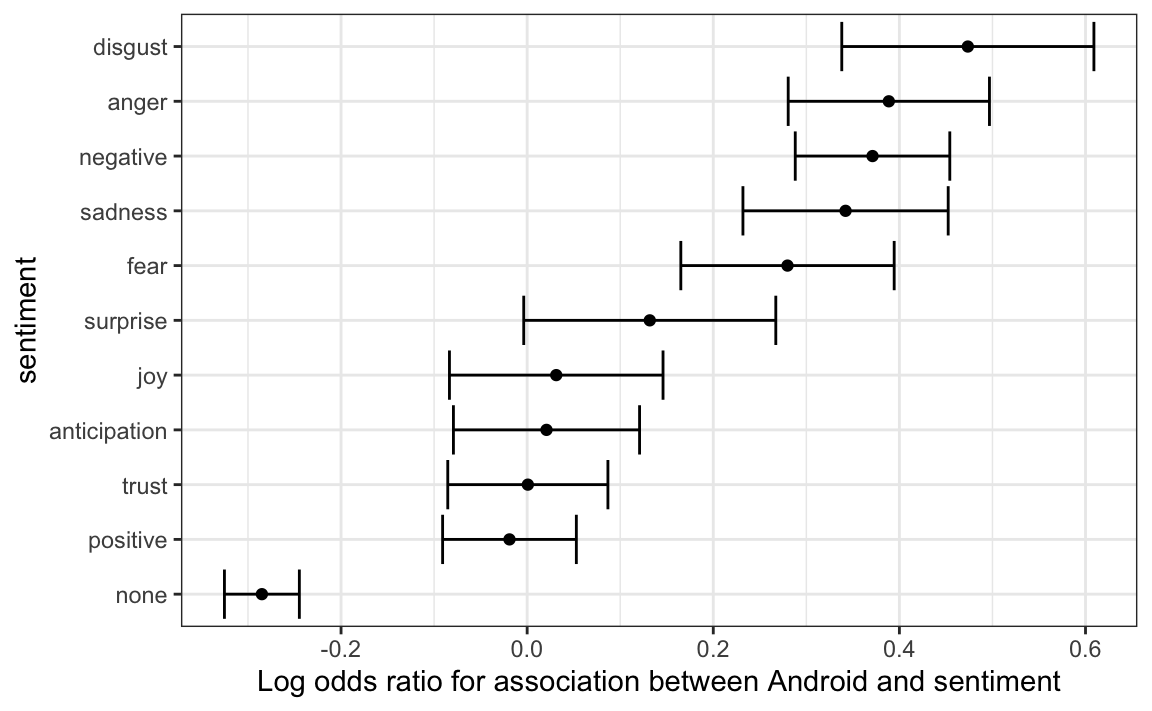
Vemos que el disgusto, la ira, los sentimientos negativos, la tristeza y el miedo están asociados con el Android de una manera que es difícil de explicar solo por casualidad. Las palabras no asociadas con un sentimiento estaban fuertemente asociadas con el iPhone, que está de acuerdo con la afirmación original sobre los tuits hiperbólicos.
Si estamos interesados en explorar qué palabras específicas están impulsando estas diferencias, podemos referirnos a nuestro objeto android_iphone_or:
android_iphone_or |> inner_join(nrc) |>
filter(sentiment == "disgust" & Android + iPhone > 10) |>
arrange(desc(or))
#> Joining, by = "word"
#> # A tibble: 20 × 5
#> word Android iPhone or sentiment
#> <chr> <int> <int> <dbl> <chr>
#> 1 mess 13 2 4.62 disgust
#> 2 finally 12 2 4.28 disgust
#> 3 unfair 12 2 4.28 disgust
#> 4 bad 104 26 3.39 disgust
#> 5 terrible 31 8 3.17 disgust
#> # … with 15 more rowsy hacer un gráfico:
android_iphone_or |> inner_join(nrc, by = "word") |>
mutate(sentiment = factor(sentiment, levels = log_or$sentiment)) |>
mutate(log_or = log(or)) |>
filter(Android + iPhone > 10 & abs(log_or)>1) |>
mutate(word = reorder(word, log_or)) |>
ggplot(aes(word, log_or, fill = log_or < 0)) +
facet_wrap(~sentiment, scales = "free_x", nrow = 2) +
geom_bar(stat="identity", show.legend = FALSE) +
theme(axis.text.x = element_text(angle = 90, hjust = 1))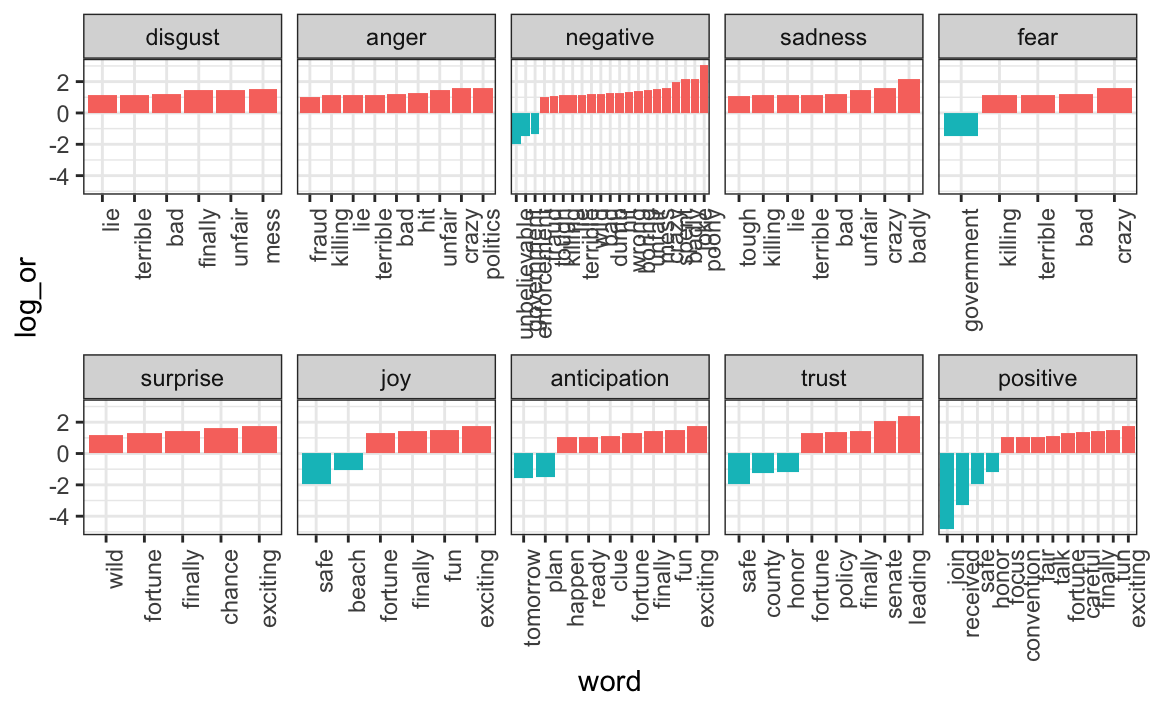
Este es solo un ejemplo sencillo de los muchos análisis que uno puede realizar con tidytext. Para obtener más información, nuevamente recomendamos el libro Tidy Text Mining105.
26.4 Ejercicios
Project Gutenberg es un archivo digital de libros de dominio público. El paquete gutenbergr de R facilita la importación de estos textos en R. Puede instalar y cargarlo escribiendo:
install.packages("gutenbergr")
library(gutenbergr)Los libros disponibles se pueden ver así:
gutenberg_metadata1. Utilice str_detect para encontrar la identificación de la novela Pride and Prejudice.
2. Observe que hay varias versiones. La función gutenberg_works()filtra esta tabla para eliminar réplicas e incluye solo trabajos en inglés. Lea el archivo de ayuda y use esta función para encontrar la identificación de Pride and Prejudice.
3. Utilice la función gutenberg_download para descargar el texto de Pride and Prejudice. Guárdelo en un objeto llamado book.
4. Use el paquete tidytext para crear una tabla ordenada con todas las palabras en el texto. Guarde la tabla en un objeto llamado words.
5. Más adelante haremos un gráfico de sentimiento versus ubicación en el libro. Para esto, será útil agregar una columna a la tabla con el número de palabra.
6. Elimine las palabras stop y los números del objeto words. Sugerencia: use anti_join.
7. Ahora use el léxico AFINN para asignar un valor de sentimiento a cada palabra.
8. Haga un gráfico de puntuación de sentimiento versus ubicación en el libro y agregue un suavizador.
9. Suponga que hay 300 palabras por página. Convierta las ubicaciones en páginas y luego calcule el sentimiento promedio en cada página. Grafique esa puntuación promedio por página. Agregue un suavizador que pase por los datos.