Capítulo 22 Unir tablas
Es posible que la información que necesitamos para un análisis no esté en solo en una tabla. Por ejemplo, cuando pronosticamos elecciones usamos la función left_join para combinar la información de dos tablas. Aquí usamos un ejemplo más sencillo para ilustrar el desafío general de combinar tablas.
Supongan que queremos explorar la relación entre el tamaño de la población de los estados de EE. UU. y los votos electorales. Tenemos el tamaño de la población en esta tabla:
library(tidyverse)
library(dslabs)
data(murders)
head(murders)
#> state abb region population total
#> 1 Alabama AL South 4779736 135
#> 2 Alaska AK West 710231 19
#> 3 Arizona AZ West 6392017 232
#> 4 Arkansas AR South 2915918 93
#> 5 California CA West 37253956 1257
#> 6 Colorado CO West 5029196 65y los votos electorales en esta:
data(polls_us_election_2016)
head(results_us_election_2016)
#> state electoral_votes clinton trump others
#> 1 California 55 61.7 31.6 6.7
#> 2 Texas 38 43.2 52.2 4.5
#> 3 Florida 29 47.8 49.0 3.2
#> 4 New York 29 59.0 36.5 4.5
#> 5 Illinois 20 55.8 38.8 5.4
#> 6 Pennsylvania 20 47.9 48.6 3.6Simplemente concatenar estas dos tablas no funcionará ya que el orden de los estados no es el mismo.
identical(results_us_election_2016$state, murders$state)
#> [1] FALSELas funciones que usamos para unir (join en inglés), descritas a continuación, están diseñadas para manejar este desafío.
22.1 Funciones para unir
Las funciones para unir del paquete dplyr aseguran que las tablas se combinen de tal forma que las filas equivalentes estén juntas. Si conocen SQL, verán que el acercamiento y la sintaxis son muy similares. La idea general es que uno necesita identificar una o más columnas que servirán para emparejar las dos tablas. Entonces se devuelve una nueva tabla con la información combinada. Observen lo que sucede si unimos las dos tablas anteriores por estado usando left_join (eliminaremos la columna others y renombraremos electoral_votes para que las tablas quepen en la página):
tab <- left_join(murders, results_us_election_2016, by = "state") |>
select(-others) |> rename(ev = electoral_votes)
head(tab)
#> state abb region population total ev clinton trump
#> 1 Alabama AL South 4779736 135 9 34.4 62.1
#> 2 Alaska AK West 710231 19 3 36.6 51.3
#> 3 Arizona AZ West 6392017 232 11 45.1 48.7
#> 4 Arkansas AR South 2915918 93 6 33.7 60.6
#> 5 California CA West 37253956 1257 55 61.7 31.6
#> 6 Colorado CO West 5029196 65 9 48.2 43.3Los datos se han unido exitosamente y ahora podemos, por ejemplo, hacer un diagrama para explorar la relación:
library(ggrepel)
tab |> ggplot(aes(population/10^6, ev, label = abb)) +
geom_point() +
geom_text_repel() +
scale_x_continuous(trans = "log2") +
scale_y_continuous(trans = "log2") +
geom_smooth(method = "lm", se = FALSE)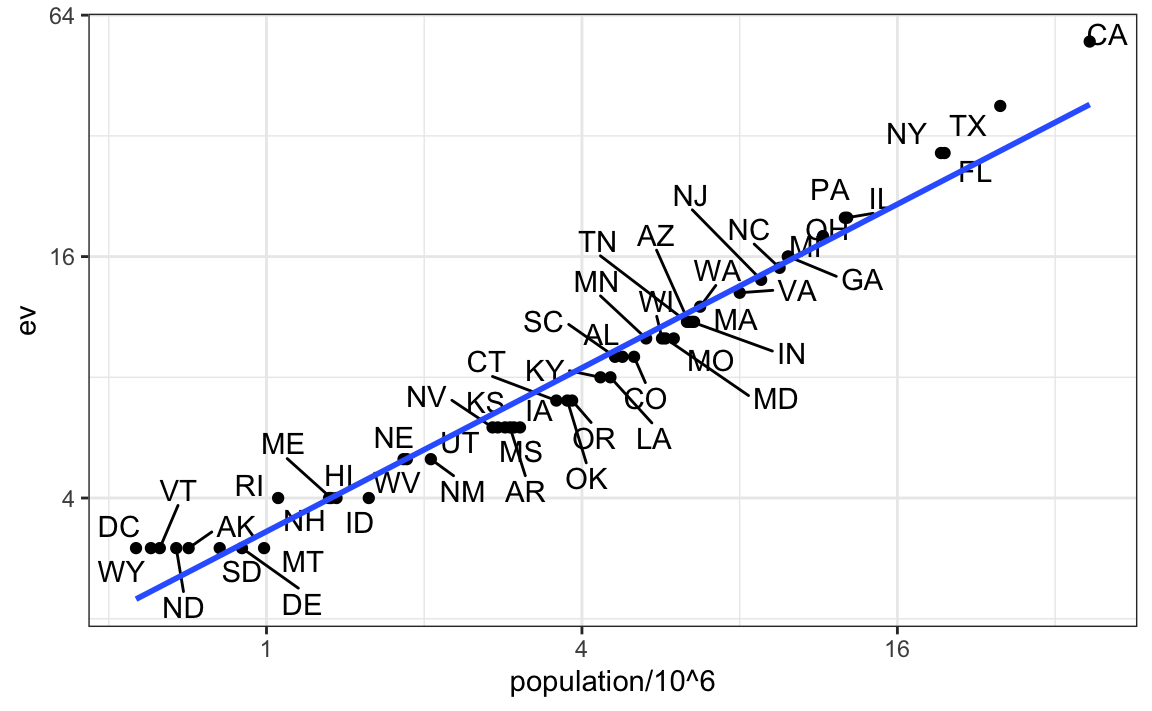
Vemos que la relación es casi lineal con aproximadamente dos votos electorales para cada millón de personas, pero con estados muy pequeños obteniendo proporciones más altas.
En la práctica, no siempre ocurre que cada fila de una tabla tiene una fila correspondiente en la otra. Por esta razón, tenemos varias versiones de join. Para ilustrar este reto, tomaremos subconjuntos de las tablas anteriores. Creamos las tablas tab1 y tab2 para que tengan algunos estados en común pero no todos:
tab_1 <- slice(murders, 1:6) |> select(state, population)
tab_1
#> state population
#> 1 Alabama 4779736
#> 2 Alaska 710231
#> 3 Arizona 6392017
#> 4 Arkansas 2915918
#> 5 California 37253956
#> 6 Colorado 5029196
tab_2 <- results_us_election_2016 |>
filter(state%in%c("Alabama", "Alaska", "Arizona",
"California", "Connecticut", "Delaware")) |>
select(state, electoral_votes) |> rename(ev = electoral_votes)
tab_2
#> state ev
#> 1 California 55
#> 2 Arizona 11
#> 3 Alabama 9
#> 4 Connecticut 7
#> 5 Alaska 3
#> 6 Delaware 3Utilizaremos estas dos tablas como ejemplos en las siguientes secciones.
22.1.1 Left join
Supongan que queremos una tabla como tab_1, pero agregando votos electorales a cualquier estado que tengamos disponible. Para esto, usamos left_join con tab_1 como el primer argumento. Especificamos qué columna usar para que coincida con el argumento by.
left_join(tab_1, tab_2, by = "state")
#> state population ev
#> 1 Alabama 4779736 9
#> 2 Alaska 710231 3
#> 3 Arizona 6392017 11
#> 4 Arkansas 2915918 NA
#> 5 California 37253956 55
#> 6 Colorado 5029196 NATengan en cuenta que NAs se agregan a los dos estados que no aparecen en tab_2. Además, observen que esta función, así como todas las otras joins, pueden recibir los primeros argumentos a través del pipe:
tab_1 |> left_join(tab_2, by = "state")22.1.2 Right join
Si en lugar de una tabla con las mismas filas que la primera tabla, queremos una con las mismas filas que la segunda tabla, podemos usar right_join:
tab_1 |> right_join(tab_2, by = "state")
#> state population ev
#> 1 Alabama 4779736 9
#> 2 Alaska 710231 3
#> 3 Arizona 6392017 11
#> 4 California 37253956 55
#> 5 Connecticut NA 7
#> 6 Delaware NA 3Ahora los NAs están en la columna de tab_1.
22.1.3 Inner join
Si queremos mantener solo las filas que tienen información en ambas tablas, usamos inner_join. Pueden pensar en esto como una intersección:
inner_join(tab_1, tab_2, by = "state")
#> state population ev
#> 1 Alabama 4779736 9
#> 2 Alaska 710231 3
#> 3 Arizona 6392017 11
#> 4 California 37253956 5522.1.4 Full join
Si queremos mantener todas las filas y llenar las partes faltantes con NAs, podemos usar full_join. Pueden pensar en esto como una unión:
full_join(tab_1, tab_2, by = "state")
#> state population ev
#> 1 Alabama 4779736 9
#> 2 Alaska 710231 3
#> 3 Arizona 6392017 11
#> 4 Arkansas 2915918 NA
#> 5 California 37253956 55
#> 6 Colorado 5029196 NA
#> 7 Connecticut NA 7
#> 8 Delaware NA 322.1.5 Semi join
La función semi_join nos permite mantener la parte de la primera tabla para la cual tenemos información en la segunda. No agrega las columnas de la segunda:
semi_join(tab_1, tab_2, by = "state")
#> state population
#> 1 Alabama 4779736
#> 2 Alaska 710231
#> 3 Arizona 6392017
#> 4 California 3725395622.1.6 Anti join
La función anti_join es la opuesta de semi_join. Mantiene los elementos de la primera tabla para los que no hay información en la segunda:
anti_join(tab_1, tab_2, by = "state")
#> state population
#> 1 Arkansas 2915918
#> 2 Colorado 5029196El siguiente diagrama resume las funciones join:
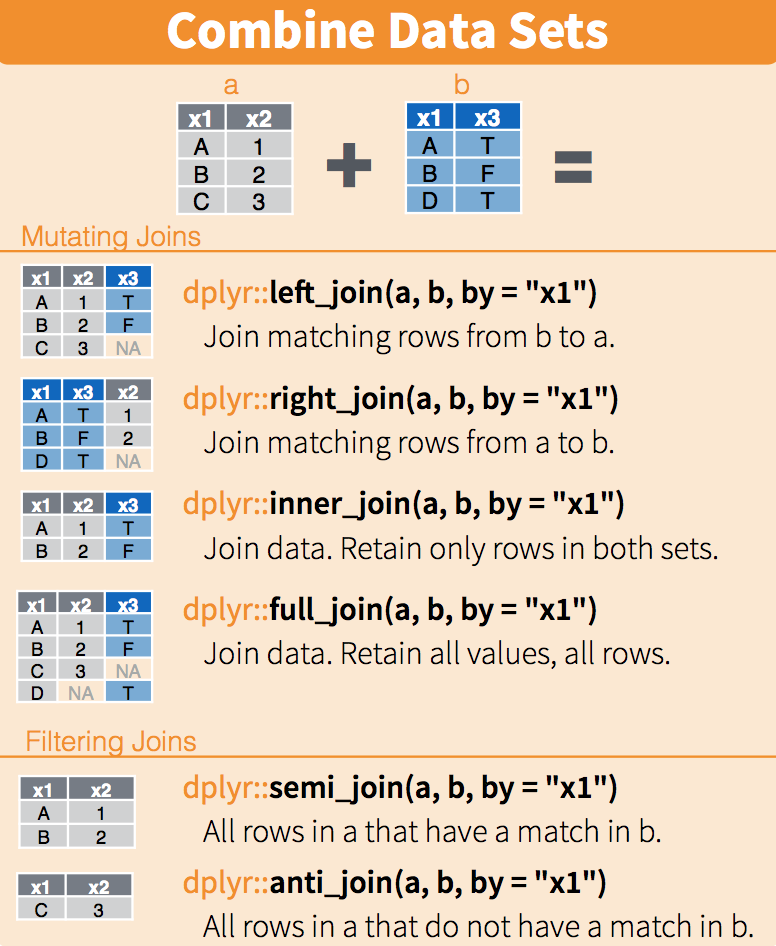 (Imagen cortesía de RStudio86. Licencia CC-BY-4.087. Recortada del original.)
(Imagen cortesía de RStudio86. Licencia CC-BY-4.087. Recortada del original.)
22.2 Binding
Aunque todavía no lo hemos usado en este libro, otra forma común en la que se combinan los sets de datos es pegándolos (binding en inglés). A diferencia de las funciones join, las funciones binding no intentan coincidir con una variable, sino que simplemente combinan sets de datos. Si los sets de datos no coinciden con las dimensiones apropiadas, se obtiene un error.
22.2.1 Pegando columnas
La función bind_cols de dplyr pega dos objetos convirtiéndolos en columnas en un tibble. Por ejemplo, queremos crear rápidamente un data frame que consiste de números que podemos usar.
bind_cols(a = 1:3, b = 4:6)
#> # A tibble: 3 × 2
#> a b
#> <int> <int>
#> 1 1 4
#> 2 2 5
#> 3 3 6Esta función requiere que asignemos nombres a las columnas. Aquí elegimos a y b.
Noten que hay una función de R, cbind, con exactamente la misma funcionalidad. Una diferencia importante es que cbind puede crear diferentes tipos de objetos, mientras bind_cols siempre produce un data frame.
bind_cols también puede pegar dos data frames diferentes. Por ejemplo, aquí separamos el data frame tab en tres data frames y luego volvemos a pegarlos:
tab_1 <- tab[, 1:3]
tab_2 <- tab[, 4:6]
tab_3 <- tab[, 7:8]
new_tab <- bind_cols(tab_1, tab_2, tab_3)
head(new_tab)
#> state abb region population total ev clinton trump
#> 1 Alabama AL South 4779736 135 9 34.4 62.1
#> 2 Alaska AK West 710231 19 3 36.6 51.3
#> 3 Arizona AZ West 6392017 232 11 45.1 48.7
#> 4 Arkansas AR South 2915918 93 6 33.7 60.6
#> 5 California CA West 37253956 1257 55 61.7 31.6
#> 6 Colorado CO West 5029196 65 9 48.2 43.322.2.2 Pegando filas
La función bind_rows es similar a bind_cols, pero pega filas en lugar de columnas:
tab_1 <- tab[1:2,]
tab_2 <- tab[3:4,]
bind_rows(tab_1, tab_2)
#> state abb region population total ev clinton trump
#> 1 Alabama AL South 4779736 135 9 34.4 62.1
#> 2 Alaska AK West 710231 19 3 36.6 51.3
#> 3 Arizona AZ West 6392017 232 11 45.1 48.7
#> 4 Arkansas AR South 2915918 93 6 33.7 60.6Esto se basa en la función rbind de R.
22.3 Operadores de sets
Otro conjunto de comandos útiles para combinar sets de datos son los operadores de sets. Cuando se aplican a los vectores, estos se comportan como lo sugieren sus nombres. Ejemplos son intersect, union, setdiff y setequal. Sin embargo, si se carga el tidyverse, o más específicamente dplyr, estas funciones se pueden usar en data frames en lugar de solo en vectores.
22.3.1 Intersecar
Pueden tomar intersecciones de vectores de cualquier tipo, como numéricos:
intersect(1:10, 6:15)
#> [1] 6 7 8 9 10o caracteres:
intersect(c("a","b","c"), c("b","c","d"))
#> [1] "b" "c"El paquete dplyr incluye una función intersect que se puede aplicar a tablas con los mismos nombres de columna. Esta función devuelve las filas en común entre dos tablas. Para asegurarnos de que usamos la versión de dplyr de intersect en lugar de la versión del paquete base, podemos usar dplyr::intersect así:
tab_1 <- tab[1:5,]
tab_2 <- tab[3:7,]
dplyr::intersect(tab_1, tab_2)
#> state abb region population total ev clinton trump
#> 1 Arizona AZ West 6392017 232 11 45.1 48.7
#> 2 Arkansas AR South 2915918 93 6 33.7 60.6
#> 3 California CA West 37253956 1257 55 61.7 31.622.3.2 Unión
Del mismo modo, union toma la unión de vectores. Por ejemplo:
union(1:10, 6:15)
#> [1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
union(c("a","b","c"), c("b","c","d"))
#> [1] "a" "b" "c" "d"El paquete dplyr incluye una versión de union que combina todas las filas de dos tablas con los mismos nombres de columna.
tab_1 <- tab[1:5,]
tab_2 <- tab[3:7,]
dplyr::union(tab_1, tab_2)
#> state abb region population total ev clinton trump
#> 1 Alabama AL South 4779736 135 9 34.4 62.1
#> 2 Alaska AK West 710231 19 3 36.6 51.3
#> 3 Arizona AZ West 6392017 232 11 45.1 48.7
#> 4 Arkansas AR South 2915918 93 6 33.7 60.6
#> 5 California CA West 37253956 1257 55 61.7 31.6
#> 6 Colorado CO West 5029196 65 9 48.2 43.3
#> 7 Connecticut CT Northeast 3574097 97 7 54.6 40.922.3.3 setdiff
La diferencia establecida entre un primer y un segundo argumento se puede obtener con setdiff. A diferencia de intersect y union, esta función no es simétrica:
setdiff(1:10, 6:15)
#> [1] 1 2 3 4 5
setdiff(6:15, 1:10)
#> [1] 11 12 13 14 15Al igual que con las funciones que se muestran arriba, dplyr tiene una versión para data frames:
tab_1 <- tab[1:5,]
tab_2 <- tab[3:7,]
dplyr::setdiff(tab_1, tab_2)
#> state abb region population total ev clinton trump
#> 1 Alabama AL South 4779736 135 9 34.4 62.1
#> 2 Alaska AK West 710231 19 3 36.6 51.322.3.4 setequal
Finalmente, la función setequal nos dice si dos sets son iguales, independientemente del orden. Noten que:
setequal(1:5, 1:6)
#> [1] FALSEpero:
setequal(1:5, 5:1)
#> [1] TRUECuando se aplica a data frames que no son iguales, independientemente del orden, la versión dplyr ofrece un mensaje útil que nos permite saber cómo los sets son diferentes:
dplyr::setequal(tab_1, tab_2)
#> [1] FALSE22.4 Ejercicios
1. Instale y cargue la biblioteca Lahman. Esta base de datos incluye datos relacionados a equipos de béisbol. Incluya estadísticas sobre cómo se desempeñaron los jugadores ofensiva y defensivamente durante varios años. También incluye información personal sobre los jugadores.
El data frame Batting contiene las estadísticas ofensivas de todos los jugadores durante muchos años. Puede ver, por ejemplo, los 10 mejores bateadores ejecutando este código:
library(Lahman)
top <- Batting |>
filter(yearID == 2016) |>
arrange(desc(HR)) |>
slice(1:10)
top |> as_tibble()¿Pero quiénes son estos jugadores? Vemos una identificación, pero no los nombres. Los nombres de los jugadores están en esta tabla:
Master |> as_tibble()Podemos ver los nombres de las columnas nameFirst y nameLast. Utilice la función left_join para crear una tabla de los mejores bateadores de cuadrangulares. La tabla debe tener playerID, nombre, apellido y número de cuandrangulares (HR). Reescriba el objeto top con esta nueva tabla.
2. Ahora use el data frame Salaries para añadir el salario de cada jugador a la tabla que creó en el ejercicio 1. Note que los salarios son diferentes cada año, así que asegúrese de filtrar para el año 2016, luego use right_join. Esta vez muestre el nombre, apellido, equipo, HR y salario.
3. En un ejercicio anterior, creamos una versión ordenada del set de datos co2:
co2_wide <- data.frame(matrix(co2, ncol = 12, byrow = TRUE)) |>
setNames(1:12) |>
mutate(year = 1959:1997) |>
pivot_longer(-year, names_to = "month", values_to = "co2") |>
mutate(month = as.numeric(month))Queremos ver si la tendencia mensual está cambiando, por lo que eliminaremos los efectos del año y luego graficaremos los resultados. Primero, calcularemos los promedios del año. Utilice group_by y summarize para calcular el CO2 promedio de cada año. Guárdelo en un objeto llamado yearly_avg.
4. Ahora use la función left_join para agregar el promedio anual al set de datos co2_wide. Entonces calcule los residuos: medida de CO2 observada - promedio anual.
5. Haga un diagrama de las tendencias estacionales por año, pero solo después de eliminar el efecto del año.