Capítulo 23 Extracción de la web
Los datos que necesitamos para responder a una pregunta no siempre están en una hoja de cálculo lista para leer. Por ejemplo, el set de datos sobre asesinatos de EE.UU. que utilizamos en el Capítulo “Lo básico de R” proviene originalmente de esta página de Wikipedia:
url <- paste0("https://en.wikipedia.org/w/index.php?title=",
"Gun_violence_in_the_United_States_by_state",
"&direction=prev&oldid=810166167")Pueden ver la tabla de datos en la página web:
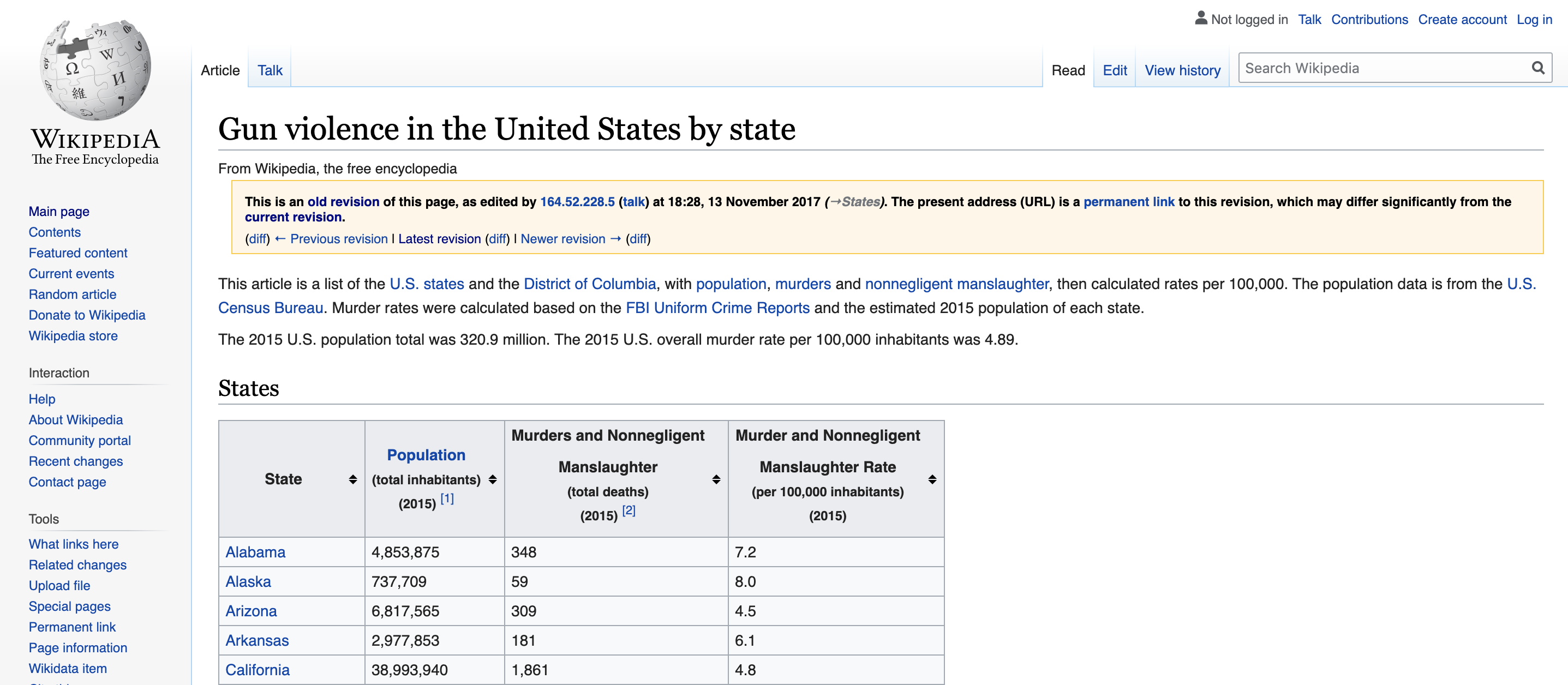
(Página web cortesía de Wikipedia88. Licencia CC-BY-SA-3.0)89.
Desafortunadamente, no hay un enlace a un archivo de datos. Para crear el data frame que se carga cuando escribimos data(murders), tuvimos que hacer un poco de extracción de la web (web scraping o web harvesting en inglés).
Extracción de la web es el término que se usa para describir el proceso de extracción de datos de un sitio web. La razón por la que podemos hacer esto es porque la información utilizada por un navegador para representar páginas web se recibe como un archivo de texto de un servidor. El texto es un código escrito en lenguaje de marcado de hipertexto (hyper text markup language o HTML por sus siglas en inglés). Todos los navegadores tienen una manera de mostrar el código HTML de una página, cada uno diferente. En Chrome, pueden usar Control-U en una PC y comando + alt + U en una Mac. Verán algo como esto:

23.1 HTML
Debido a que este código es accesible, podemos descargar el archivo HTML, importarlo a R y luego escribir programas para extraer la información que necesitamos de la página. Sin embargo, al ver el código HTML, esto puede parecer una tarea desalentadora. Pero le mostraremos algunas herramientas convenientes para facilitar el proceso. Para tener una idea de cómo funciona, aquí hay unas líneas de código de la página de Wikipedia que proveen los datos de asesinatos en Estados Unidos:
<table class="wikitable sortable">
<tr>
<th>State</th>
<th><a href="/wiki/List_of_U.S._states_and_territories_by_population"
title="List of U.S. states and territories by population">Population</a><br/>
<small>(total inhabitants)</small><br/>
<small>(2015)</small> <sup id="cite_ref-1" class="reference">
<a href="#cite_note-1">[1]</a></sup></th>
<th>Murders and Nonnegligent
<p>Manslaughter<br/>
<small>(total deaths)</small><br/>
<small>(2015)</small> <sup id="cite_ref-2" class="reference">
<a href="#cite_note-2">[2]</a></sup></p>
</th>
<th>Murder and Nonnegligent
<p>Manslaughter Rate<br/>
<small>(per 100,000 inhabitants)</small><br/>
<small>(2015)</small></p>
</th>
</tr>
<tr>
<td><a href="/wiki/Alabama" title="Alabama">Alabama</a></td>
<td>4,853,875</td>
<td>348</td>
<td>7.2</td>
</tr>
<tr>
<td><a href="/wiki/Alaska" title="Alaska">Alaska</a></td>
<td>737,709</td>
<td>59</td>
<td>8.0</td>
</tr>
<tr>Pueden ver los datos, excepto que los valores de datos están rodeados por un código HTML como <td>. También podemos ver un patrón de cómo se almacenan. Si conocen HTML, pueden escribir programas que aprovechan el conocimiento de estos patrones para extraer lo que queremos. Además, nos aprovechamos de Cascading Style Sheets (CSS), un lenguaje ampliamente utilizado para hacer que las páginas web se vean “bonitas”. Discutimos más sobre esto en la Sección 23.3.
Aunque ofrecemos herramientas que permiten extraer datos sin conocer HTML, como científicos de datos es bastante útil aprender algo de HTML y CSS. Esto no solo mejora sus habilidades de extracción, sino que puede ser útil si están creando una página web para exhibir su trabajo. Hay muchos cursos y tutoriales en línea para aprenderlos, como Codeacademy90 y W3schools91.
23.2 El paquete rvest
El tidyverse provee un paquete de extracción de la web llamado rvest. El primer paso para usar este paquete es importar la página web a R. El paquete lo hace bastante fácil:
library(tidyverse)
library(rvest)
h <- read_html(url)Tengan en cuenta que la página entera de Wikipedia Gun violence in the United States ahora está contenida en h. La clase de este objeto es:
class(h)
#> [1] "xml_document" "xml_node"El paquete rvest es más general; maneja documentos XML. XML es un lenguaje de marcado general (ML siendo las iniciales de markup language) que se puede usar para representar cualquier tipo de datos. HTML es un tipo específico de XML desarrollado específicamente para representar páginas web. Aquí nos concentramos en documentos HTML.
Ahora, ¿cómo extraemos la tabla del objeto h? Si imprimimos h, realmente no vemos mucho:
h
#> {html_document}
#> <html class="client-nojs" lang="en" dir="ltr">
#> [1] <head>\n<meta http-equiv="Content-Type" content="text/html; chars ...
#> [2] <body class="skin-vector-legacy mediawiki ltr sitedir-ltr mw-hide ...Podemos ver todo el código que define la página web descargada usando la función html_text así:
html_text(h)No mostramos el output aquí porque incluye miles de caracteres, pero si lo miramos, podemos ver que los datos que buscamos se almacenan en una tabla HTML. Pueden ver esto en esta línea del código HTML anterior: <table class="wikitable sortable">. Las diferentes partes de un documento HTML, a menudo definidas con un mensaje entre < y >, se conocen como nodos (nodes en inglés). El paquete rvest incluye funciones para extraer nodos de un documento HTML: html_nodes extrae todos los nodos de diferentes tipos y html_node extrae el primero. Para extraer las tablas del código HTML usamos:
tab <- h |> html_nodes("table")Ahora, en lugar de toda la página web, solo tenemos el código HTML para las tablas de la página:
tab
#> {xml_nodeset (2)}
#> [1] <table class="wikitable sortable"><tbody>\n<tr>\n<th>State\n</th> ...
#> [2] <table class="nowraplinks hlist mw-collapsible mw-collapsed navbo ...La tabla que nos interesa es la primera:
tab[[1]]
#> {html_node}
#> <table class="wikitable sortable">
#> [1] <tbody>\n<tr>\n<th>State\n</th>\n<th>\n<a href="/wiki/List_of_U.S ...Esto claramente no es un set de datos tidy, ni siquiera un data frame. En el código anterior, podemos ver un patrón y es muy factible escribir código para extraer solo los datos. De hecho, rvest incluye una función solo para convertir tablas HTML en data frames:
tab <- tab[[1]] |> html_table()
class(tab)
#> [1] "tbl_df" "tbl" "data.frame"Ahora estamos mucho más cerca de tener una tabla de datos utilizables:
tab <- tab |> setNames(c("state", "population", "total", "murder_rate"))
head(tab)
#> # A tibble: 6 × 4
#> state population total murder_rate
#> <chr> <chr> <chr> <dbl>
#> 1 Alabama 4,853,875 348 7.2
#> 2 Alaska 737,709 59 8
#> 3 Arizona 6,817,565 309 4.5
#> 4 Arkansas 2,977,853 181 6.1
#> 5 California 38,993,940 1,861 4.8
#> # … with 1 more rowTodavía tenemos que hacer un poco de wrangling. Por ejemplo, necesitamos eliminar las comas y convertir los caracteres en números. Antes de continuar con esto, aprenderemos un acercamiento más general para extraer información de sitios web.
23.3 Selectores CSS
El aspecto por defecto de una página web hecha con el HTML más básico es poco atractivo. Las páginas estéticamente agradables que vemos hoy usan CSS para definir su aspecto y estilo. El hecho de que todas las páginas de una empresa tienen el mismo estilo generalmente resulta del uso del mismo archivo CSS para definir el estilo. La forma general en que funcionan estos archivos CSS es determinando cómo se verá cada uno de los elementos de una página web. El título, los encabezados, las listas detalladas, las tablas y los enlaces, por ejemplo, reciben cada uno su propio estilo, que incluye la fuente, el color, el tamaño y la distancia del margen. CSS hace esto aprovechando los patrones utilizados para definir estos elementos, denominados selectores. Un ejemplo de dicho patrón, que utilizamos anteriormente, es table, pero hay muchos más.
Si queremos obtener datos de una página web y conocemos un selector que es único para la parte de la página que contiene estos datos, podemos usar la función html_nodes. Sin embargo, saber qué selector puede ser bastante complicado.
De hecho, la complejidad de las páginas web ha aumentado a medida que se vuelven más sofisticadas. Para algunas de las más avanzadas, parece casi imposible encontrar los nodos que definen un dato en particular. Sin embargo, SelectorGadget lo hace posible.
SelectorGadget92 es un software que les permite determinar de manera interactiva qué selector CSS necesita para extraer componentes específicos de la página web. Si van a extraer datos que no son tablas de páginas HTML, les recomendamos que lo instalen. Chrome tiene una extensión que les permite encender el gadget y luego, al hacer clic en la página, resalta partes y les muestra el selector que necesitan para extraer estas partes. Hay varias demostraciones de cómo hacer esto, incluyendo este artículo de rvest93 y otros tutoriales basados en esa vignette94 95.
23.4 JSON
Compartir datos en Internet se ha vuelto cada vez más común. Desafortunadamente, los proveedores usan diferentes formatos, lo que añade dificultad para los científicos de datos reorganizar los datos en R. Sin embargo, hay algunos estándares que también se están volviendo más comunes. Actualmente, un formato que se está adoptando ampliamente es la Notación de Objetos JavaScript (JavaScript Object Notation o JSON por sus siglas en inglés). Debido a que este formato es muy general, no se parece en nada a una hoja de cálculo. Este archivo JSON se parece más al código que usamos para definir una lista. Aquí un ejemplo de información almacenada en formato JSON:
#> [
#> {
#> "name": "Miguel",
#> "student_id": 1,
#> "exam_1": 85,
#> "exam_2": 86
#> },
#> {
#> "name": "Sofia",
#> "student_id": 2,
#> "exam_1": 94,
#> "exam_2": 93
#> },
#> {
#> "name": "Aya",
#> "student_id": 3,
#> "exam_1": 87,
#> "exam_2": 88
#> },
#> {
#> "name": "Cheng",
#> "student_id": 4,
#> "exam_1": 90,
#> "exam_2": 91
#> }
#> ]El archivo anterior representa un data frame. Para leerlo, podemos usar la función fromJSON del paquete jsonlite. Noten que los archivos JSON a menudo están disponibles a través de Internet. Varias organizaciones proveen una API JSON o un servicio web al que pueden conectarse directamente y obtener datos. Aquí un ejemplo:
library(jsonlite)
citi_bike <- fromJSON("http://citibikenyc.com/stations/json")Esto descarga una lista. El primer argumento les dice cuando lo descargaron:
citi_bike$executionTimey el segundo es una tabla de datos:
citi_bike$stationBeanList |> as_tibble()Pueden aprender mucho más examinando tutoriales y archivos de ayuda del paquete jsonlite. Este paquete está destinado a tareas relativamente sencillas, como convertir datos en tablas. Para mayor flexibilidad, recomendamos rjson.
23.5 Ejercicios
1. Visite la siguiente página web:
https://web.archive.org/web/20181024132313/http://www.stevetheump.com/Payrolls.htm
Observe que hay varias tablas. Digamos que estamos interesados en comparar las nóminas de los equipos a lo largo de los años. Los siguientes ejercicios nos lleva por lo pasos necesarios para hacer esto.
Comience aplicando lo que aprendió e importe el sitio web a un objeto llamado h.
2. Tenga en cuenta que, aunque no es muy útil, podemos ver el contenido de la página escribiendo:
html_text(h)El siguiente paso es extraer las tablas. Para esto, podemos usar la función html_nodes. Aprendimos que las tablas en HTML están asociadas con el nodo table. Utilice la función html_nodes y el nodo table para extraer la primera tabla. Almacénela en un objeto nodes.
3. La función html_nodes devuelve una lista de objetos de clase xml_node. Podemos ver el contenido de cada uno usando, por ejemplo, la función html_text. Puede ver el contenido de un componente elegido arbitrariamente así:
html_text(nodes[[8]])Si el contenido de este objeto es una tabla HTML, podemos usar la función html_table para convertirlo en un data frame. Utilice la función html_table para convertir la octava entrada de nodes en una tabla.
4. Repita lo anterior para los primeros 4 componentes de nodes. ¿Cuáles de las siguientes son tablas de cálculo de nómina?
- Todas.
- 1
- 2
- 2-4
5. Repita lo anterior para los 3 últimos componentes de nodes. ¿Cuál de los siguientes es cierto?
- La última entrada en
nodesmuestra el promedio de todos los equipos a lo largo del tiempo, no la nómina por equipo. - Las tres son tablas de cálculo de nómina por equipo.
- Las tres son como la primera entrada, no una tabla de cálculo de nómina.
- Todas las anteriores.
6. Hemos aprendido que la primera y la última entrada de nodes no son tablas de cálculo de nómina. Redefina nodes para que estas dos se eliminen.
7. Vimos en el análisis anterior que el primer nodo de la tabla realmente no es una tabla. Esto sucede a veces en HTML porque las tablas se usan para hacer que el texto se vea de cierta manera, en lugar de almacenar valores numéricos. Elimine el primer componente y luego use sapply y html_table para convertir cada nodo en nodes en una tabla. Tenga en cuenta que en este caso sapply devolverá una lista de tablas. También puede usar lapply para asegurar que se aplique una lista.
8. Mire las tablas resultantes. ¿Son todas iguales? ¿Podríamos unirlas con bind_rows?
9. Cree dos tablas utilizando las entradas 10 y 19. Llámelas tab_1 y tab_2.
10. Utilice una función full_join para combinar estas dos tablas. Antes de hacer esto, corrija el problema del encabezado que falta y haga que los nombres coincidan.
11. Después de unir las tablas, verá varias NAs. Esto se debe a que algunos equipos están en una tabla y no en la otra. Utilice la función anti_join para tener una mejor idea de por qué sucede esto.
12. Vemos que uno de los problemas es que los Yankees figuran como N.Y. Yankees y NY Yankees. En la siguiente sección, aprenderemos enfoques eficientes para solucionar problemas como este. Aquí podemos hacerlo “a mano” de la siguiente manera:
tab_1 <- tab_1 |>
mutate(Team = ifelse(Team == "N.Y. Yankees", "NY Yankees", Team))Ahora una las tablas y muestre solo Oakland y los Yankees y las columnas de cálculo de nómina.
13. Avanzado: Extraiga los títulos de las películas que ganaron el premio de Best Picture de este sitio web: https://m.imdb.com/chart/bestpicture/
https://en.wikipedia.org/w/index.php?title=Gun_violence_in_the_United_States_by_state&direction=prev&oldid=810166167↩︎
https://en.wikipedia.org/wiki/Wikipedia:Text_of_Creative_Commons_Attribution-ShareAlike_3.0_Unported_License↩︎
https://stat4701.github.io/edav/2015/04/02/rvest_tutorial/↩︎
https://www.analyticsvidhya.com/blog/2017/03/beginners-guide-on-web-scraping-in-r-using-rvest-with-hands-on-knowledge/↩︎